 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttentionPredictor: Temporal Pattern Matters for Efficient LLM Inference
Paper and Code
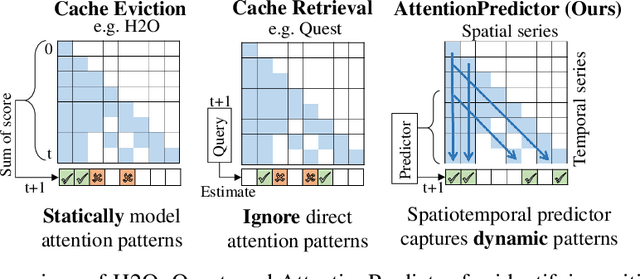

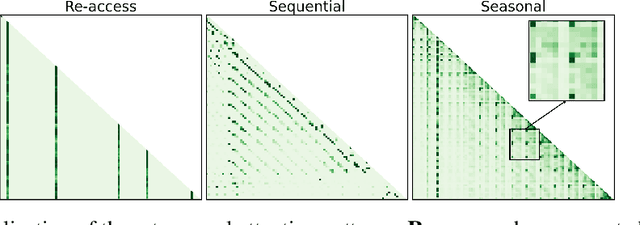

With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through heuristic ranking with attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the \textit{temporal patterns} in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based critical token identification approach. Specifically, AttentionPredictor learns a lightweight convolution model to capture spatiotemporal patterns and predict the next-token attention score. An appealing feature of AttentionPredictor is that it accurately predicts the attention score while consuming negligible memory. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 16$\times$ KV cache compression with comparable LLM performance, significantly outperforming the state-of-the-art.