 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy Attention Patterns Exist: A Unifying Temporal Perspective Analysis
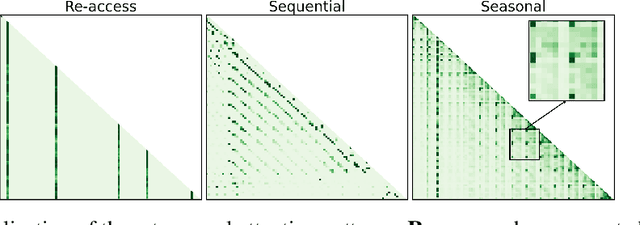
Jan 29, 2026Attention patterns play a crucial role in both training and inference of large language models (LLMs). Prior works have identified individual patterns such as retrieval heads, sink heads, and diagonal traces, yet these observations remain fragmented and lack a unifying explanation. To bridge this gap, we introduce \textbf{Temporal Attention Pattern Predictability Analysis (TAPPA), a unifying framework that explains diverse attention patterns by analyzing their underlying mathematical formulations} from a temporally continuous perspective. TAPPA both deepens the understanding of attention behavior and guides inference acceleration approaches. Specifically, TAPPA characterizes attention patterns as predictable patterns with clear regularities and unpredictable patterns that appear effectively random. Our analysis further reveals that this distinction can be explained by the degree of query self-similarity along the temporal dimension. Focusing on the predictable patterns, we further provide a detailed mathematical analysis of three representative cases through the joint effect of queries, keys, and Rotary Positional Embeddings (RoPE). We validate TAPPA by applying its insights to KV cache compression and LLM pruning tasks. Across these tasks, a simple metric motivated by TAPPA consistently improves performance over baseline methods. The code is available at https://github.com/MIRALab-USTC/LLM-TAPPA.
AttentionPredictor: Temporal Pattern Matters for Efficient LLM Inference
Feb 06, 2025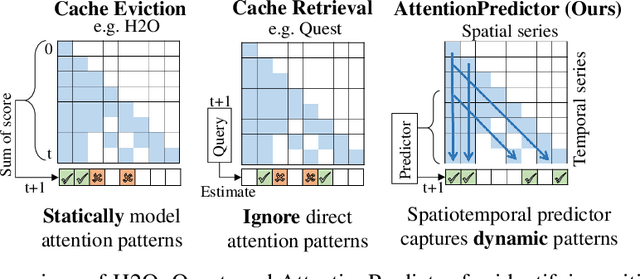


With the development of large language models (LLMs), efficient inference through Key-Value (KV) cache compression has attracted considerable attention, especially for long-context generation. To compress the KV cache, recent methods identify critical KV tokens through heuristic ranking with attention scores. However, these methods often struggle to accurately determine critical tokens as they neglect the \textit{temporal patterns} in attention scores, resulting in a noticeable degradation in LLM performance. To address this challenge, we propose AttentionPredictor, which is the first learning-based critical token identification approach. Specifically, AttentionPredictor learns a lightweight convolution model to capture spatiotemporal patterns and predict the next-token attention score. An appealing feature of AttentionPredictor is that it accurately predicts the attention score while consuming negligible memory. Moreover, we propose a cross-token critical cache prefetching framework that hides the token estimation time overhead to accelerate the decoding stage. By retaining most of the attention information, AttentionPredictor achieves 16$\times$ KV cache compression with comparable LLM performance, significantly outperforming the state-of-the-art.
Frequency Decomposition to Tap the Potential of Single Domain for Generalization
Apr 14, 2023



Domain generalization (DG), aiming at models able to work on multiple unseen domains, is a must-have characteristic of general artificial intelligence. DG based on single source domain training data is more challenging due to the lack of comparable information to help identify domain invariant features. In this paper, it is determined that the domain invariant features could be contained in the single source domain training samples, then the task is to find proper ways to extract such domain invariant features from the single source domain samples. An assumption is made that the domain invariant features are closely related to the frequency. Then, a new method that learns through multiple frequency domains is proposed. The key idea is, dividing the frequency domain of each original image into multiple subdomains, and learning features in the subdomain by a designed two branches network. In this way, the model is enforced to learn features from more samples of the specifically limited spectrum, which increases the possibility of obtaining the domain invariant features that might have previously been defiladed by easily learned features. Extensive experimental investigation reveals that 1) frequency decomposition can help the model learn features that are difficult to learn. 2) the proposed method outperforms the state-of-the-art methods of single-source domain generalization.