 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
Digital Player: Evaluating Large Language Models based Human-like Agent in Games
Feb 28, 2025With the rapid advancement of Large Language Models (LLMs), LLM-based autonomous agents have shown the potential to function as digital employees, such as digital analysts, teachers, and programmers. In this paper, we develop an application-level testbed based on the open-source strategy game "Unciv", which has millions of active players, to enable researchers to build a "data flywheel" for studying human-like agents in the "digital players" task. This "Civilization"-like game features expansive decision-making spaces along with rich linguistic interactions such as diplomatic negotiations and acts of deception, posing significant challenges for LLM-based agents in terms of numerical reasoning and long-term planning. Another challenge for "digital players" is to generate human-like responses for social interaction, collaboration, and negotiation with human players. The open-source project can be found at https:/github.com/fuxiAIlab/CivAgent.
Structure-aware Fine-tuning for Code Pre-trained Models
Apr 11, 2024
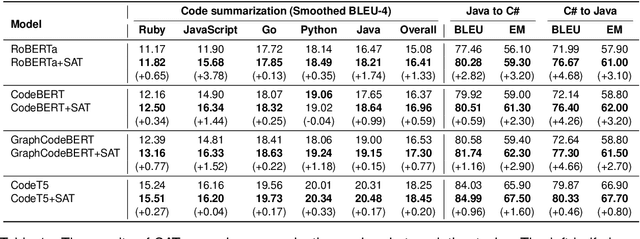

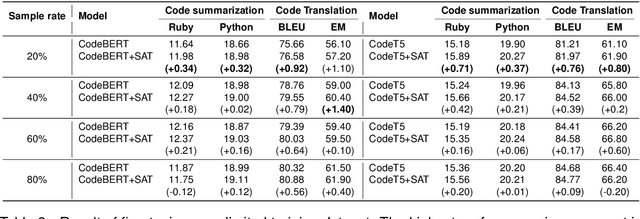
Over the past few years, we have witnessed remarkable advancements in Code Pre-trained Models (CodePTMs). These models achieved excellent representation capabilities by designing structure-based pre-training tasks for code. However, how to enhance the absorption of structural knowledge when fine-tuning CodePTMs still remains a significant challenge. To fill this gap, in this paper, we present Structure-aware Fine-tuning (SAT), a novel structure-enhanced and plug-and-play fine-tuning method for CodePTMs. We first propose a structure loss to quantify the difference between the information learned by CodePTMs and the knowledge extracted from code structure. Specifically, we use the attention scores extracted from Transformer layer as the learned structural information, and the shortest path length between leaves in abstract syntax trees as the structural knowledge. Subsequently, multi-task learning is introduced to improve the performance of fine-tuning. Experiments conducted on four pre-trained models and two generation tasks demonstrate the effectiveness of our proposed method as a plug-and-play solution. Furthermore, we observed that SAT can benefit CodePTMs more with limited training data.
A Survey of Neural Code Intelligence: Paradigms, Advances and Beyond
Mar 21, 2024Neural Code Intelligence -- leveraging deep learning to understand, generate, and optimize code -- holds immense potential for transformative impacts on the whole society. Bridging the gap between Natural Language and Programming Language, this domain has drawn significant attention from researchers in both research communities over the past few years. This survey presents a systematic and chronological review of the advancements in code intelligence, encompassing over 50 representative models and their variants, more than 20 categories of tasks, and an extensive coverage of over 680 related works. We follow the historical progression to trace the paradigm shifts across different research phases (e.g., from modeling code with recurrent neural networks to the era of Large Language Models). Concurrently, we highlight the major technical transitions in models, tasks, and evaluations spanning through different stages. For applications, we also observe a co-evolving shift. It spans from initial endeavors to tackling specific scenarios, through exploring a diverse array of tasks during its rapid expansion, to currently focusing on tackling increasingly complex and varied real-world challenges. Building on our examination of the developmental trajectories, we further investigate the emerging synergies between code intelligence and broader machine intelligence, uncovering new cross-domain opportunities and illustrating the substantial influence of code intelligence across various domains. Finally, we delve into both the opportunities and challenges associated with this field, alongside elucidating our insights on the most promising research directions. An ongoing, dynamically updated project and resources associated with this survey have been released at https://github.com/QiushiSun/NCISurvey.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024



For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
Towards Long-term Annotators: A Supervised Label Aggregation Baseline
Nov 15, 2023



Relying on crowdsourced workers, data crowdsourcing platforms are able to efficiently provide vast amounts of labeled data. Due to the variability in the annotation quality of crowd workers, modern techniques resort to redundant annotations and subsequent label aggregation to infer true labels. However, these methods require model updating during the inference, posing challenges in real-world implementation. Meanwhile, in recent years, many data labeling tasks have begun to require skilled and experienced annotators, leading to an increasing demand for long-term annotators. These annotators could leave substantial historical annotation records on the crowdsourcing platforms, which can benefit label aggregation, but are ignored by previous works. Hereby, in this paper, we propose a novel label aggregation technique, which does not need any model updating during inference and can extensively explore the historical annotation records. We call it SuperLA, a Supervised Label Aggregation method. Inside this model, we design three types of input features and a straightforward neural network structure to merge all the information together and subsequently produce aggregated labels. Based on comparison experiments conducted on 22 public datasets and 11 baseline methods, we find that SuperLA not only outperforms all those baselines in inference performance but also offers significant advantages in terms of efficiency.
Exchanging-based Multimodal Fusion with Transformer
Sep 05, 2023



