 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMViT: Mask Vision Transformer for Facial Expression Recognition in the wild
Paper and Code
Jun 08, 2021


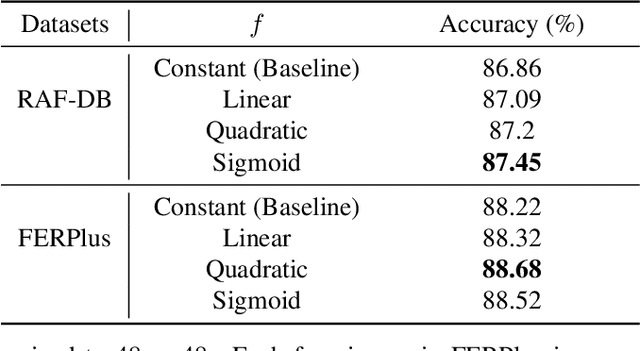
Facial Expression Recognition (FER) in the wild is an extremely challenging task in computer vision due to variant backgrounds, low-quality facial images, and the subjectiveness of annotators. These uncertainties make it difficult for neural networks to learn robust features on limited-scale datasets. Moreover, the networks can be easily distributed by the above factors and perform incorrect decisions. Recently, vision transformer (ViT) and data-efficient image transformers (DeiT) present their significant performance in traditional classification tasks. The self-attention mechanism makes transformers obtain a global receptive field in the first layer which dramatically enhances the feature extraction capability. In this work, we first propose a novel pure transformer-based mask vision transformer (MViT) for FER in the wild, which consists of two modules: a transformer-based mask generation network (MGN) to generate a mask that can filter out complex backgrounds and occlusion of face images, and a dynamic relabeling module to rectify incorrect labels in FER datasets in the wild. Extensive experimental results demonstrate that our MViT outperforms state-of-the-art methods on RAF-DB with 88.62%, FERPlus with 89.22%, and AffectNet-7 with 64.57%, respectively, and achieves a comparable result on AffectNet-8 with 61.40%.