 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOdysseyArena: Benchmarking Large Language Models For Long-Horizon, Active and Inductive Interactions
Feb 05, 2026The rapid advancement of Large Language Models (LLMs) has catalyzed the development of autonomous agents capable of navigating complex environments. However, existing evaluations primarily adopt a deductive paradigm, where agents execute tasks based on explicitly provided rules and static goals, often within limited planning horizons. Crucially, this neglects the inductive necessity for agents to discover latent transition laws from experience autonomously, which is the cornerstone for enabling agentic foresight and sustaining strategic coherence. To bridge this gap, we introduce OdysseyArena, which re-centers agent evaluation on long-horizon, active, and inductive interactions. We formalize and instantiate four primitives, translating abstract transition dynamics into concrete interactive environments. Building upon this, we establish OdysseyArena-Lite for standardized benchmarking, providing a set of 120 tasks to measure an agent's inductive efficiency and long-horizon discovery. Pushing further, we introduce OdysseyArena-Challenge to stress-test agent stability across extreme interaction horizons (e.g., > 200 steps). Extensive experiments on 15+ leading LLMs reveal that even frontier models exhibit a deficiency in inductive scenarios, identifying a critical bottleneck in the pursuit of autonomous discovery in complex environments. Our code and data are available at https://github.com/xufangzhi/Odyssey-Arena
CL-bench: A Benchmark for Context Learning
Feb 03, 2026Current language models (LMs) excel at reasoning over prompts using pre-trained knowledge. However, real-world tasks are far more complex and context-dependent: models must learn from task-specific context and leverage new knowledge beyond what is learned during pre-training to reason and resolve tasks. We term this capability context learning, a crucial ability that humans naturally possess but has been largely overlooked. To this end, we introduce CL-bench, a real-world benchmark consisting of 500 complex contexts, 1,899 tasks, and 31,607 verification rubrics, all crafted by experienced domain experts. Each task is designed such that the new content required to resolve it is contained within the corresponding context. Resolving tasks in CL-bench requires models to learn from the context, ranging from new domain-specific knowledge, rule systems, and complex procedures to laws derived from empirical data, all of which are absent from pre-training. This goes far beyond long-context tasks that primarily test retrieval or reading comprehension, and in-context learning tasks, where models learn simple task patterns via instructions and demonstrations. Our evaluations of ten frontier LMs find that models solve only 17.2% of tasks on average. Even the best-performing model, GPT-5.1, solves only 23.7%, revealing that LMs have yet to achieve effective context learning, which poses a critical bottleneck for tackling real-world, complex context-dependent tasks. CL-bench represents a step towards building LMs with this fundamental capability, making them more intelligent and advancing their deployment in real-world scenarios.
OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
Jan 04, 2026Evaluating novelty is critical yet challenging in peer review, as reviewers must assess submissions against a vast, rapidly evolving literature. This report presents OpenNovelty, an LLM-powered agentic system for transparent, evidence-based novelty analysis. The system operates through four phases: (1) extracting the core task and contribution claims to generate retrieval queries; (2) retrieving relevant prior work based on extracted queries via semantic search engine; (3) constructing a hierarchical taxonomy of core-task-related work and performing contribution-level full-text comparisons against each contribution; and (4) synthesizing all analyses into a structured novelty report with explicit citations and evidence snippets. Unlike naive LLM-based approaches, \textsc{OpenNovelty} grounds all assessments in retrieved real papers, ensuring verifiable judgments. We deploy our system on 500+ ICLR 2026 submissions with all reports publicly available on our website, and preliminary analysis suggests it can identify relevant prior work, including closely related papers that authors may overlook. OpenNovelty aims to empower the research community with a scalable tool that promotes fair, consistent, and evidence-backed peer review.
RLoop: An Self-Improving Framework for Reinforcement Learning with Iterative Policy Initialization
Nov 06, 2025



