 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTinyFormer: Efficient Transformer Design and Deployment on Tiny Devices
Nov 03, 2023



Developing deep learning models on tiny devices (e.g. Microcontroller units, MCUs) has attracted much attention in various embedded IoT applications. However, it is challenging to efficiently design and deploy recent advanced models (e.g. transformers) on tiny devices due to their severe hardware resource constraints. In this work, we propose TinyFormer, a framework specifically designed to develop and deploy resource-efficient transformers on MCUs. TinyFormer mainly consists of SuperNAS, SparseNAS and SparseEngine. Separately, SuperNAS aims to search for an appropriate supernet from a vast search space. SparseNAS evaluates the best sparse single-path model including transformer architecture from the identified supernet. Finally, SparseEngine efficiently deploys the searched sparse models onto MCUs. To the best of our knowledge, SparseEngine is the first deployment framework capable of performing inference of sparse models with transformer on MCUs. Evaluation results on the CIFAR-10 dataset demonstrate that TinyFormer can develop efficient transformers with an accuracy of $96.1\%$ while adhering to hardware constraints of $1$MB storage and $320$KB memory. Additionally, TinyFormer achieves significant speedups in sparse inference, up to $12.2\times$, when compared to the CMSIS-NN library. TinyFormer is believed to bring powerful transformers into TinyML scenarios and greatly expand the scope of deep learning applications.
Conformalized Fairness via Quantile Regression
Oct 05, 2022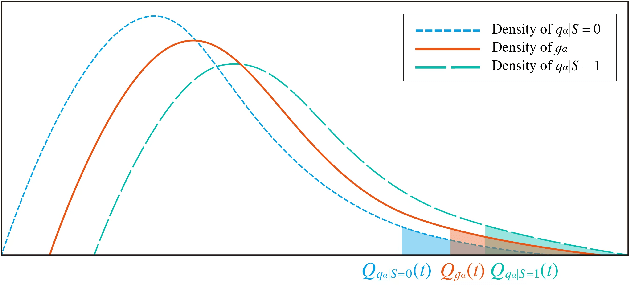
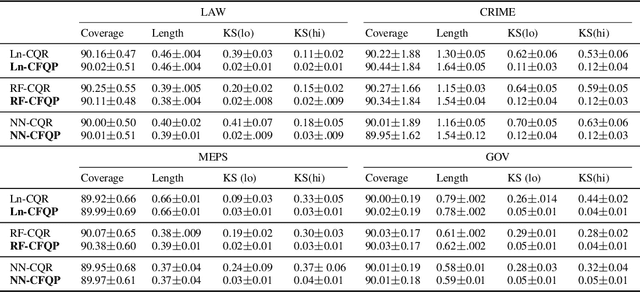
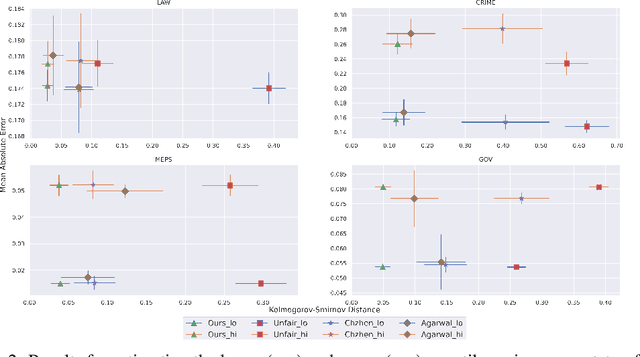
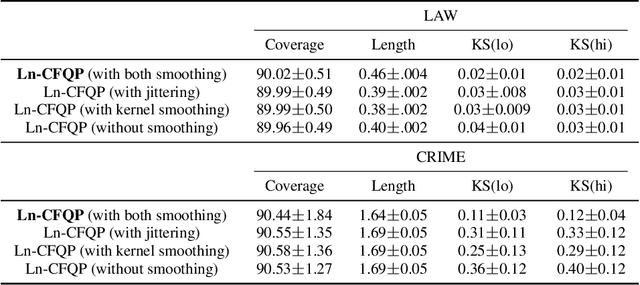
Algorithmic fairness has received increased attention in socially sensitive domains. While rich literature on mean fairness has been established, research on quantile fairness remains sparse but vital. To fulfill great needs and advocate the significance of quantile fairness, we propose a novel framework to learn a real-valued quantile function under the fairness requirement of Demographic Parity with respect to sensitive attributes, such as race or gender, and thereby derive a reliable fair prediction interval. Using optimal transport and functional synchronization techniques, we establish theoretical guarantees of distribution-free coverage and exact fairness for the induced prediction interval constructed by fair quantiles. A hands-on pipeline is provided to incorporate flexible quantile regressions with an efficient fairness adjustment post-processing algorithm. We demonstrate the superior empirical performance of this approach on several benchmark datasets. Our results show the model's ability to uncover the mechanism underlying the fairness-accuracy trade-off in a wide range of societal and medical applications.
