 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Sequential to Spatial: Reordering Autoregression for Efficient Visual Generation
Dec 31, 2025Inspired by the remarkable success of autoregressive models in language modeling, this paradigm has been widely adopted in visual generation. However, the sequential token-by-token decoding mechanism inherent in traditional autoregressive models leads to low inference efficiency.In this paper, we propose RadAR, an efficient and parallelizable framework designed to accelerate autoregressive visual generation while preserving its representational capacity. Our approach is motivated by the observation that visual tokens exhibit strong local dependencies and spatial correlations with their neighbors--a property not fully exploited in standard raster-scan decoding orders. Specifically, we organize the generation process around a radial topology: an initial token is selected as the starting point, and all other tokens are systematically grouped into multiple concentric rings according to their spatial distances from this center. Generation then proceeds in a ring-wise manner, from inner to outer regions, enabling the parallel prediction of all tokens within the same ring. This design not only preserves the structural locality and spatial coherence of visual scenes but also substantially increases parallelization. Furthermore, to address the risk of inconsistent predictions arising from simultaneous token generation with limited context, we introduce a nested attention mechanism. This mechanism dynamically refines implausible outputs during the forward pass, thereby mitigating error accumulation and preventing model collapse. By integrating radial parallel prediction with dynamic output correction, RadAR significantly improves generation efficiency.
From Macro to Micro: Boosting micro-expression recognition via pre-training on macro-expression videos
May 26, 2024Micro-expression recognition (MER) has drawn increasing attention in recent years due to its potential applications in intelligent medical and lie detection. However, the shortage of annotated data has been the major obstacle to further improve deep-learning based MER methods. Intuitively, utilizing sufficient macro-expression data to promote MER performance seems to be a feasible solution. However, the facial patterns of macro-expressions and micro-expressions are significantly different, which makes naive transfer learning methods difficult to deploy directly. To tacle this issue, we propose a generalized transfer learning paradigm, called \textbf{MA}cro-expression \textbf{TO} \textbf{MI}cro-expression (MA2MI). Under our paradigm, networks can learns the ability to represent subtle facial movement by reconstructing future frames. In addition, we also propose a two-branch micro-action network (MIACNet) to decouple facial position features and facial action features, which can help the network more accurately locate facial action locations. Extensive experiments on three popular MER benchmarks demonstrate the superiority of our method.
CLIPER: A Unified Vision-Language Framework for In-the-Wild Facial Expression Recognition
Mar 01, 2023Facial expression recognition (FER) is an essential task for understanding human behaviors. As one of the most informative behaviors of humans, facial expressions are often compound and variable, which is manifested by the fact that different people may express the same expression in very different ways. However, most FER methods still use one-hot or soft labels as the supervision, which lack sufficient semantic descriptions of facial expressions and are less interpretable. Recently, contrastive vision-language pre-training (VLP) models (e.g., CLIP) use text as supervision and have injected new vitality into various computer vision tasks, benefiting from the rich semantics in text. Therefore, in this work, we propose CLIPER, a unified framework for both static and dynamic facial Expression Recognition based on CLIP. Besides, we introduce multiple expression text descriptors (METD) to learn fine-grained expression representations that make CLIPER more interpretable. We conduct extensive experiments on several popular FER benchmarks and achieve state-of-the-art performance, which demonstrates the effectiveness of CLIPER.