We study the problem of multimodal fusion in this paper. Recent exchanging-based methods have been proposed for vision-vision fusion, which aim to exchange embeddings learned from one modality to the other. However, most of them project inputs of multimodalities into different low-dimensional spaces and cannot be applied to the sequential input data. To solve these issues, in this paper, we propose a novel exchanging-based multimodal fusion model MuSE for text-vision fusion based on Transformer. We first use two encoders to separately map multimodal inputs into different low-dimensional spaces. Then we employ two decoders to regularize the embeddings and pull them into the same space. The two decoders capture the correlations between texts and images with the image captioning task and the text-to-image generation task, respectively. Further, based on the regularized embeddings, we present CrossTransformer, which uses two Transformer encoders with shared parameters as the backbone model to exchange knowledge between multimodalities. Specifically, CrossTransformer first learns the global contextual information of the inputs in the shallow layers. After that, it performs inter-modal exchange by selecting a proportion of tokens in one modality and replacing their embeddings with the average of embeddings in the other modality. We conduct extensive experiments to evaluate the performance of MuSE on the Multimodal Named Entity Recognition task and the Multimodal Sentiment Analysis task. Our results show the superiority of MuSE against other competitors. Our code and data are provided at https://github.com/RecklessRonan/MuSE.
Rethinking Noisy Label Learning in Real-world Annotation Scenarios from the Noise-type Perspective
Jul 28, 2023We investigate the problem of learning with noisy labels in real-world annotation scenarios, where noise can be categorized into two types: factual noise and ambiguity noise. To better distinguish these noise types and utilize their semantics, we propose a novel sample selection-based approach for noisy label learning, called Proto-semi. Proto-semi initially divides all samples into the confident and unconfident datasets via warm-up. By leveraging the confident dataset, prototype vectors are constructed to capture class characteristics. Subsequently, the distances between the unconfident samples and the prototype vectors are calculated to facilitate noise classification. Based on these distances, the labels are either corrected or retained, resulting in the refinement of the confident and unconfident datasets. Finally, we introduce a semi-supervised learning method to enhance training. Empirical evaluations on a real-world annotated dataset substantiate the robustness of Proto-semi in handling the problem of learning from noisy labels. Meanwhile, the prototype-based repartitioning strategy is shown to be effective in mitigating the adverse impact of label noise. Our code and data are available at https://github.com/fuxiAIlab/ProtoSemi.
When Gradient Descent Meets Derivative-Free Optimization: A Match Made in Black-Box Scenario
May 17, 2023Large pre-trained language models (PLMs) have garnered significant attention for their versatility and potential for solving a wide spectrum of natural language processing (NLP) tasks. However, the cost of running these PLMs may be prohibitive. Furthermore, PLMs may not be open-sourced due to commercial considerations and potential risks of misuse, such as GPT-3. The parameters and gradients of PLMs are unavailable in this scenario. To solve the issue, black-box tuning has been proposed, which utilizes derivative-free optimization (DFO), instead of gradient descent, for training task-specific continuous prompts. However, these gradient-free methods still exhibit a significant gap compared to gradient-based methods. In this paper, we introduce gradient descent into black-box tuning scenario through knowledge distillation. Furthermore, we propose a novel method GDFO, which integrates gradient descent and derivative-free optimization to optimize task-specific continuous prompts in a harmonized manner. Experimental results show that GDFO can achieve significant performance gains over previous state-of-the-art methods.
Make Prompt-based Black-Box Tuning Colorful: Boosting Model Generalization from Three Orthogonal Perspectives
May 14, 2023Large language models (LLMs) have shown increasing power on various natural language processing (NLP) tasks. However, tuning these models for downstream tasks usually needs exorbitant costs or is unavailable due to commercial considerations. Recently, black-box tuning has been proposed to address this problem by optimizing task-specific prompts without accessing the gradients and hidden representations. However, most existing works have yet fully exploited the potential of gradient-free optimization under the scenario of few-shot learning. In this paper, we describe BBT-RGB, a suite of straightforward and complementary techniques for enhancing the efficiency and performance of black-box optimization. Specifically, our method includes three plug-and-play components: (1) Two-stage derivative-free optimization strategy that facilitates fast convergence and mitigates overfitting; (2) Automatic verbalizer construction with its novel usage under few-shot settings; (3) Better prompt initialization policy based on instruction search and auto-selected demonstration. Extensive experiments across various tasks on natural language understanding and inference demonstrate the effectiveness of our method. Our codes are publicly available at https://github.com/QiushiSun/BBT-RGB.