 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank Aggregation in Crowdsourcing for Listwise Annotations
Oct 10, 2024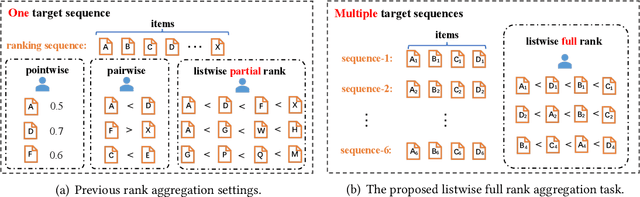



Rank aggregation through crowdsourcing has recently gained significant attention, particularly in the context of listwise ranking annotations. However, existing methods primarily focus on a single problem and partial ranks, while the aggregation of listwise full ranks across numerous problems remains largely unexplored. This scenario finds relevance in various applications, such as model quality assessment and reinforcement learning with human feedback. In light of practical needs, we propose LAC, a Listwise rank Aggregation method in Crowdsourcing, where the global position information is carefully measured and included. In our design, an especially proposed annotation quality indicator is employed to measure the discrepancy between the annotated rank and the true rank. We also take the difficulty of the ranking problem itself into consideration, as it directly impacts the performance of annotators and consequently influences the final results. To our knowledge, LAC is the first work to directly deal with the full rank aggregation problem in listwise crowdsourcing, and simultaneously infer the difficulty of problems, the ability of annotators, and the ground-truth ranks in an unsupervised way. To evaluate our method, we collect a real-world business-oriented dataset for paragraph ranking. Experimental results on both synthetic and real-world benchmark datasets demonstrate the effectiveness of our proposed LAC method.
Multi-class Label Noise Learning via Loss Decomposition and Centroid Estimation
Mar 21, 2022
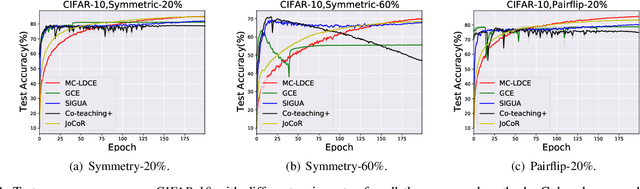
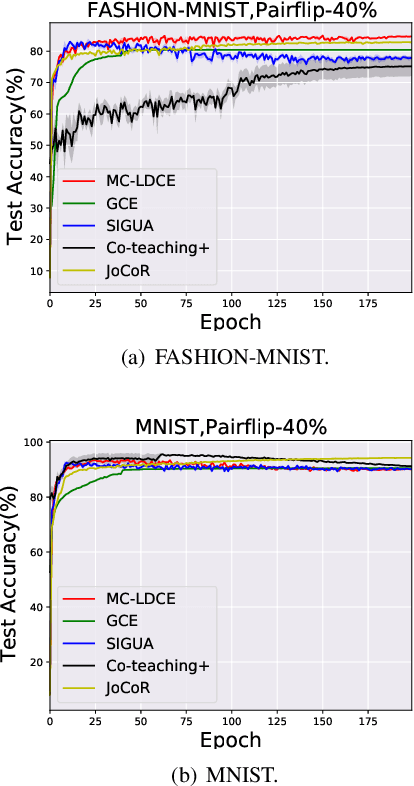

In real-world scenarios, many large-scale datasets often contain inaccurate labels, i.e., noisy labels, which may confuse model training and lead to performance degradation. To overcome this issue, Label Noise Learning (LNL) has recently attracted much attention, and various methods have been proposed to design an unbiased risk estimator to the noise-free dataset to combat such label noise. Among them, a trend of works based on Loss Decomposition and Centroid Estimation (LDCE) has shown very promising performance. However, existing LNL methods based on LDCE are only designed for binary classification, and they are not directly extendable to multi-class situations. In this paper, we propose a novel multi-class robust learning method for LDCE, which is termed "MC-LDCE". Specifically, we decompose the commonly adopted loss (e.g., mean squared loss) function into a label-dependent part and a label-independent part, in which only the former is influenced by label noise. Further, by defining a new form of data centroid, we transform the recovery problem of a label-dependent part to a centroid estimation problem. Finally, by critically examining the mathematical expectation of clean data centroid given the observed noisy set, the centroid can be estimated which helps to build an unbiased risk estimator for multi-class learning. The proposed MC-LDCE method is general and applicable to different types (i.e., linear and nonlinear) of classification models. The experimental results on five public datasets demonstrate the superiority of the proposed MC-LDCE against other representative LNL methods in tackling multi-class label noise problem.