 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrincipled Fast and Meta Knowledge Learners for Continual Reinforcement Learning
Mar 01, 2026Inspired by the human learning and memory system, particularly the interplay between the hippocampus and cerebral cortex, this study proposes a dual-learner framework comprising a fast learner and a meta learner to address continual Reinforcement Learning~(RL) problems. These two learners are coupled to perform distinct yet complementary roles: the fast learner focuses on knowledge transfer, while the meta learner ensures knowledge integration. In contrast to traditional multi-task RL approaches that share knowledge through average return maximization, our meta learner incrementally integrates new experiences by explicitly minimizing catastrophic forgetting, thereby supporting efficient cumulative knowledge transfer for the fast learner. To facilitate rapid adaptation in new environments, we introduce an adaptive meta warm-up mechanism that selectively harnesses past knowledge. We conduct experiments in various pixel-based and continuous control benchmarks, revealing the superior performance of continual learning for our proposed dual-learner approach relative to baseline methods. The code is released in https://github.com/datake/FAME.
Faster and Better LLMs via Latency-Aware Test-Time Scaling
May 26, 2025Test-Time Scaling (TTS) has proven effective in improving the performance of Large Language Models (LLMs) during inference. However, existing research has overlooked the efficiency of TTS from a latency-sensitive perspective. Through a latency-aware evaluation of representative TTS methods, we demonstrate that a compute-optimal TTS does not always result in the lowest latency in scenarios where latency is critical. To address this gap and achieve latency-optimal TTS, we propose two key approaches by optimizing the concurrency configurations: (1) branch-wise parallelism, which leverages multiple concurrent inference branches, and (2) sequence-wise parallelism, enabled by speculative decoding. By integrating these two approaches and allocating computational resources properly to each, our latency-optimal TTS enables a 32B model to reach 82.3% accuracy on MATH-500 within 1 minute and a smaller 3B model to achieve 72.4% within 10 seconds. Our work emphasizes the importance of latency-aware TTS and demonstrates its ability to deliver both speed and accuracy in latency-sensitive scenarios.
PreMoe: Lightening MoEs on Constrained Memory by Expert Pruning and Retrieval
May 23, 2025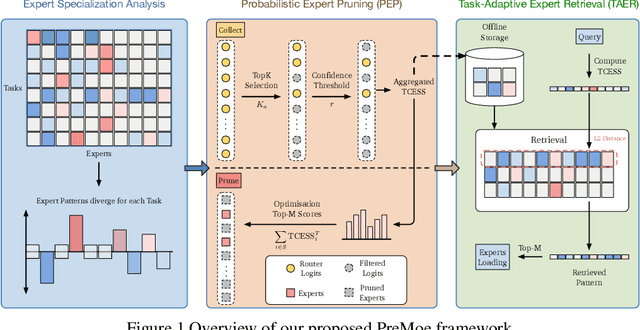
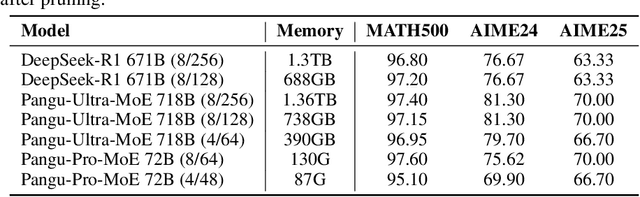
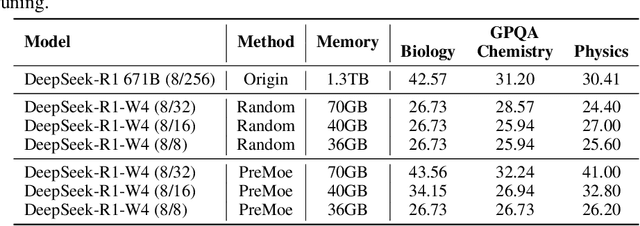
Mixture-of-experts (MoE) architectures enable scaling large language models (LLMs) to vast parameter counts without a proportional rise in computational costs. However, the significant memory demands of large MoE models hinder their deployment across various computational environments, from cloud servers to consumer devices. This study first demonstrates pronounced task-specific specialization in expert activation patterns within MoE layers. Building on this, we introduce PreMoe, a novel framework that enables efficient deployment of massive MoE models in memory-constrained environments. PreMoe features two main components: probabilistic expert pruning (PEP) and task-adaptive expert retrieval (TAER). PEP employs a new metric, the task-conditioned expected selection score (TCESS), derived from router logits to quantify expert importance for specific tasks, thereby identifying a minimal set of critical experts. TAER leverages these task-specific expert importance profiles for efficient inference. It pre-computes and stores compact expert patterns for diverse tasks. When a user query is received, TAER rapidly identifies the most relevant stored task pattern and reconstructs the model by loading only the small subset of experts crucial for that task. This approach dramatically reduces the memory footprint across all deployment scenarios. DeepSeek-R1 671B maintains 97.2\% accuracy on MATH500 when pruned to 8/128 configuration (50\% expert reduction), and still achieves 72.0\% with aggressive 8/32 pruning (87.5\% expert reduction). Pangu-Ultra-MoE 718B achieves 97.15\% on MATH500 and 81.3\% on AIME24 with 8/128 pruning, while even more aggressive pruning to 4/64 (390GB memory) preserves 96.95\% accuracy on MATH500. We make our code publicly available at https://github.com/JarvisPei/PreMoe.