Domain-Unified Prompt Representations for Source-Free Domain Generalization
Sep 29, 2022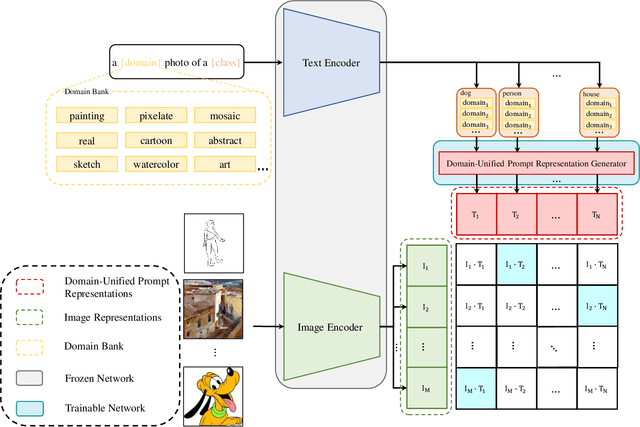
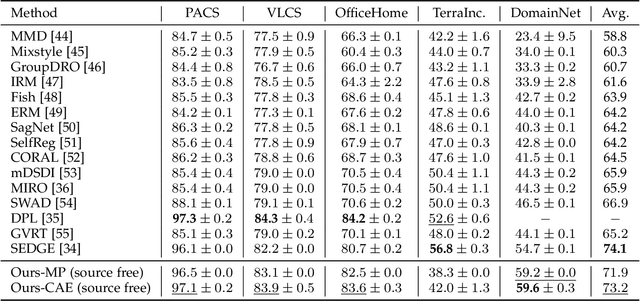
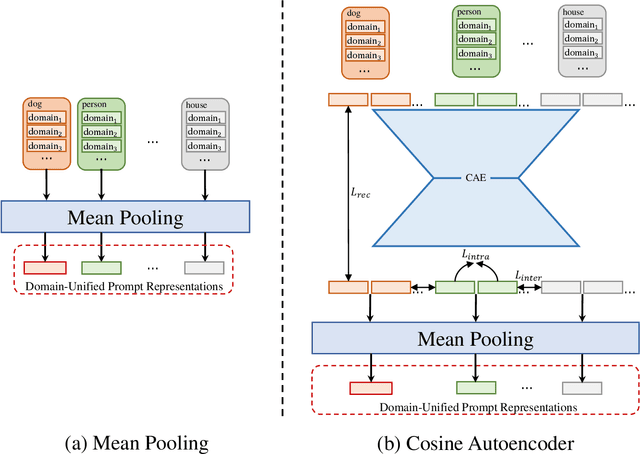

Domain generalization (DG), aiming to make models work on unseen domains, is a surefire way toward general artificial intelligence. Limited by the scale and diversity of current DG datasets, it is difficult for existing methods to scale to diverse domains in open-world scenarios (e.g., science fiction and pixelate style). Therefore, the source-free domain generalization (SFDG) task is necessary and challenging. To address this issue, we propose an approach based on large-scale vision-language pretraining models (e.g., CLIP), which exploits the extensive domain information embedded in it. The proposed scheme generates diverse prompts from a domain bank that contains many more diverse domains than existing DG datasets. Furthermore, our method yields domain-unified representations from these prompts, thus being able to cope with samples from open-world domains. Extensive experiments on mainstream DG datasets, namely PACS, VLCS, OfficeHome, and DomainNet, show that the proposed method achieves competitive performance compared to state-of-the-art (SOTA) DG methods that require source domain data for training. Besides, we collect a small datasets consists of two domains to evaluate the open-world domain generalization ability of the proposed method. The source code and the dataset will be made publicly available at https://github.com/muse1998/Source-Free-Domain-Generalization
