 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Macro to Micro: Boosting micro-expression recognition via pre-training on macro-expression videos
May 26, 2024Micro-expression recognition (MER) has drawn increasing attention in recent years due to its potential applications in intelligent medical and lie detection. However, the shortage of annotated data has been the major obstacle to further improve deep-learning based MER methods. Intuitively, utilizing sufficient macro-expression data to promote MER performance seems to be a feasible solution. However, the facial patterns of macro-expressions and micro-expressions are significantly different, which makes naive transfer learning methods difficult to deploy directly. To tacle this issue, we propose a generalized transfer learning paradigm, called \textbf{MA}cro-expression \textbf{TO} \textbf{MI}cro-expression (MA2MI). Under our paradigm, networks can learns the ability to represent subtle facial movement by reconstructing future frames. In addition, we also propose a two-branch micro-action network (MIACNet) to decouple facial position features and facial action features, which can help the network more accurately locate facial action locations. Extensive experiments on three popular MER benchmarks demonstrate the superiority of our method.
Frequency Decomposition to Tap the Potential of Single Domain for Generalization
Apr 14, 2023



Domain generalization (DG), aiming at models able to work on multiple unseen domains, is a must-have characteristic of general artificial intelligence. DG based on single source domain training data is more challenging due to the lack of comparable information to help identify domain invariant features. In this paper, it is determined that the domain invariant features could be contained in the single source domain training samples, then the task is to find proper ways to extract such domain invariant features from the single source domain samples. An assumption is made that the domain invariant features are closely related to the frequency. Then, a new method that learns through multiple frequency domains is proposed. The key idea is, dividing the frequency domain of each original image into multiple subdomains, and learning features in the subdomain by a designed two branches network. In this way, the model is enforced to learn features from more samples of the specifically limited spectrum, which increases the possibility of obtaining the domain invariant features that might have previously been defiladed by easily learned features. Extensive experimental investigation reveals that 1) frequency decomposition can help the model learn features that are difficult to learn. 2) the proposed method outperforms the state-of-the-art methods of single-source domain generalization.
CLIPER: A Unified Vision-Language Framework for In-the-Wild Facial Expression Recognition
Mar 01, 2023Facial expression recognition (FER) is an essential task for understanding human behaviors. As one of the most informative behaviors of humans, facial expressions are often compound and variable, which is manifested by the fact that different people may express the same expression in very different ways. However, most FER methods still use one-hot or soft labels as the supervision, which lack sufficient semantic descriptions of facial expressions and are less interpretable. Recently, contrastive vision-language pre-training (VLP) models (e.g., CLIP) use text as supervision and have injected new vitality into various computer vision tasks, benefiting from the rich semantics in text. Therefore, in this work, we propose CLIPER, a unified framework for both static and dynamic facial Expression Recognition based on CLIP. Besides, we introduce multiple expression text descriptors (METD) to learn fine-grained expression representations that make CLIPER more interpretable. We conduct extensive experiments on several popular FER benchmarks and achieve state-of-the-art performance, which demonstrates the effectiveness of CLIPER.