TrimR: Verifier-based Training-Free Thinking Compression for Efficient Test-Time Scaling
May 22, 2025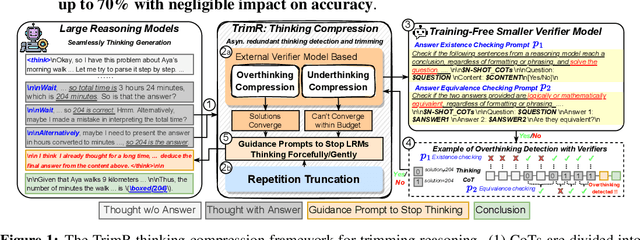
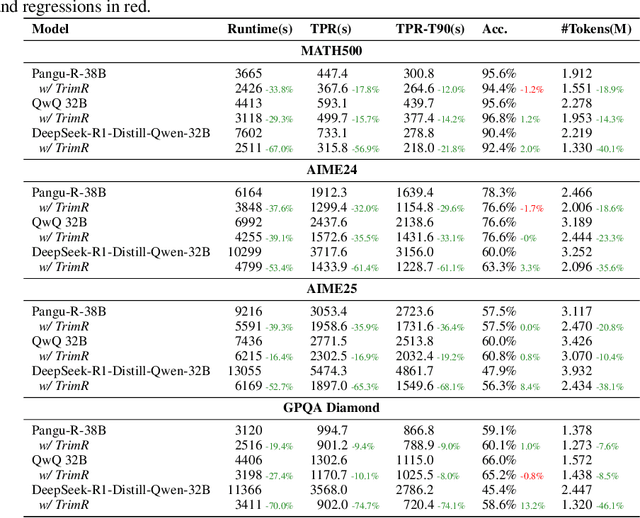
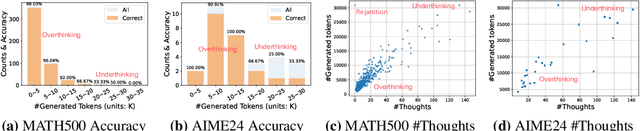
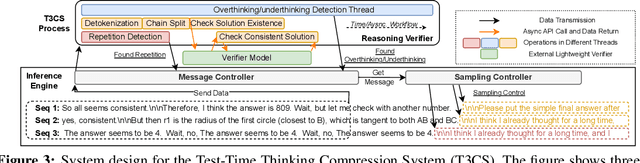
Large Reasoning Models (LRMs) demonstrate exceptional capability in tackling complex mathematical, logical, and coding tasks by leveraging extended Chain-of-Thought (CoT) reasoning. Test-time scaling methods, such as prolonging CoT with explicit token-level exploration, can push LRMs' accuracy boundaries, but they incur significant decoding overhead. A key inefficiency source is LRMs often generate redundant thinking CoTs, which demonstrate clear structured overthinking and underthinking patterns. Inspired by human cognitive reasoning processes and numerical optimization theories, we propose TrimR, a verifier-based, training-free, efficient framework for dynamic CoT compression to trim reasoning and enhance test-time scaling, explicitly tailored for production-level deployment. Our method employs a lightweight, pretrained, instruction-tuned verifier to detect and truncate redundant intermediate thoughts of LRMs without any LRM or verifier fine-tuning. We present both the core algorithm and asynchronous online system engineered for high-throughput industrial applications. Empirical evaluations on Ascend NPUs and vLLM show that our framework delivers substantial gains in inference efficiency under large-batch workloads. In particular, on the four MATH500, AIME24, AIME25, and GPQA benchmarks, the reasoning runtime of Pangu-R-38B, QwQ-32B, and DeepSeek-R1-Distill-Qwen-32B is improved by up to 70% with negligible impact on accuracy.