Intensity-Aware Loss for Dynamic Facial Expression Recognition in the Wild
Aug 19, 2022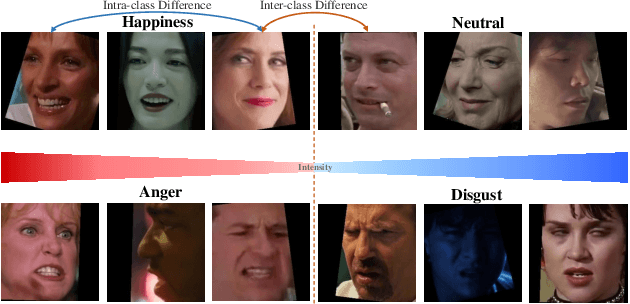
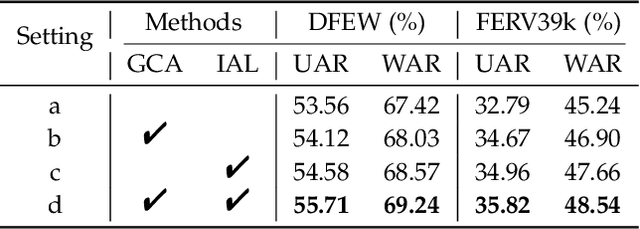
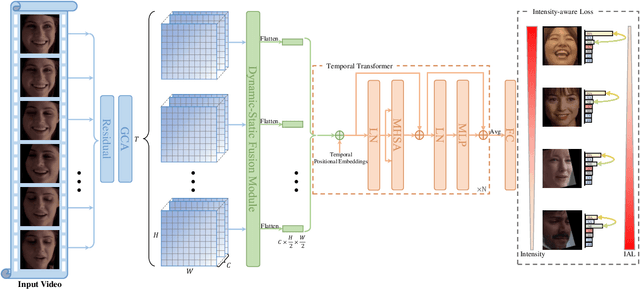
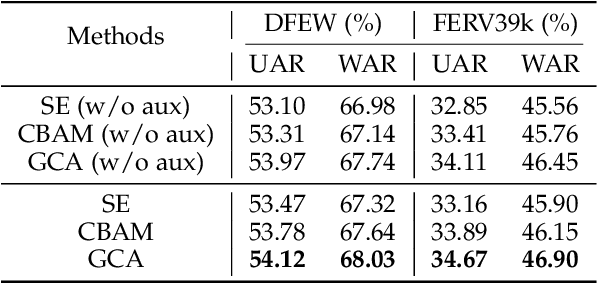
Compared with the image-based static facial expression recognition (SFER) task, the dynamic facial expression recognition (DFER) task based on video sequences is closer to the natural expression recognition scene. However, DFER is often more challenging. One of the main reasons is that video sequences often contain frames with different expression intensities, especially for the facial expressions in the real-world scenarios, while the images in SFER frequently present uniform and high expression intensities. However, if the expressions with different intensities are treated equally, the features learned by the networks will have large intra-class and small inter-class differences, which is harmful to DFER. To tackle this problem, we propose the global convolution-attention block (GCA) to rescale the channels of the feature maps. In addition, we introduce the intensity-aware loss (IAL) in the training process to help the network distinguish the samples with relatively low expression intensities. Experiments on two in-the-wild dynamic facial expression datasets (i.e., DFEW and FERV39k) indicate that our method outperforms the state-of-the-art DFER approaches. The source code will be made publicly available.
NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Jun 10, 2022
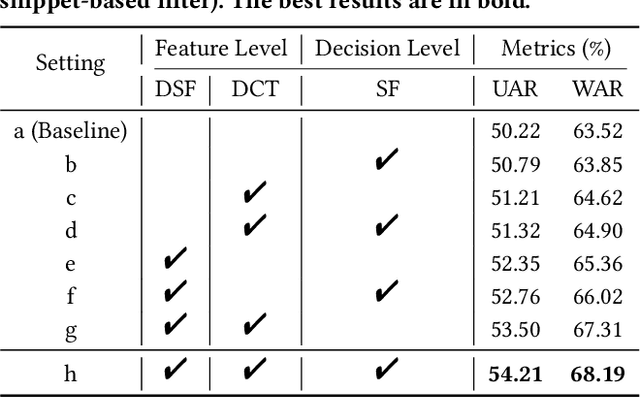
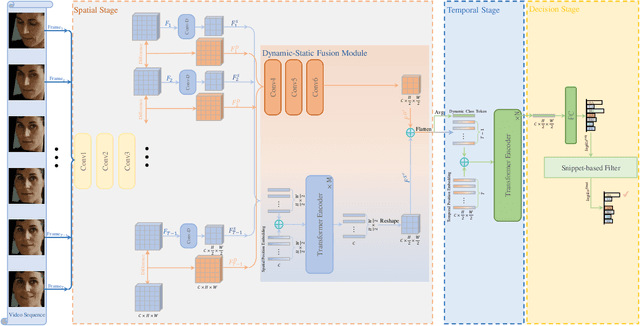
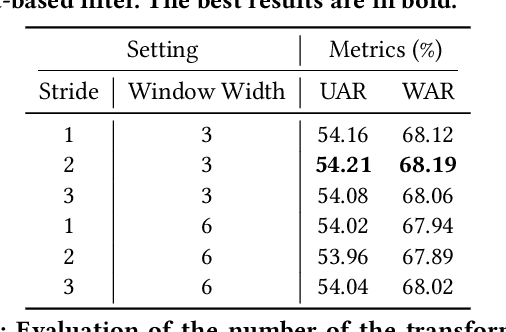
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.
AFNet-M: Adaptive Fusion Network with Masks for 2D+3D Facial Expression Recognition
May 24, 2022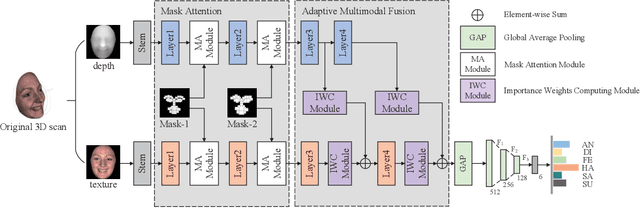
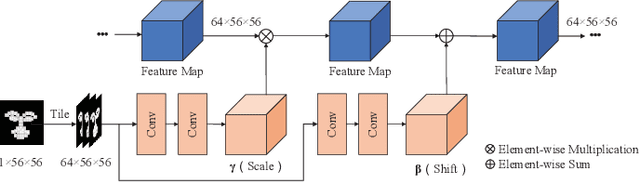
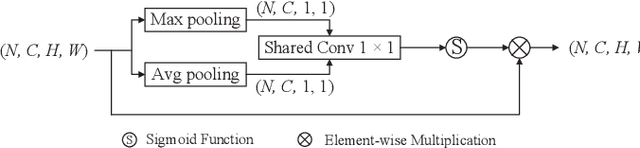
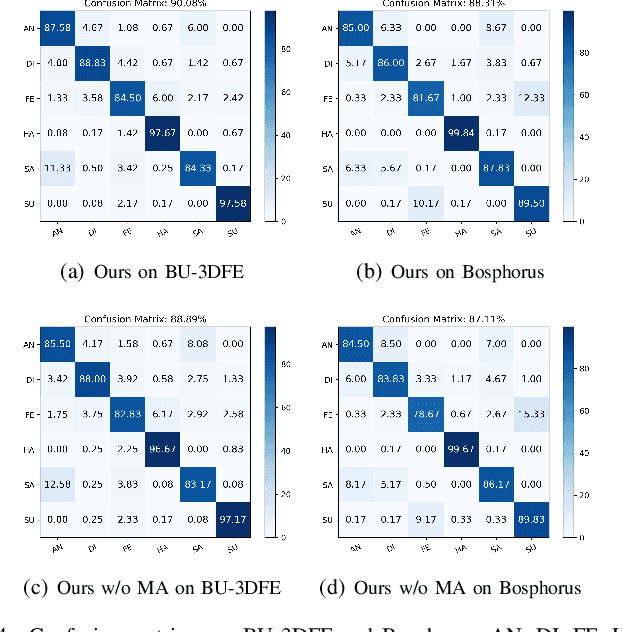
2D+3D facial expression recognition (FER) can effectively cope with illumination changes and pose variations by simultaneously merging 2D texture and more robust 3D depth information. Most deep learning-based approaches employ the simple fusion strategy that concatenates the multimodal features directly after fully-connected layers, without considering the different degrees of significance for each modality. Meanwhile, how to focus on both 2D and 3D local features in salient regions is still a great challenge. In this letter, we propose the adaptive fusion network with masks (AFNet-M) for 2D+3D FER. To enhance 2D and 3D local features, we take the masks annotating salient regions of the face as prior knowledge and design the mask attention module (MA) which can automatically learn two modulation vectors to adjust the feature maps. Moreover, we introduce a novel fusion strategy that can perform adaptive fusion at convolutional layers through the designed importance weights computing module (IWC). Experimental results demonstrate that our AFNet-M achieves the state-of-the-art performance on BU-3DFE and Bosphorus datasets and requires fewer parameters in comparison with other models.
