 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline federated learning framework for classification
Mar 19, 2025



In this paper, we develop a novel online federated learning framework for classification, designed to handle streaming data from multiple clients while ensuring data privacy and computational efficiency. Our method leverages the generalized distance-weighted discriminant technique, making it robust to both homogeneous and heterogeneous data distributions across clients. In particular, we develop a new optimization algorithm based on the Majorization-Minimization principle, integrated with a renewable estimation procedure, enabling efficient model updates without full retraining. We provide a theoretical guarantee for the convergence of our estimator, proving its consistency and asymptotic normality under standard regularity conditions. In addition, we establish that our method achieves Bayesian risk consistency, ensuring its reliability for classification tasks in federated environments. We further incorporate differential privacy mechanisms to enhance data security, protecting client information while maintaining model performance. Extensive numerical experiments on both simulated and real-world datasets demonstrate that our approach delivers high classification accuracy, significant computational efficiency gains, and substantial savings in data storage requirements compared to existing methods.
Automatic detection of Mild Cognitive Impairment using high-dimensional acoustic features in spontaneous speech
Aug 29, 2024


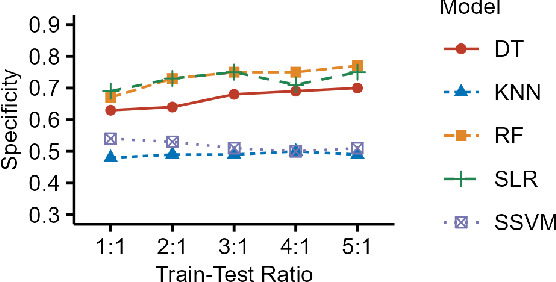
This study addresses the TAUKADIAL challenge, focusing on the classification of speech from people with Mild Cognitive Impairment (MCI) and neurotypical controls. We conducted three experiments comparing five machine-learning methods: Random Forests, Sparse Logistic Regression, k-Nearest Neighbors, Sparse Support Vector Machine, and Decision Tree, utilizing 1076 acoustic features automatically extracted using openSMILE. In Experiment 1, the entire dataset was used to train a language-agnostic model. Experiment 2 introduced a language detection step, leading to separate model training for each language. Experiment 3 further enhanced the language-agnostic model from Experiment 1, with a specific focus on evaluating the robustness of the models using out-of-sample test data. Across all three experiments, results consistently favored models capable of handling high-dimensional data, such as Random Forest and Sparse Logistic Regression, in classifying speech from MCI and controls.
Word Embeddings via Causal Inference: Gender Bias Reducing and Semantic Information Preserving
Dec 09, 2021
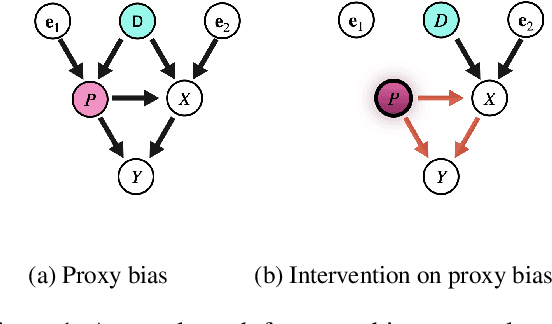
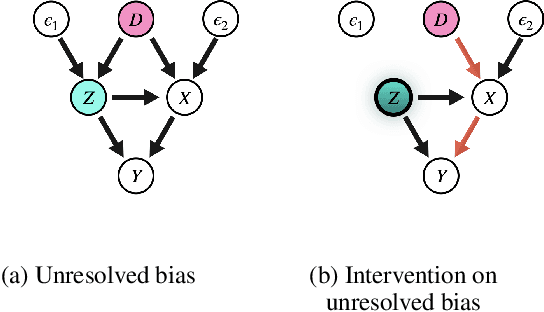
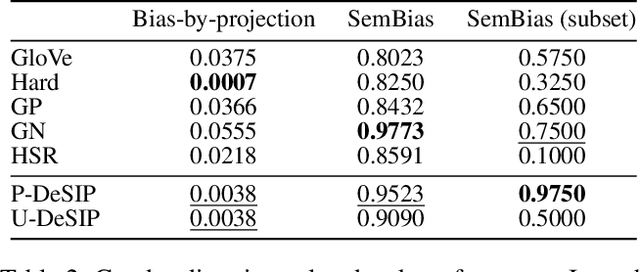
With widening deployments of natural language processing (NLP) in daily life, inherited social biases from NLP models have become more severe and problematic. Previous studies have shown that word embeddings trained on human-generated corpora have strong gender biases that can produce discriminative results in downstream tasks. Previous debiasing methods focus mainly on modeling bias and only implicitly consider semantic information while completely overlooking the complex underlying causal structure among bias and semantic components. To address these issues, we propose a novel methodology that leverages a causal inference framework to effectively remove gender bias. The proposed method allows us to construct and analyze the complex causal mechanisms facilitating gender information flow while retaining oracle semantic information within word embeddings. Our comprehensive experiments show that the proposed method achieves state-of-the-art results in gender-debiasing tasks. In addition, our methods yield better performance in word similarity evaluation and various extrinsic downstream NLP tasks.