Domain-Unified Prompt Representations for Source-Free Domain Generalization
Sep 29, 2022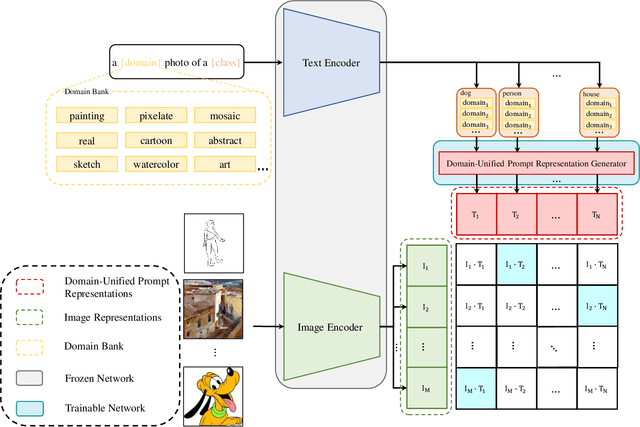
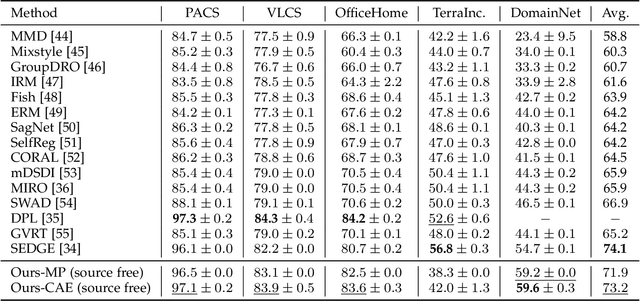
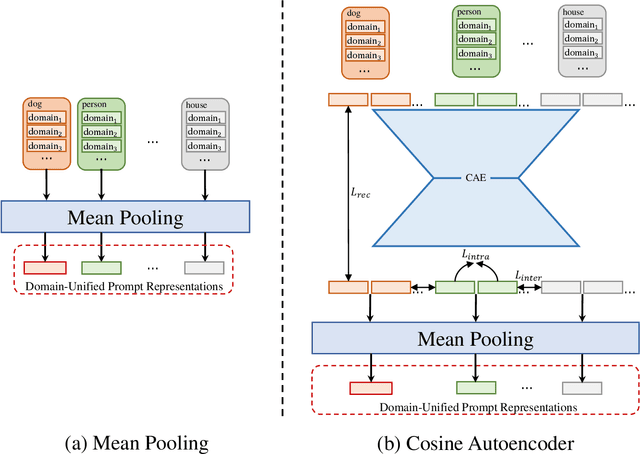

Domain generalization (DG), aiming to make models work on unseen domains, is a surefire way toward general artificial intelligence. Limited by the scale and diversity of current DG datasets, it is difficult for existing methods to scale to diverse domains in open-world scenarios (e.g., science fiction and pixelate style). Therefore, the source-free domain generalization (SFDG) task is necessary and challenging. To address this issue, we propose an approach based on large-scale vision-language pretraining models (e.g., CLIP), which exploits the extensive domain information embedded in it. The proposed scheme generates diverse prompts from a domain bank that contains many more diverse domains than existing DG datasets. Furthermore, our method yields domain-unified representations from these prompts, thus being able to cope with samples from open-world domains. Extensive experiments on mainstream DG datasets, namely PACS, VLCS, OfficeHome, and DomainNet, show that the proposed method achieves competitive performance compared to state-of-the-art (SOTA) DG methods that require source domain data for training. Besides, we collect a small datasets consists of two domains to evaluate the open-world domain generalization ability of the proposed method. The source code and the dataset will be made publicly available at https://github.com/muse1998/Source-Free-Domain-Generalization
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022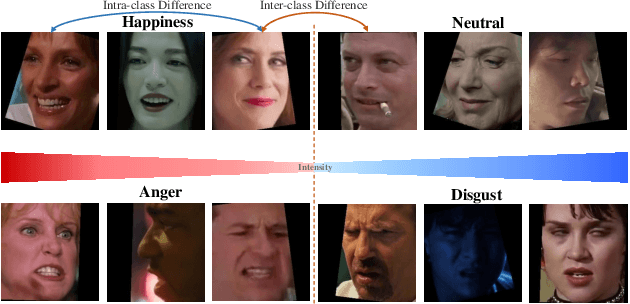
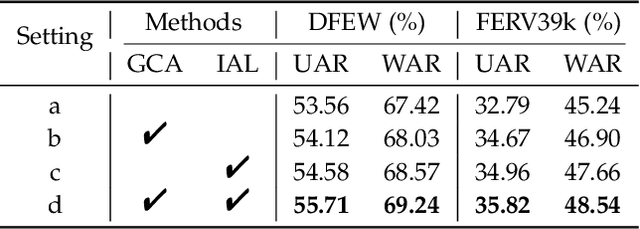
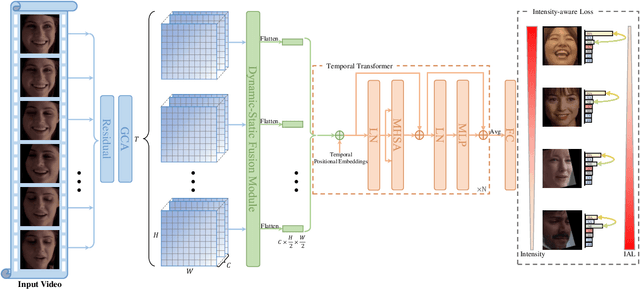
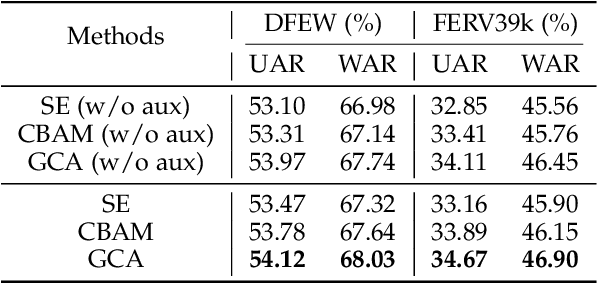
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.