Word Embeddings via Causal Inference: Gender Bias Reducing and Semantic Information Preserving
Dec 09, 2021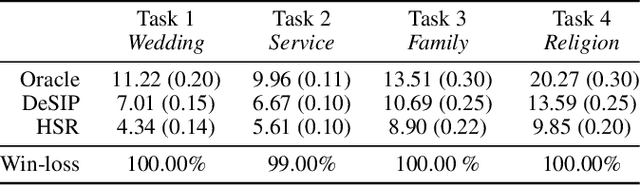
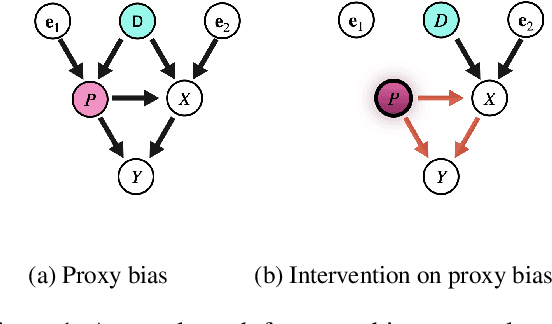
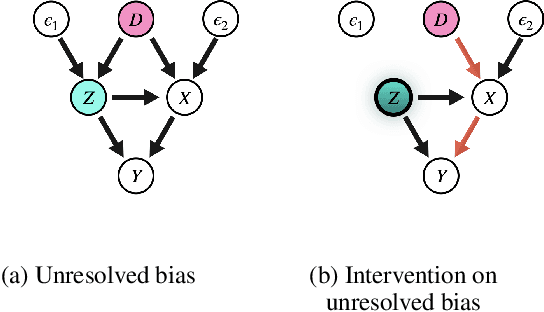
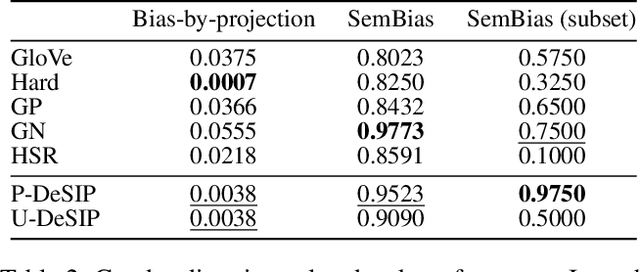
With widening deployments of natural language processing (NLP) in daily life, inherited social biases from NLP models have become more severe and problematic. Previous studies have shown that word embeddings trained on human-generated corpora have strong gender biases that can produce discriminative results in downstream tasks. Previous debiasing methods focus mainly on modeling bias and only implicitly consider semantic information while completely overlooking the complex underlying causal structure among bias and semantic components. To address these issues, we propose a novel methodology that leverages a causal inference framework to effectively remove gender bias. The proposed method allows us to construct and analyze the complex causal mechanisms facilitating gender information flow while retaining oracle semantic information within word embeddings. Our comprehensive experiments show that the proposed method achieves state-of-the-art results in gender-debiasing tasks. In addition, our methods yield better performance in word similarity evaluation and various extrinsic downstream NLP tasks.
Computational efficient deep neural network with difference attention maps for facial action unit detection
Nov 27, 2020


In this paper, we propose a computational efficient end-to-end training deep neural network (CEDNN) model and spatial attention maps based on difference images. Firstly, the difference image is generated by image processing. Then five binary images of difference images are obtained using different thresholds, which are used as spatial attention maps. We use group convolution to reduce model complexity. Skip connection and $\text{1}\times \text{1}$ convolution are used to ensure good performance even if the network model is not deep. As an input, spatial attention map can be selectively fed into the input of each block. The feature maps tend to focus on the parts that are related to the target task better. In addition, we only need to adjust the parameters of classifier to train different numbers of AU. It can be easily extended to varying datasets without increasing too much computation. A large number of experimental results show that the proposed CEDNN is obviously better than the traditional deep learning method on DISFA+ and CK+ datasets. After adding spatial attention maps, the result is better than the most advanced AU detection method. At the same time, the scale of the network is small, the running speed is fast, and the requirement for experimental equipment is low.
