 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCrowdAgent: Multi-Agent Managed Multi-Source Annotation System
Sep 17, 2025High-quality annotated data is a cornerstone of modern Natural Language Processing (NLP). While recent methods begin to leverage diverse annotation sources-including Large Language Models (LLMs), Small Language Models (SLMs), and human experts-they often focus narrowly on the labeling step itself. A critical gap remains in the holistic process control required to manage these sources dynamically, addressing complex scheduling and quality-cost trade-offs in a unified manner. Inspired by real-world crowdsourcing companies, we introduce CrowdAgent, a multi-agent system that provides end-to-end process control by integrating task assignment, data annotation, and quality/cost management. It implements a novel methodology that rationally assigns tasks, enabling LLMs, SLMs, and human experts to advance synergistically in a collaborative annotation workflow. We demonstrate the effectiveness of CrowdAgent through extensive experiments on six diverse multimodal classification tasks. The source code and video demo are available at https://github.com/QMMMS/CrowdAgent.
Rank Aggregation in Crowdsourcing for Listwise Annotations
Oct 10, 2024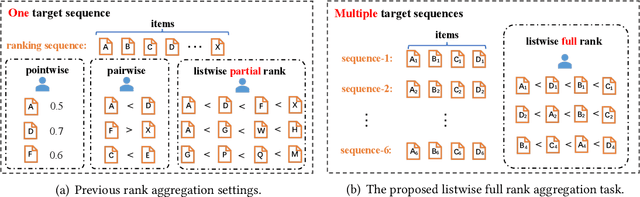



Rank aggregation through crowdsourcing has recently gained significant attention, particularly in the context of listwise ranking annotations. However, existing methods primarily focus on a single problem and partial ranks, while the aggregation of listwise full ranks across numerous problems remains largely unexplored. This scenario finds relevance in various applications, such as model quality assessment and reinforcement learning with human feedback. In light of practical needs, we propose LAC, a Listwise rank Aggregation method in Crowdsourcing, where the global position information is carefully measured and included. In our design, an especially proposed annotation quality indicator is employed to measure the discrepancy between the annotated rank and the true rank. We also take the difficulty of the ranking problem itself into consideration, as it directly impacts the performance of annotators and consequently influences the final results. To our knowledge, LAC is the first work to directly deal with the full rank aggregation problem in listwise crowdsourcing, and simultaneously infer the difficulty of problems, the ability of annotators, and the ground-truth ranks in an unsupervised way. To evaluate our method, we collect a real-world business-oriented dataset for paragraph ranking. Experimental results on both synthetic and real-world benchmark datasets demonstrate the effectiveness of our proposed LAC method.
A Dataset for the Validation of Truth Inference Algorithms Suitable for Online Deployment
Mar 10, 2024



For the purpose of efficient and cost-effective large-scale data labeling, crowdsourcing is increasingly being utilized. To guarantee the quality of data labeling, multiple annotations need to be collected for each data sample, and truth inference algorithms have been developed to accurately infer the true labels. Despite previous studies having released public datasets to evaluate the efficacy of truth inference algorithms, these have typically focused on a single type of crowdsourcing task and neglected the temporal information associated with workers' annotation activities. These limitations significantly restrict the practical applicability of these algorithms, particularly in the context of long-term and online truth inference. In this paper, we introduce a substantial crowdsourcing annotation dataset collected from a real-world crowdsourcing platform. This dataset comprises approximately two thousand workers, one million tasks, and six million annotations. The data was gathered over a period of approximately six months from various types of tasks, and the timestamps of each annotation were preserved. We analyze the characteristics of the dataset from multiple perspectives and evaluate the effectiveness of several representative truth inference algorithms on this dataset. We anticipate that this dataset will stimulate future research on tracking workers' abilities over time in relation to different types of tasks, as well as enhancing online truth inference.
FreeAL: Towards Human-Free Active Learning in the Era of Large Language Models
Nov 27, 2023



Collecting high-quality labeled data for model training is notoriously time-consuming and labor-intensive for various NLP tasks. While copious solutions, such as active learning for small language models (SLMs) and prevalent in-context learning in the era of large language models (LLMs), have been proposed and alleviate the labeling burden to some extent, their performances are still subject to human intervention. It is still underexplored how to reduce the annotation cost in the LLMs era. To bridge this, we revolutionize traditional active learning and propose an innovative collaborative learning framework FreeAL to interactively distill and filter the task-specific knowledge from LLMs. During collaborative training, an LLM serves as an active annotator inculcating its coarse-grained knowledge, while a downstream SLM is incurred as a student to filter out high-quality in-context samples to feedback LLM for the subsequent label refinery. Extensive experiments on eight benchmark datasets demonstrate that FreeAL largely enhances the zero-shot performances for both SLM and LLM without any human supervision. The code is available at https://github.com/Justherozen/FreeAL .
Towards Long-term Annotators: A Supervised Label Aggregation Baseline
Nov 15, 2023



Relying on crowdsourced workers, data crowdsourcing platforms are able to efficiently provide vast amounts of labeled data. Due to the variability in the annotation quality of crowd workers, modern techniques resort to redundant annotations and subsequent label aggregation to infer true labels. However, these methods require model updating during the inference, posing challenges in real-world implementation. Meanwhile, in recent years, many data labeling tasks have begun to require skilled and experienced annotators, leading to an increasing demand for long-term annotators. These annotators could leave substantial historical annotation records on the crowdsourcing platforms, which can benefit label aggregation, but are ignored by previous works. Hereby, in this paper, we propose a novel label aggregation technique, which does not need any model updating during inference and can extensively explore the historical annotation records. We call it SuperLA, a Supervised Label Aggregation method. Inside this model, we design three types of input features and a straightforward neural network structure to merge all the information together and subsequently produce aggregated labels. Based on comparison experiments conducted on 22 public datasets and 11 baseline methods, we find that SuperLA not only outperforms all those baselines in inference performance but also offers significant advantages in terms of efficiency.
Rethinking Noisy Label Learning in Real-world Annotation Scenarios from the Noise-type Perspective
Jul 28, 2023We investigate the problem of learning with noisy labels in real-world annotation scenarios, where noise can be categorized into two types: factual noise and ambiguity noise. To better distinguish these noise types and utilize their semantics, we propose a novel sample selection-based approach for noisy label learning, called Proto-semi. Proto-semi initially divides all samples into the confident and unconfident datasets via warm-up. By leveraging the confident dataset, prototype vectors are constructed to capture class characteristics. Subsequently, the distances between the unconfident samples and the prototype vectors are calculated to facilitate noise classification. Based on these distances, the labels are either corrected or retained, resulting in the refinement of the confident and unconfident datasets. Finally, we introduce a semi-supervised learning method to enhance training. Empirical evaluations on a real-world annotated dataset substantiate the robustness of Proto-semi in handling the problem of learning from noisy labels. Meanwhile, the prototype-based repartitioning strategy is shown to be effective in mitigating the adverse impact of label noise. Our code and data are available at https://github.com/fuxiAIlab/ProtoSemi.