MMNet: Muscle motion-guided network for micro-expression recognition
Jan 14, 2022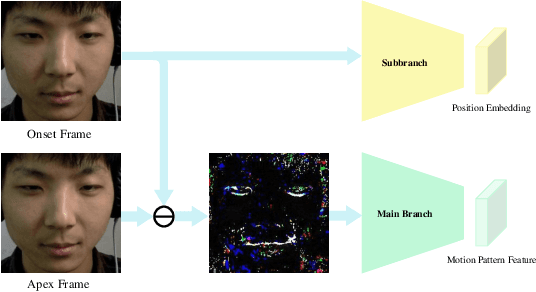
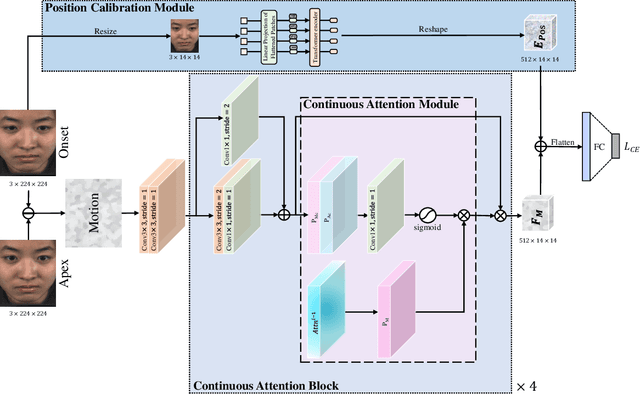
Facial micro-expressions (MEs) are involuntary facial motions revealing peoples real feelings and play an important role in the early intervention of mental illness, the national security, and many human-computer interaction systems. However, existing micro-expression datasets are limited and usually pose some challenges for training good classifiers. To model the subtle facial muscle motions, we propose a robust micro-expression recognition (MER) framework, namely muscle motion-guided network (MMNet). Specifically, a continuous attention (CA) block is introduced to focus on modeling local subtle muscle motion patterns with little identity information, which is different from most previous methods that directly extract features from complete video frames with much identity information. Besides, we design a position calibration (PC) module based on the vision transformer. By adding the position embeddings of the face generated by PC module at the end of the two branches, the PC module can help to add position information to facial muscle motion pattern features for the MER. Extensive experiments on three public micro-expression datasets demonstrate that our approach outperforms state-of-the-art methods by a large margin.