Person image generation with semantic attention network for person re-identification
Aug 18, 2020
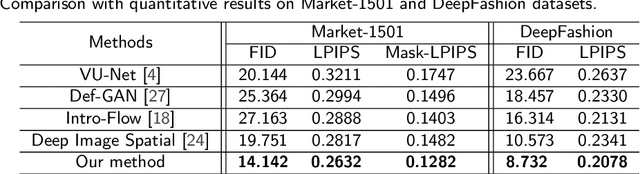
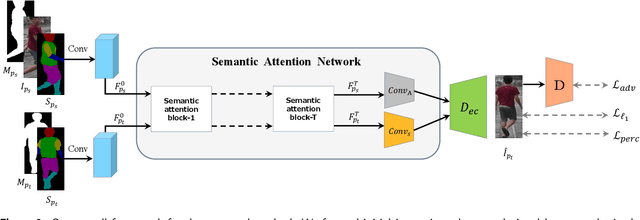
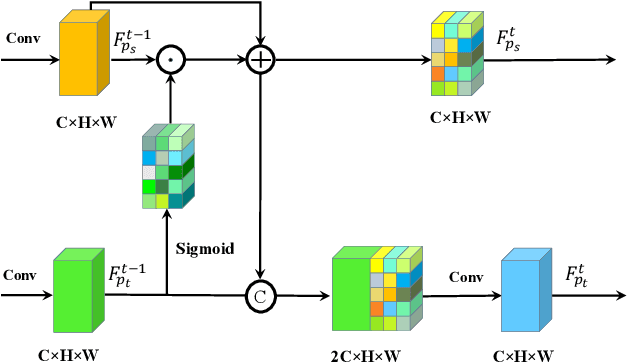
Pose variation is one of the key factors which prevents the network from learning a robust person re-identification (Re-ID) model. To address this issue, we propose a novel person pose-guided image generation method, which is called the semantic attention network. The network consists of several semantic attention blocks, where each block attends to preserve and update the pose code and the clothing textures. The introduction of the binary segmentation mask and the semantic parsing is important for seamlessly stitching foreground and background in the pose-guided image generation. Compared with other methods, our network can characterize better body shape and keep clothing attributes, simultaneously. Our synthesized image can obtain better appearance and shape consistency related to the original image. Experimental results show that our approach is competitive with respect to both quantitative and qualitative results on Market-1501 and DeepFashion. Furthermore, we conduct extensive evaluations by using person re-identification (Re-ID) systems trained with the pose-transferred person based augmented data. The experiment shows that our approach can significantly enhance the person Re-ID accuracy.
HEU Emotion: A Large-scale Database for Multi-modal Emotion Recognition in the Wild
Jul 24, 2020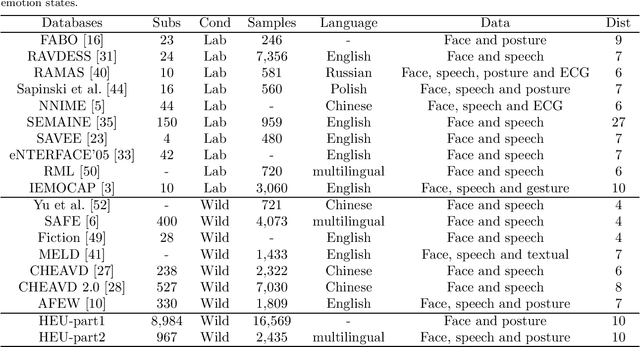
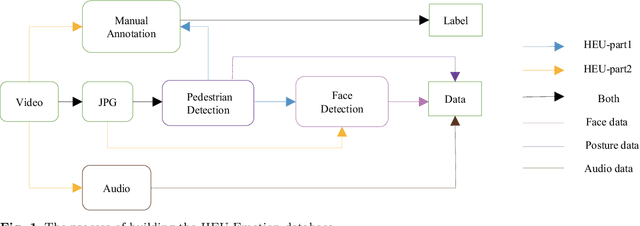


The study of affective computing in the wild setting is underpinned by databases. Existing multimodal emotion databases in the real-world conditions are few and small, with a limited number of subjects and expressed in a single language. To meet this requirement, we collected, annotated, and prepared to release a new natural state video database (called HEU Emotion). HEU Emotion contains a total of 19,004 video clips, which is divided into two parts according to the data source. The first part contains videos downloaded from Tumblr, Google, and Giphy, including 10 emotions and two modalities (facial expression and body posture). The second part includes corpus taken manually from movies, TV series, and variety shows, consisting of 10 emotions and three modalities (facial expression, body posture, and emotional speech). HEU Emotion is by far the most extensive multi-modal emotional database with 9,951 subjects. In order to provide a benchmark for emotion recognition, we used many conventional machine learning and deep learning methods to evaluate HEU Emotion. We proposed a Multi-modal Attention module to fuse multi-modal features adaptively. After multi-modal fusion, the recognition accuracies for the two parts increased by 2.19% and 4.01% respectively over those of single-modal facial expression recognition.