 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRFM-Pose:Reinforcement-Guided Flow Matching for Fast Category-Level 6D Pose Estimation
Feb 05, 2026Object pose estimation is a fundamental problem in computer vision and plays a critical role in virtual reality and embodied intelligence, where agents must understand and interact with objects in 3D space. Recently, score based generative models have to some extent solved the rotational symmetry ambiguity problem in category level pose estimation, but their efficiency remains limited by the high sampling cost of score-based diffusion. In this work, we propose a new framework, RFM-Pose, that accelerates category-level 6D object pose generation while actively evaluating sampled hypotheses. To improve sampling efficiency, we adopt a flow-matching generative model and generate pose candidates along an optimal transport path from a simple prior to the pose distribution. To further refine these candidates, we cast the flow-matching sampling process as a Markov decision process and apply proximal policy optimization to fine-tune the sampling policy. In particular, we interpret the flow field as a learnable policy and map an estimator to a value network, enabling joint optimization of pose generation and hypothesis scoring within a reinforcement learning framework. Experiments on the REAL275 benchmark demonstrate that RFM-Pose achieves favorable performance while significantly reducing computational cost. Moreover, similar to prior work, our approach can be readily adapted to object pose tracking and attains competitive results in this setting.
Reasoning in a Combinatorial and Constrained World: Benchmarking LLMs on Natural-Language Combinatorial Optimization
Feb 02, 2026While large language models (LLMs) have shown strong performance in math and logic reasoning, their ability to handle combinatorial optimization (CO) -- searching high-dimensional solution spaces under hard constraints -- remains underexplored. To bridge the gap, we introduce NLCO, a \textbf{N}atural \textbf{L}anguage \textbf{C}ombinatorial \textbf{O}ptimization benchmark that evaluates LLMs on end-to-end CO reasoning: given a language-described decision-making scenario, the model must output a discrete solution without writing code or calling external solvers. NLCO covers 43 CO problems and is organized using a four-layer taxonomy of variable types, constraint families, global patterns, and objective classes, enabling fine-grained evaluation. We provide solver-annotated solutions and comprehensively evaluate LLMs by feasibility, solution optimality, and reasoning efficiency. Experiments across a wide range of modern LLMs show that high-performing models achieve strong feasibility and solution quality on small instances, but both degrade as instance size grows, even if more tokens are used for reasoning. We also observe systematic effects across the taxonomy: set-based tasks are relatively easy, whereas graph-structured problems and bottleneck objectives lead to more frequent failures.
From Pixels to Facts (Pix2Fact): Benchmarking Multi-Hop Reasoning for Fine-Grained Visual Fact Checking
Jan 31, 2026Despite progress on general tasks, VLMs struggle with challenges demanding both detailed visual grounding and deliberate knowledge-based reasoning, a synergy not captured by existing benchmarks that evaluate these skills separately. To close this gap, we introduce Pix2Fact, a new visual question-answering benchmark designed to evaluate expert-level perception and knowledge-intensive multi-hop reasoning. Pix2Fact contains 1,000 high-resolution (4K+) images spanning 8 daily-life scenarios and situations, with questions and answers meticulously crafted by annotators holding PhDs from top global universities working in partnership with a professional data annotation firm. Each question requires detailed visual grounding, multi-hop reasoning, and the integration of external knowledge to answer. Our evaluation of 9 state-of-the-art VLMs, including proprietary models like Gemini-3-Pro and GPT-5, reveals the substantial challenge posed by Pix2Fact: the most advanced model achieves only 24.0% average accuracy, in stark contrast to human performance of 56%. This significant gap underscores the limitations of current models in replicating human-level visual comprehension. We believe Pix2Fact will serve as a critical benchmark to drive the development of next-generation multimodal agents that combine fine-grained perception with robust, knowledge-based reasoning.
Divide-and-Conquer Decoupled Network for Cross-Domain Few-Shot Segmentation
Nov 11, 2025Cross-domain few-shot segmentation (CD-FSS) aims to tackle the dual challenge of recognizing novel classes and adapting to unseen domains with limited annotations. However, encoder features often entangle domain-relevant and category-relevant information, limiting both generalization and rapid adaptation to new domains. To address this issue, we propose a Divide-and-Conquer Decoupled Network (DCDNet). In the training stage, to tackle feature entanglement that impedes cross-domain generalization and rapid adaptation, we propose the Adversarial-Contrastive Feature Decomposition (ACFD) module. It decouples backbone features into category-relevant private and domain-relevant shared representations via contrastive learning and adversarial learning. Then, to mitigate the potential degradation caused by the disentanglement, the Matrix-Guided Dynamic Fusion (MGDF) module adaptively integrates base, shared, and private features under spatial guidance, maintaining structural coherence. In addition, in the fine-tuning stage, to enhanced model generalization, the Cross-Adaptive Modulation (CAM) module is placed before the MGDF, where shared features guide private features via modulation ensuring effective integration of domain-relevant information. Extensive experiments on four challenging datasets show that DCDNet outperforms existing CD-FSS methods, setting a new state-of-the-art for cross-domain generalization and few-shot adaptation.