While Reinforcement Learning for Verifiable Rewards (RLVR) is powerful for training large reasoning models, its training dynamics harbor a critical challenge: RL overfitting, where models gain training rewards but lose generalization. Our analysis reveals this is driven by policy over-specialization and catastrophic forgetting of diverse solutions generated during training. Standard optimization discards this valuable inter-step policy diversity. To address this, we introduce RLoop, a self-improving framework built on iterative policy initialization. RLoop transforms the standard training process into a virtuous cycle: it first uses RL to explore the solution space from a given policy, then filters the successful trajectories to create an expert dataset. This dataset is used via Rejection-sampling Fine-Tuning (RFT) to refine the initial policy, creating a superior starting point for the next iteration. This loop of exploration and exploitation via iterative re-initialization effectively converts transient policy variations into robust performance gains. Our experiments show RLoop mitigates forgetting and substantially improves generalization, boosting average accuracy by 9% and pass@32 by over 15% compared to vanilla RL.
Dynamic and Generalizable Process Reward Modeling
Jul 23, 2025Process Reward Models (PRMs) are crucial for guiding Large Language Models (LLMs) in complex scenarios by providing dense reward signals. However, existing PRMs primarily rely on heuristic approaches, which struggle with cross-domain generalization. While LLM-as-judge has been proposed to provide generalized rewards, current research has focused mainly on feedback results, overlooking the meaningful guidance embedded within the text. Additionally, static and coarse-grained evaluation criteria struggle to adapt to complex process supervision. To tackle these challenges, we propose Dynamic and Generalizable Process Reward Modeling (DG-PRM), which features a reward tree to capture and store fine-grained, multi-dimensional reward criteria. DG-PRM dynamically selects reward signals for step-wise reward scoring. To handle multifaceted reward signals, we pioneeringly adopt Pareto dominance estimation to identify discriminative positive and negative pairs. Experimental results show that DG-PRM achieves stunning performance on prevailing benchmarks, significantly boosting model performance across tasks with dense rewards. Further analysis reveals that DG-PRM adapts well to out-of-distribution scenarios, demonstrating exceptional generalizability.
R3-RAG: Learning Step-by-Step Reasoning and Retrieval for LLMs via Reinforcement Learning
May 26, 2025



Retrieval-Augmented Generation (RAG) integrates external knowledge with Large Language Models (LLMs) to enhance factual correctness and mitigate hallucination. However, dense retrievers often become the bottleneck of RAG systems due to their limited parameters compared to LLMs and their inability to perform step-by-step reasoning. While prompt-based iterative RAG attempts to address these limitations, it is constrained by human-designed workflows. To address these limitations, we propose $\textbf{R3-RAG}$, which uses $\textbf{R}$einforcement learning to make the LLM learn how to $\textbf{R}$eason and $\textbf{R}$etrieve step by step, thus retrieving comprehensive external knowledge and leading to correct answers. R3-RAG is divided into two stages. We first use cold start to make the model learn the manner of iteratively interleaving reasoning and retrieval. Then we use reinforcement learning to further harness its ability to better explore the external retrieval environment. Specifically, we propose two rewards for R3-RAG: 1) answer correctness for outcome reward, which judges whether the trajectory leads to a correct answer; 2) relevance-based document verification for process reward, encouraging the model to retrieve documents that are relevant to the user question, through which we can let the model learn how to iteratively reason and retrieve relevant documents to get the correct answer. Experimental results show that R3-RAG significantly outperforms baselines and can transfer well to different retrievers. We release R3-RAG at https://github.com/Yuan-Li-FNLP/R3-RAG.
ScienceBoard: Evaluating Multimodal Autonomous Agents in Realistic Scientific Workflows
May 26, 2025



Large Language Models (LLMs) have extended their impact beyond Natural Language Processing, substantially fostering the development of interdisciplinary research. Recently, various LLM-based agents have been developed to assist scientific discovery progress across multiple aspects and domains. Among these, computer-using agents, capable of interacting with operating systems as humans do, are paving the way to automated scientific problem-solving and addressing routines in researchers' workflows. Recognizing the transformative potential of these agents, we introduce ScienceBoard, which encompasses two complementary contributions: (i) a realistic, multi-domain environment featuring dynamic and visually rich scientific workflows with integrated professional software, where agents can autonomously interact via different interfaces to accelerate complex research tasks and experiments; and (ii) a challenging benchmark of 169 high-quality, rigorously validated real-world tasks curated by humans, spanning scientific-discovery workflows in domains such as biochemistry, astronomy, and geoinformatics. Extensive evaluations of agents with state-of-the-art backbones (e.g., GPT-4o, Claude 3.7, UI-TARS) show that, despite some promising results, they still fall short of reliably assisting scientists in complex workflows, achieving only a 15% overall success rate. In-depth analysis further provides valuable insights for addressing current agent limitations and more effective design principles, paving the way to build more capable agents for scientific discovery. Our code, environment, and benchmark are at https://qiushisun.github.io/ScienceBoard-Home/.
FamilyTool: A Multi-hop Personalized Tool Use Benchmark
Apr 09, 2025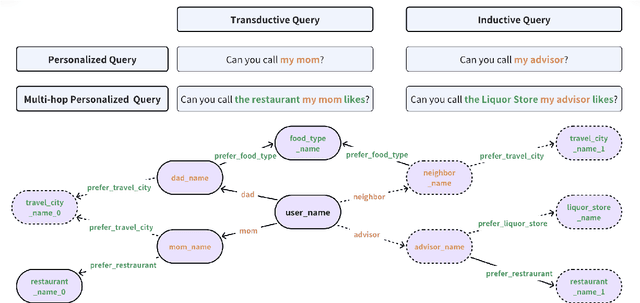