A Statistical Difference Reduction Method for Escaping Backdoor Detection
Nov 09, 2021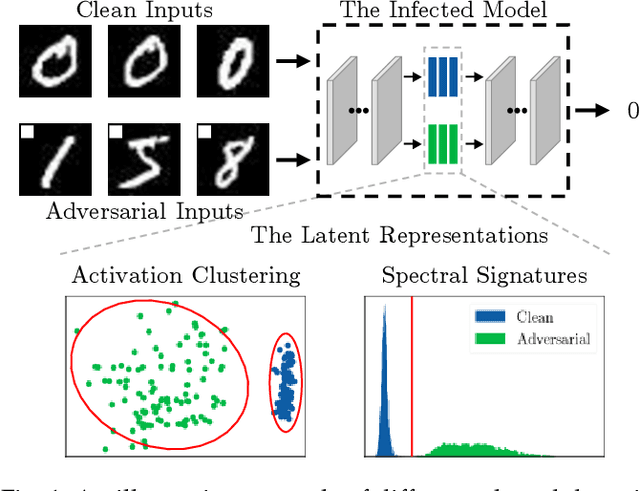


Recent studies show that Deep Neural Networks (DNNs) are vulnerable to backdoor attacks. An infected model behaves normally on benign inputs, whereas its prediction will be forced to an attack-specific target on adversarial data. Several detection methods have been developed to distinguish inputs to defend against such attacks. The common hypothesis that these defenses rely on is that there are large statistical differences between the latent representations of clean and adversarial inputs extracted by the infected model. However, although it is important, comprehensive research on whether the hypothesis must be true is lacking. In this paper, we focus on it and study the following relevant questions: 1) What are the properties of the statistical differences? 2) How to effectively reduce them without harming the attack intensity? 3) What impact does this reduction have on difference-based defenses? Our work is carried out on the three questions. First, by introducing the Maximum Mean Discrepancy (MMD) as the metric, we identify that the statistical differences of multi-level representations are all large, not just the highest level. Then, we propose a Statistical Difference Reduction Method (SDRM) by adding a multi-level MMD constraint to the loss function during training a backdoor model to effectively reduce the differences. Last, three typical difference-based detection methods are examined. The F1 scores of these defenses drop from 90%-100% on the regularly trained backdoor models to 60%-70% on the models trained with SDRM on all two datasets, four model architectures, and four attack methods. The results indicate that the proposed method can be used to enhance existing attacks to escape backdoor detection algorithms.