Three-Stage Composite Outlier Identification of Wind Power Data: Integrating Physical Rules with Regression Learning and Mathematical Morphology
Apr 30, 2025



Existing studies on identifying outliers in wind speed-power datasets are often challenged by the complicated and irregular distributions of outliers, especially those being densely stacked yet staying close to normal data. This could degrade their identification reliability and robustness in practice. To address this defect, this paper develops a three-stage composite outlier identification method by systematically integrating three complementary techniques, i.e., physical rule-based preprocessing, regression learning-enabled detection, and mathematical morphology-based refinement. Firstly, the raw wind speed-power data are preprocessed via a set of simple yet efficient physical rules to filter out some outliers obviously going against the physical operating laws of practical wind turbines. Secondly, a robust wind speed-power regression learning model is built upon the random sample consensus algorithm. This model is able to reliably detect most outliers with the help of an adaptive threshold automatically set by the interquartile range method. Thirdly, by representing the wind speed-power data distribution with a two-dimensional image, mathematical morphology operations are applied to perform refined outlier identification from a data distribution perspective. This technique can identify outliers that are not effectively detected in the first two stages, including those densely stacked ones near normal data points. By integrating the above three techniques, the whole method is capable of identifying various types of outliers in a reliable and adaptive manner. Numerical test results with wind power datasets acquired from distinct wind turbines in practice and from simulation environments extensively demonstrate the superiority of the proposed method as well as its potential in enhancing wind power prediction.
VET: A Visual-Electronic Tactile System for Immersive Human-Machine Interaction
Apr 01, 2025In the pursuit of deeper immersion in human-machine interaction, achieving higher-dimensional tactile input and output on a single interface has become a key research focus. This study introduces the Visual-Electronic Tactile (VET) System, which builds upon vision-based tactile sensors (VBTS) and integrates electrical stimulation feedback to enable bidirectional tactile communication. We propose and implement a system framework that seamlessly integrates an electrical stimulation film with VBTS using a screen-printing preparation process, eliminating interference from traditional methods. While VBTS captures multi-dimensional input through visuotactile signals, electrical stimulation feedback directly stimulates neural pathways, preventing interference with visuotactile information. The potential of the VET system is demonstrated through experiments on finger electrical stimulation sensitivity zones, as well as applications in interactive gaming and robotic arm teleoperation. This system paves the way for new advancements in bidirectional tactile interaction and its broader applications.
DiffAD: A Unified Diffusion Modeling Approach for Autonomous Driving
Mar 15, 2025End-to-end autonomous driving (E2E-AD) has rapidly emerged as a promising approach toward achieving full autonomy. However, existing E2E-AD systems typically adopt a traditional multi-task framework, addressing perception, prediction, and planning tasks through separate task-specific heads. Despite being trained in a fully differentiable manner, they still encounter issues with task coordination, and the system complexity remains high. In this work, we introduce DiffAD, a novel diffusion probabilistic model that redefines autonomous driving as a conditional image generation task. By rasterizing heterogeneous targets onto a unified bird's-eye view (BEV) and modeling their latent distribution, DiffAD unifies various driving objectives and jointly optimizes all driving tasks in a single framework, significantly reducing system complexity and harmonizing task coordination. The reverse process iteratively refines the generated BEV image, resulting in more robust and realistic driving behaviors. Closed-loop evaluations in Carla demonstrate the superiority of the proposed method, achieving a new state-of-the-art Success Rate and Driving Score. The code will be made publicly available.