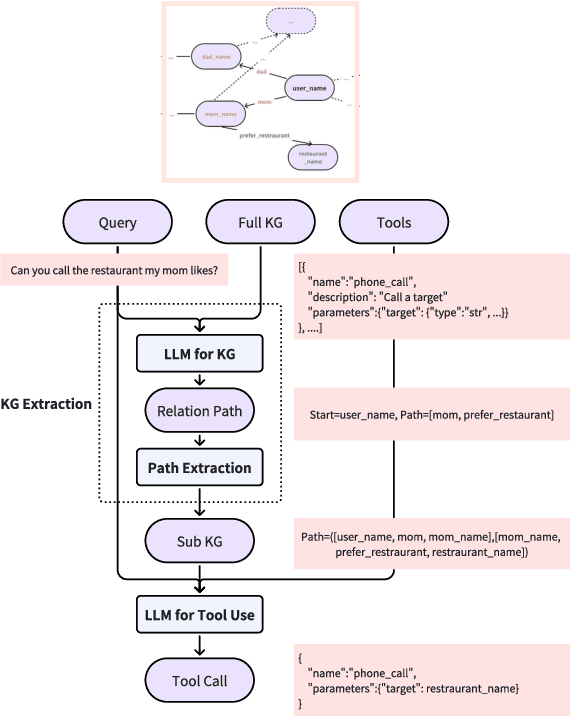

The integration of tool learning with Large Language Models (LLMs) has expanded their capabilities in handling complex tasks by leveraging external tools. However, existing benchmarks for tool learning inadequately address critical real-world personalized scenarios, particularly those requiring multi-hop reasoning and inductive knowledge adaptation in dynamic environments. To bridge this gap, we introduce FamilyTool, a novel benchmark grounded in a family-based knowledge graph (KG) that simulates personalized, multi-hop tool use scenarios. FamilyTool challenges LLMs with queries spanning 1 to 3 relational hops (e.g., inferring familial connections and preferences) and incorporates an inductive KG setting where models must adapt to unseen user preferences and relationships without re-training, a common limitation in prior approaches that compromises generalization. We further propose KGETool: a simple KG-augmented evaluation pipeline to systematically assess LLMs' tool use ability in these settings. Experiments reveal significant performance gaps in state-of-the-art LLMs, with accuracy dropping sharply as hop complexity increases and inductive scenarios exposing severe generalization deficits. These findings underscore the limitations of current LLMs in handling personalized, evolving real-world contexts and highlight the urgent need for advancements in tool-learning frameworks. FamilyTool serves as a critical resource for evaluating and advancing LLM agents' reasoning, adaptability, and scalability in complex, dynamic environments. Code and dataset are available at Github.
Revisiting the Test-Time Scaling of o1-like Models: Do they Truly Possess Test-Time Scaling Capabilities?
Feb 17, 2025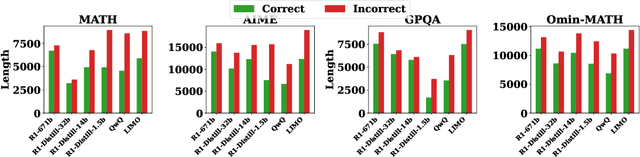