Pangu Ultra MoE: How to Train Your Big MoE on Ascend NPUs
May 07, 2025



Sparse large language models (LLMs) with Mixture of Experts (MoE) and close to a trillion parameters are dominating the realm of most capable language models. However, the massive model scale poses significant challenges for the underlying software and hardware systems. In this paper, we aim to uncover a recipe to harness such scale on Ascend NPUs. The key goals are better usage of the computing resources under the dynamic sparse model structures and materializing the expected performance gain on the actual hardware. To select model configurations suitable for Ascend NPUs without repeatedly running the expensive experiments, we leverage simulation to compare the trade-off of various model hyperparameters. This study led to Pangu Ultra MoE, a sparse LLM with 718 billion parameters, and we conducted experiments on the model to verify the simulation results. On the system side, we dig into Expert Parallelism to optimize the communication between NPU devices to reduce the synchronization overhead. We also optimize the memory efficiency within the devices to further reduce the parameter and activation management overhead. In the end, we achieve an MFU of 30.0% when training Pangu Ultra MoE, with performance comparable to that of DeepSeek R1, on 6K Ascend NPUs, and demonstrate that the Ascend system is capable of harnessing all the training stages of the state-of-the-art language models. Extensive experiments indicate that our recipe can lead to efficient training of large-scale sparse language models with MoE. We also study the behaviors of such models for future reference.
Pangu Ultra: Pushing the Limits of Dense Large Language Models on Ascend NPUs
Apr 10, 2025



We present Pangu Ultra, a Large Language Model (LLM) with 135 billion parameters and dense Transformer modules trained on Ascend Neural Processing Units (NPUs). Although the field of LLM has been witnessing unprecedented advances in pushing the scale and capability of LLM in recent years, training such a large-scale model still involves significant optimization and system challenges. To stabilize the training process, we propose depth-scaled sandwich normalization, which effectively eliminates loss spikes during the training process of deep models. We pre-train our model on 13.2 trillion diverse and high-quality tokens and further enhance its reasoning capabilities during post-training. To perform such large-scale training efficiently, we utilize 8,192 Ascend NPUs with a series of system optimizations. Evaluations on multiple diverse benchmarks indicate that Pangu Ultra significantly advances the state-of-the-art capabilities of dense LLMs such as Llama 405B and Mistral Large 2, and even achieves competitive results with DeepSeek-R1, whose sparse model structure contains much more parameters. Our exploration demonstrates that Ascend NPUs are capable of efficiently and effectively training dense models with more than 100 billion parameters. Our model and system will be available for our commercial customers.
FCoT-VL:Advancing Text-oriented Large Vision-Language Models with Efficient Visual Token Compression
Feb 22, 2025The rapid success of Vision Large Language Models (VLLMs) often depends on the high-resolution images with abundant visual tokens, which hinders training and deployment efficiency. Current training-free visual token compression methods exhibit serious performance degradation in tasks involving high-resolution, text-oriented image understanding and reasoning. In this paper, we propose an efficient visual token compression framework for text-oriented VLLMs in high-resolution scenarios. In particular, we employ a light-weight self-distillation pre-training stage to compress the visual tokens, requiring a limited numbers of image-text pairs and minimal learnable parameters. Afterwards, to mitigate potential performance degradation of token-compressed models, we construct a high-quality post-train stage. To validate the effectiveness of our method, we apply it to an advanced VLLMs, InternVL2. Experimental results show that our approach significantly reduces computational overhead while outperforming the baselines across a range of text-oriented benchmarks. We will release the models and code soon.
