 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMFEViT: A Robust Lightweight Transformer-based Network for Multimodal 2D+3D Facial Expression Recognition
Paper and Code
Sep 20, 2021
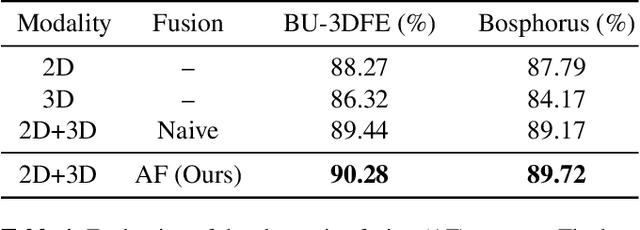
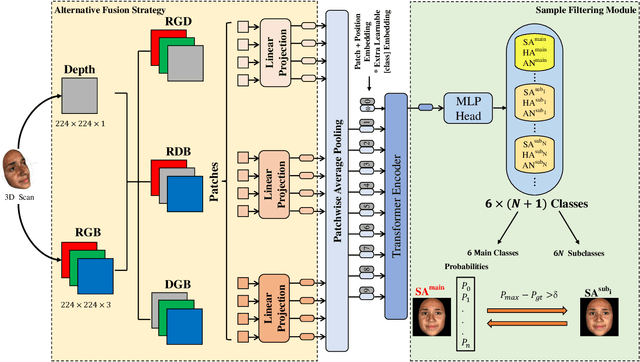
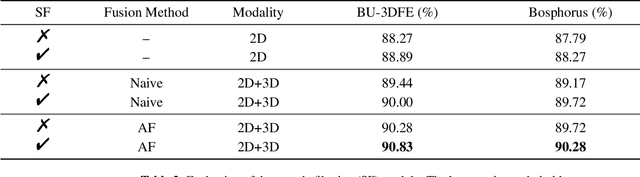
Vision transformer (ViT) has been widely applied in many areas due to its self-attention mechanism that help obtain the global receptive field since the first layer. It even achieves surprising performance exceeding CNN in some vision tasks. However, there exists an issue when leveraging vision transformer into 2D+3D facial expression recognition (FER), i.e., ViT training needs mass data. Nonetheless, the number of samples in public 2D+3D FER datasets is far from sufficient for evaluation. How to utilize the ViT pre-trained on RGB images to handle 2D+3D data becomes a challenge. To solve this problem, we propose a robust lightweight pure transformer-based network for multimodal 2D+3D FER, namely MFEViT. For narrowing the gap between RGB and multimodal data, we devise an alternative fusion strategy, which replaces each of the three channels of an RGB image with the depth-map channel and fuses them before feeding them into the transformer encoder. Moreover, the designed sample filtering module adds several subclasses for each expression and move the noisy samples to their corresponding subclasses, thus eliminating their disturbance on the network during the training stage. Extensive experiments demonstrate that our MFEViT outperforms state-of-the-art approaches with an accuracy of 90.83% on BU-3DFE and 90.28% on Bosphorus. Specifically, the proposed MFEViT is a lightweight model, requiring much fewer parameters than multi-branch CNNs. To the best of our knowledge, this is the first work to introduce vision transformer into multimodal 2D+3D FER. The source code of our MFEViT will be publicly available online.