Interpreting the Latent Space of GANs via Correlation Analysis for Controllable Concept Manipulation
May 23, 2020
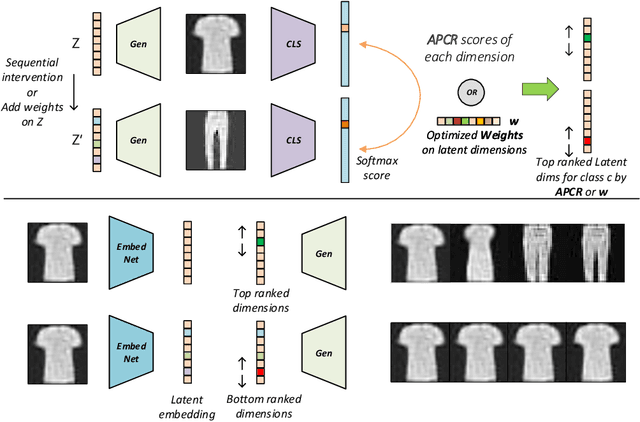
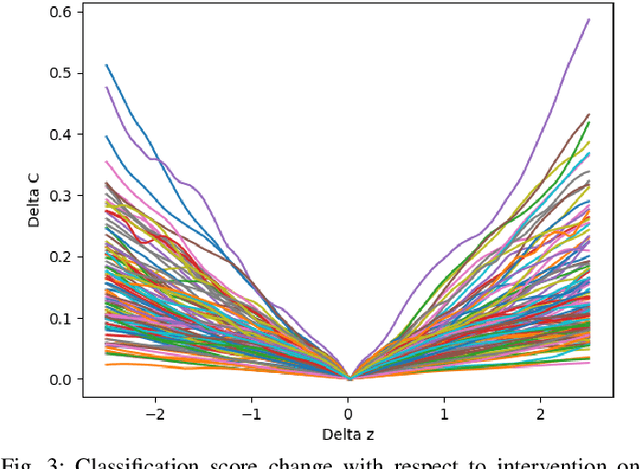
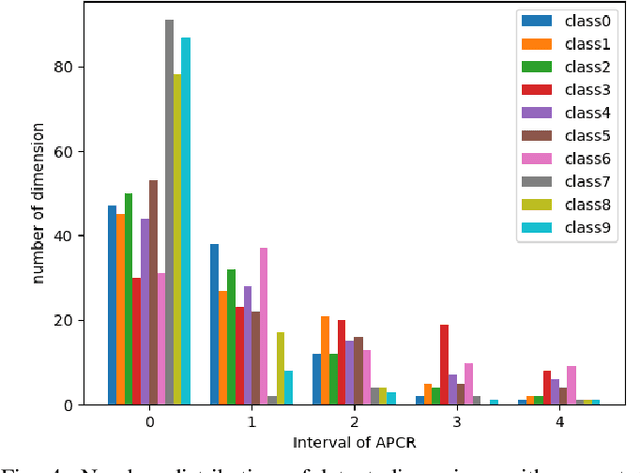
Generative adversarial nets (GANs) have been successfully applied in many fields like image generation, inpainting, super-resolution and drug discovery, etc., by now, the inner process of GANs is far from been understood. To get deeper insight of the intrinsic mechanism of GANs, in this paper, a method for interpreting the latent space of GANs by analyzing the correlation between latent variables and the corresponding semantic contents in generated images is proposed. Unlike previous methods that focus on dissecting models via feature visualization, the emphasis of this work is put on the variables in latent space, i.e. how the latent variables affect the quantitative analysis of generated results. Given a pretrained GAN model with weights fixed, the latent variables are intervened to analyze their effect on the semantic content in generated images. A set of controlling latent variables can be derived for specific content generation, and the controllable semantic content manipulation be achieved. The proposed method is testified on the datasets Fashion-MNIST and UT Zappos50K, experiment results show its effectiveness.