CMoE: Fast Carving of Mixture-of-Experts for Efficient LLM Inference
Feb 06, 2025



Large language models (LLMs) achieve impressive performance by scaling model parameters, but this comes with significant inference overhead. Feed-forward networks (FFNs), which dominate LLM parameters, exhibit high activation sparsity in hidden neurons. To exploit this, researchers have proposed using a mixture-of-experts (MoE) architecture, where only a subset of parameters is activated. However, existing approaches often require extensive training data and resources, limiting their practicality. We propose CMoE (Carved MoE), a novel framework to efficiently carve MoE models from dense models. CMoE achieves remarkable performance through efficient expert grouping and lightweight adaptation. First, neurons are grouped into shared and routed experts based on activation rates. Next, we construct a routing mechanism without training from scratch, incorporating a differentiable routing process and load balancing. Using modest data, CMoE produces a well-designed, usable MoE from a 7B dense model within five minutes. With lightweight fine-tuning, it achieves high-performance recovery in under an hour. We make our code publicly available at https://github.com/JarvisPei/CMoE.
AttentionPredictor: Temporal Pattern Matters for Efficient LLM Inference
Feb 06, 2025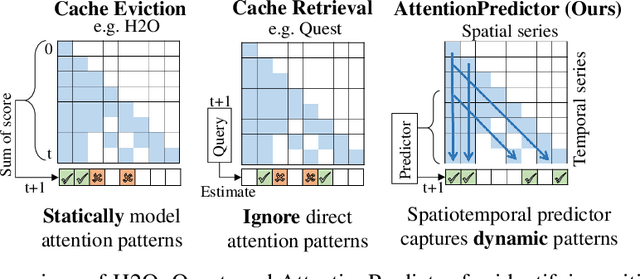

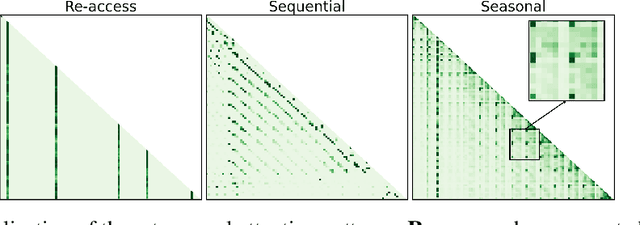

With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through heuristic ranking with attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the \textit{temporal patterns} in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based critical token identification approach. Specifically, AttentionPredictor learns a lightweight convolution model to capture spatiotemporal patterns and predict the next-token attention score. An appealing feature of AttentionPredictor is that it accurately predicts the attention score while consuming negligible memory. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 16$\times$ KV cache compression with comparable LLM performance, significantly outperforming the state-of-the-art.
KVTuner: Sensitivity-Aware Layer-wise Mixed Precision KV Cache Quantization for Efficient and Nearly Lossless LLM Inference
Feb 06, 2025



KV cache quantization can improve Large Language Models (LLMs) inference throughput and latency in long contexts and large batch-size scenarios while preserving LLMs effectiveness. However, current methods have three unsolved issues: overlooking layer-wise sensitivity to KV cache quantization, high overhead of online fine-grained decision-making, and low flexibility to different LLMs and constraints. Therefore, we thoroughly analyze the inherent correlation of layer-wise transformer attention patterns to KV cache quantization errors and study why key cache is more important than value cache for quantization error reduction. We further propose a simple yet effective framework KVTuner to adaptively search for the optimal hardware-friendly layer-wise KV quantization precision pairs for coarse-grained KV cache with multi-objective optimization and directly utilize the offline searched configurations during online inference. To reduce the computational cost of offline calibration, we utilize the intra-layer KV precision pair pruning and inter-layer clustering to reduce the search space. Experimental results show that we can achieve nearly lossless 3.25-bit mixed precision KV cache quantization for LLMs like Llama-3.1-8B-Instruct and 4.0-bit for sensitive models like Qwen2.5-7B-Instruct on mathematical reasoning tasks. The maximum inference throughput can be improved by 38.3% compared with KV8 quantization over various context lengths.