MFEViT: A Robust Lightweight Transformer-based Network for Multimodal 2D+3D Facial Expression Recognition
Sep 20, 2021
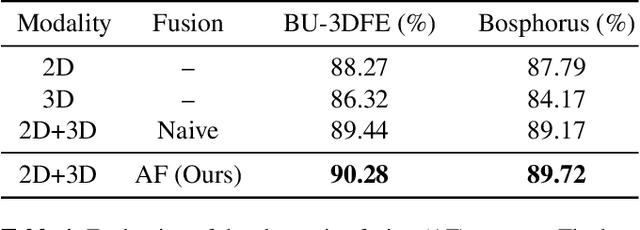
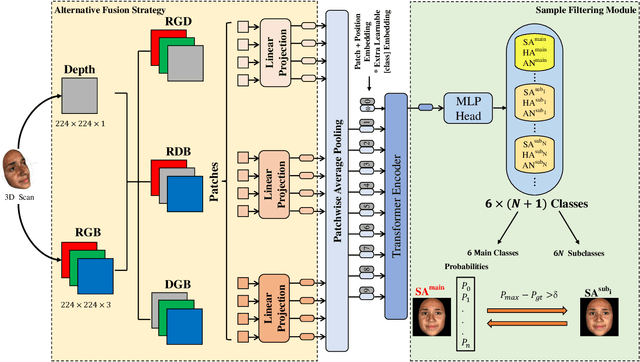
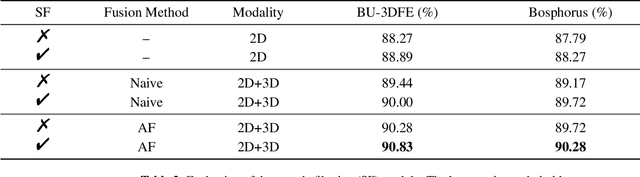
Vision transformer (ViT) has been widely applied in many areas due to its self-attention mechanism that help obtain the global receptive field since the first layer. It even achieves surprising performance exceeding CNN in some vision tasks. However, there exists an issue when leveraging vision transformer into 2D+3D facial expression recognition (FER), i.e., ViT training needs mass data. Nonetheless, the number of samples in public 2D+3D FER datasets is far from sufficient for evaluation. How to utilize the ViT pre-trained on RGB images to handle 2D+3D data becomes a challenge. To solve this problem, we propose a robust lightweight pure transformer-based network for multimodal 2D+3D FER, namely MFEViT. For narrowing the gap between RGB and multimodal data, we devise an alternative fusion strategy, which replaces each of the three channels of an RGB image with the depth-map channel and fuses them before feeding them into the transformer encoder. Moreover, the designed sample filtering module adds several subclasses for each expression and move the noisy samples to their corresponding subclasses, thus eliminating their disturbance on the network during the training stage. Extensive experiments demonstrate that our MFEViT outperforms state-of-the-art approaches with an accuracy of 90.83% on BU-3DFE and 90.28% on Bosphorus. Specifically, the proposed MFEViT is a lightweight model, requiring much fewer parameters than multi-branch CNNs. To the best of our knowledge, this is the first work to introduce vision transformer into multimodal 2D+3D FER. The source code of our MFEViT will be publicly available online.
MViT: Mask Vision Transformer for Facial Expression Recognition in the wild
Jun 08, 2021


Facial Expression Recognition (FER) in the wild is an extremely challenging task in computer vision due to variant backgrounds, low-quality facial images, and the subjectiveness of annotators. These uncertainties make it difficult for neural networks to learn robust features on limited-scale datasets. Moreover, the networks can be easily distributed by the above factors and perform incorrect decisions. Recently, vision transformer (ViT) and data-efficient image transformers (DeiT) present their significant performance in traditional classification tasks. The self-attention mechanism makes transformers obtain a global receptive field in the first layer which dramatically enhances the feature extraction capability. In this work, we first propose a novel pure transformer-based mask vision transformer (MViT) for FER in the wild, which consists of two modules: a transformer-based mask generation network (MGN) to generate a mask that can filter out complex backgrounds and occlusion of face images, and a dynamic relabeling module to rectify incorrect labels in FER datasets in the wild. Extensive experimental results demonstrate that our MViT outperforms state-of-the-art methods on RAF-DB with 88.62%, FERPlus with 89.22%, and AffectNet-7 with 64.57%, respectively, and achieves a comparable result on AffectNet-8 with 61.40%.