 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRank Aggregation in Crowdsourcing for Listwise Annotations
Paper and Code
Oct 10, 2024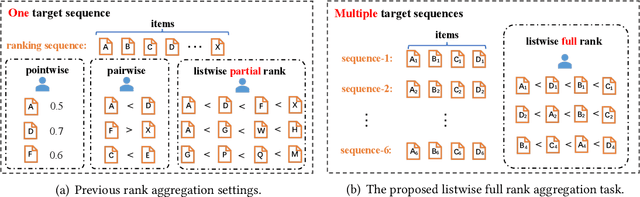



Rank aggregation through crowdsourcing has recently gained significant attention, particularly in the context of listwise ranking annotations. However, existing methods primarily focus on a single problem and partial ranks, while the aggregation of listwise full ranks across numerous problems remains largely unexplored. This scenario finds relevance in various applications, such as model quality assessment and reinforcement learning with human feedback. In light of practical needs, we propose LAC, a Listwise rank Aggregation method in Crowdsourcing, where the global position information is carefully measured and included. In our design, an especially proposed annotation quality indicator is employed to measure the discrepancy between the annotated rank and the true rank. We also take the difficulty of the ranking problem itself into consideration, as it directly impacts the performance of annotators and consequently influences the final results. To our knowledge, LAC is the first work to directly deal with the full rank aggregation problem in listwise crowdsourcing, and simultaneously infer the difficulty of problems, the ability of annotators, and the ground-truth ranks in an unsupervised way. To evaluate our method, we collect a real-world business-oriented dataset for paragraph ranking. Experimental results on both synthetic and real-world benchmark datasets demonstrate the effectiveness of our proposed LAC method.