 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMNet: Muscle motion-guided network for micro-expression recognition
Paper and Code
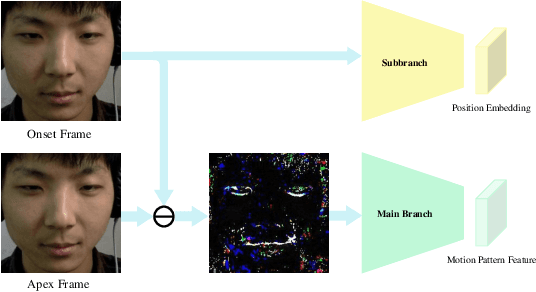
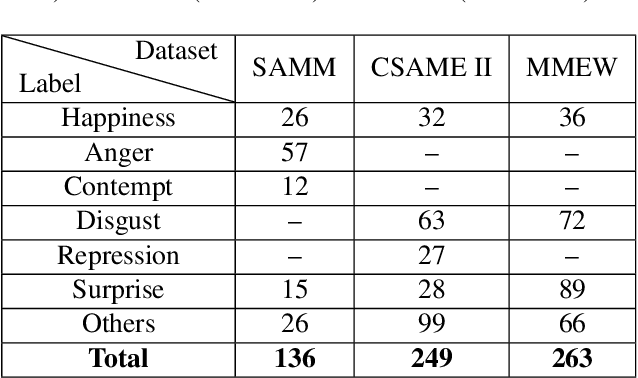
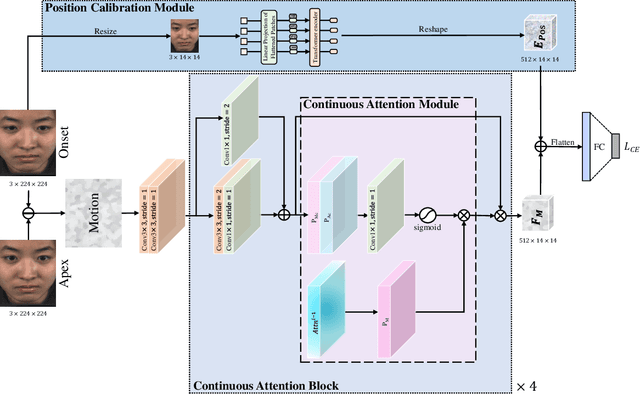
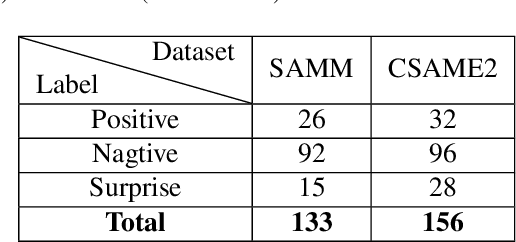
Facial micro-expressions (MEs) are involuntary facial motions revealing peoples real feelings and play an important role in the early intervention of mental illness, the national security, and many human-computer interaction systems. However, existing micro-expression datasets are limited and usually pose some challenges for training good classifiers. To model the subtle facial muscle motions, we propose a robust micro-expression recognition (MER) framework, namely muscle motion-guided network (MMNet). Specifically, a continuous attention (CA) block is introduced to focus on modeling local subtle muscle motion patterns with little identity information, which is different from most previous methods that directly extract features from complete video frames with much identity information. Besides, we design a position calibration (PC) module based on the vision transformer. By adding the position embeddings of the face generated by PC module at the end of the two branches, the PC module can help to add position information to facial muscle motion pattern features for the MER. Extensive experiments on three public micro-expression datasets demonstrate that our approach outperforms state-of-the-art methods by a large margin.