 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeel Robot Feels: Tactile Feedback Array Glove for Dexterous Manipulation
Mar 30, 2026Teleoperation is a key approach for collecting high-quality, physically consistent demonstrations for robotic manipulation. However, teleoperation for dexterous manipulation remains constrained by: (i) inaccurate hand-robot motion mapping, which limits teleoperated dexterity, and (ii) limited tactile feedback that forces vision-dominated interaction and hinders perception of contact geometry and force variation. To address these challenges, we present TAG, a low-cost glove system that integrates precise hand motion capture with high-resolution tactile feedback, enabling effective tactile-in-the-loop dexterous teleoperation. For motion capture, TAG employs a non-contact magnetic sensing design that provides drift-free, electromagnetically robust 21-DoF joint tracking with joint angle estimation errors below 1 degree. Meanwhile, to restore tactile sensation, TAG equips each finger with a 32-actuator tactile array within a compact 2 cm^2 module, allowing operators to directly feel physical interactions at the robot end-effector through spatial activation patterns. Through real-world teleoperation experiments and user studies, we show that TAG enables reliable real-time perception of contact geometry and dynamic force, improves success rates in contact-rich teleoperation tasks, and increases the reliability of demonstration data collection for learning-based manipulation.
NR-DFERNet: Noise-Robust Network for Dynamic Facial Expression Recognition
Jun 10, 2022
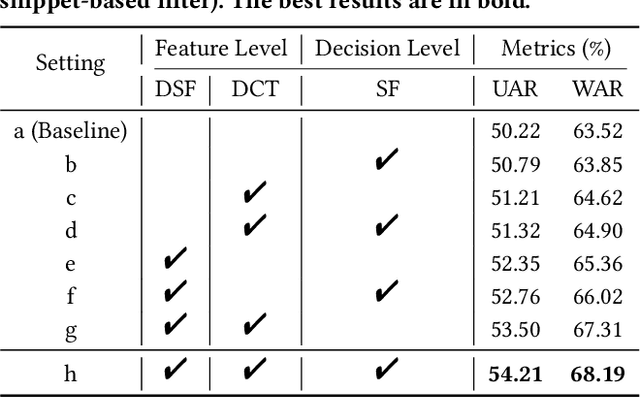
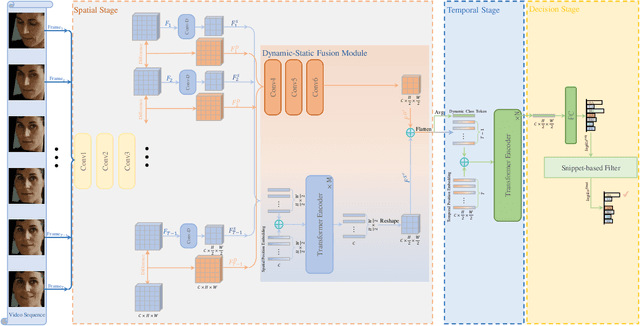
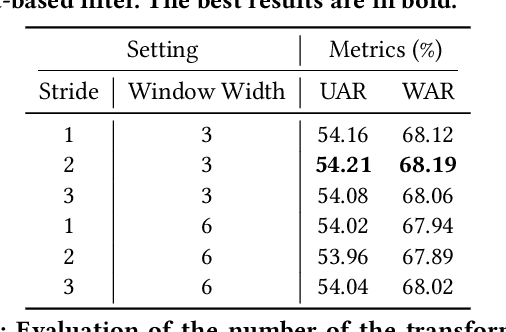
Dynamic facial expression recognition (DFER) in the wild is an extremely challenging task, due to a large number of noisy frames in the video sequences. Previous works focus on extracting more discriminative features, but ignore distinguishing the key frames from the noisy frames. To tackle this problem, we propose a noise-robust dynamic facial expression recognition network (NR-DFERNet), which can effectively reduce the interference of noisy frames on the DFER task. Specifically, at the spatial stage, we devise a dynamic-static fusion module (DSF) that introduces dynamic features to static features for learning more discriminative spatial features. To suppress the impact of target irrelevant frames, we introduce a novel dynamic class token (DCT) for the transformer at the temporal stage. Moreover, we design a snippet-based filter (SF) at the decision stage to reduce the effect of too many neutral frames on non-neutral sequence classification. Extensive experimental results demonstrate that our NR-DFERNet outperforms the state-of-the-art methods on both the DFEW and AFEW benchmarks.