 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic detection of Mild Cognitive Impairment using high-dimensional acoustic features in spontaneous speech
Paper and Code



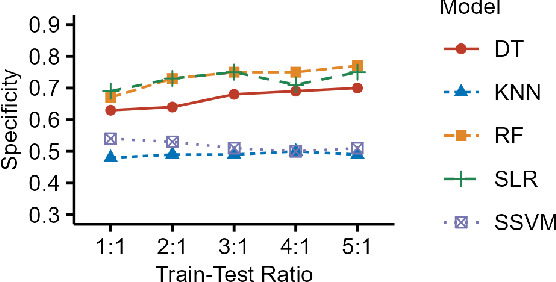
This study addresses the TAUKADIAL challenge, focusing on the classification of speech from people with Mild Cognitive Impairment (MCI) and neurotypical controls. We conducted three experiments comparing five machine-learning methods: Random Forests, Sparse Logistic Regression, k-Nearest Neighbors, Sparse Support Vector Machine, and Decision Tree, utilizing 1076 acoustic features automatically extracted using openSMILE. In Experiment 1, the entire dataset was used to train a language-agnostic model. Experiment 2 introduced a language detection step, leading to separate model training for each language. Experiment 3 further enhanced the language-agnostic model from Experiment 1, with a specific focus on evaluating the robustness of the models using out-of-sample test data. Across all three experiments, results consistently favored models capable of handling high-dimensional data, such as Random Forest and Sparse Logistic Regression, in classifying speech from MCI and controls.