Adaptive Tool Use in Large Language Models with Meta-Cognition Trigger
Feb 18, 2025



Large language models (LLMs) have shown remarkable emergent capabilities, transforming the execution of functional tasks by leveraging external tools for complex problems that require specialized processing or real-time data. While existing research expands LLMs access to diverse tools (e.g., program interpreters, search engines, weather/map apps), the necessity of using these tools is often overlooked, leading to indiscriminate tool invocation. This naive approach raises two key issues:(1) increased delays due to unnecessary tool calls, and (2) potential errors resulting from faulty interactions with external tools. In this paper, we introduce meta-cognition as a proxy for LLMs self-assessment of their capabilities, representing the model's awareness of its own limitations. Based on this, we propose MeCo, an adaptive decision-making strategy for external tool use. MeCo quantifies metacognitive scores by capturing high-level cognitive signals in the representation space, guiding when to invoke tools. Notably, MeCo is fine-tuning-free and incurs minimal cost. Our experiments show that MeCo accurately detects LLMs' internal cognitive signals and significantly improves tool-use decision-making across multiple base models and benchmarks.
Frequency-Aware Guidance for Blind Image Restoration via Diffusion Models
Nov 19, 2024



Blind image restoration remains a significant challenge in low-level vision tasks. Recently, denoising diffusion models have shown remarkable performance in image synthesis. Guided diffusion models, leveraging the potent generative priors of pre-trained models along with a differential guidance loss, have achieved promising results in blind image restoration. However, these models typically consider data consistency solely in the spatial domain, often resulting in distorted image content. In this paper, we propose a novel frequency-aware guidance loss that can be integrated into various diffusion models in a plug-and-play manner. Our proposed guidance loss, based on 2D discrete wavelet transform, simultaneously enforces content consistency in both the spatial and frequency domains. Experimental results demonstrate the effectiveness of our method in three blind restoration tasks: blind image deblurring, imaging through turbulence, and blind restoration for multiple degradations. Notably, our method achieves a significant improvement in PSNR score, with a remarkable enhancement of 3.72\,dB in image deblurring. Moreover, our method exhibits superior capability in generating images with rich details and reduced distortion, leading to the best visual quality.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024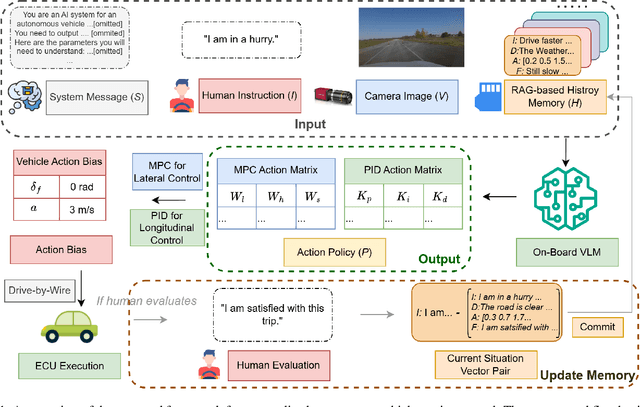
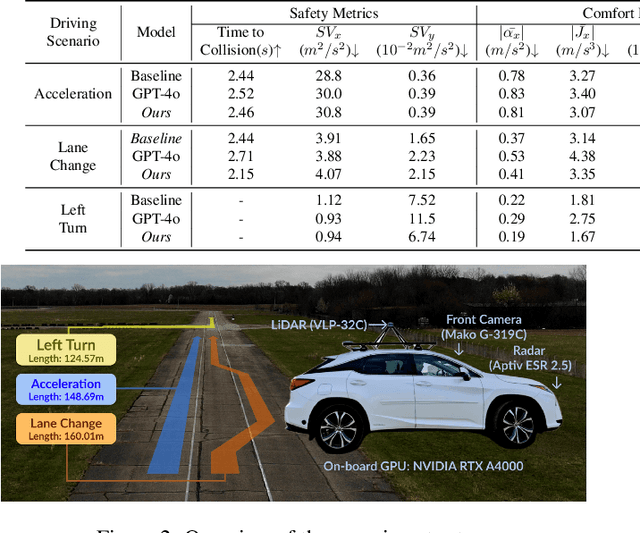

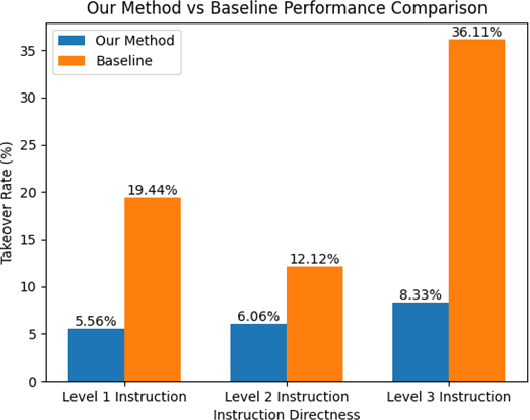
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.