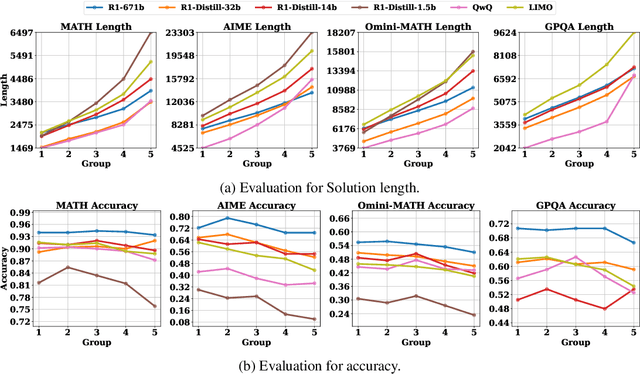
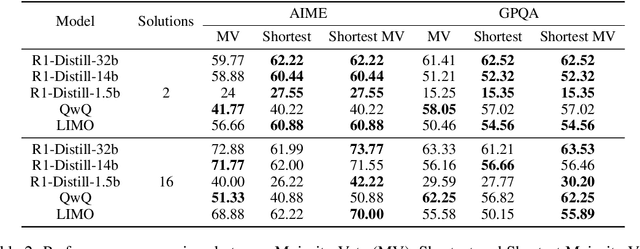
The advent of test-time scaling in large language models (LLMs), exemplified by OpenAI's o1 series, has advanced reasoning capabilities by scaling computational resource allocation during inference. While successors like QwQ, Deepseek-R1 (R1) and LIMO replicate these advancements, whether these models truly possess test-time scaling capabilities remains underexplored. This study found that longer CoTs of these o1-like models do not consistently enhance accuracy; in fact, correct solutions are often shorter than incorrect ones for the same questions. Further investigation shows this phenomenon is closely related to models' self-revision capabilities - longer CoTs contain more self-revisions, which often lead to performance degradation. We then compare sequential and parallel scaling strategies on QwQ, R1 and LIMO, finding that parallel scaling achieves better coverage and scalability. Based on these insights, we propose Shortest Majority Vote, a method that combines parallel scaling strategies with CoT length characteristics, significantly improving models' test-time scalability compared to conventional majority voting approaches.
Error Classification of Large Language Models on Math Word Problems: A Dynamically Adaptive Framework
Jan 26, 2025
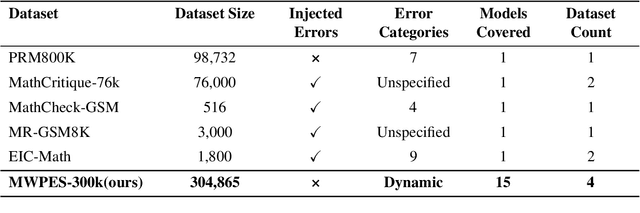

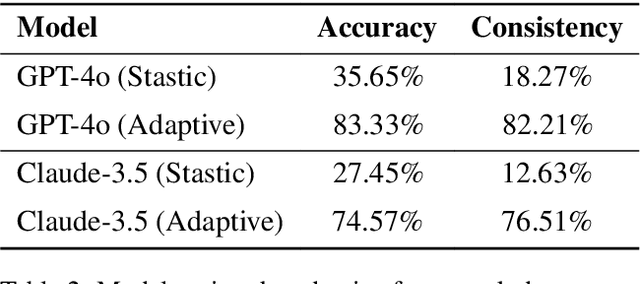
Large Language Models (LLMs) have demonstrated remarkable capabilities across various domains. Math Word Problems (MWPs) serve as a crucial benchmark for evaluating LLMs' reasoning abilities. While most research primarily focuses on improving accuracy, it often neglects understanding and addressing the underlying patterns of errors. Current error classification methods rely on static and predefined categories, which limit their ability to capture the full spectrum of error patterns in mathematical reasoning. To enable systematic error analysis, we collect error samples from 15 different LLMs of varying sizes across four distinct MWP datasets using multiple sampling strategies. Based on this extensive collection, we introduce MWPES-300K, a comprehensive dataset containing 304,865 error samples that cover diverse error patterns and reasoning paths. To reduce human bias and enable fine-grained analysis of error patterns, we propose a novel framework for automated dynamic error classification in mathematical reasoning. Experimental results demonstrate that dataset characteristics significantly shape error patterns, which evolve from basic to complex manifestations as model capabilities increase. With deeper insights into error patterns, we propose error-aware prompting that incorporates common error patterns as explicit guidance, leading to significant improvements in mathematical reasoning performance.