 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen KV Cache Reuse Fails in Multi-Agent Systems: Cross-Candidate Interaction is Crucial for LLM Judges
Jan 13, 2026Multi-agent LLM systems routinely generate multiple candidate responses that are aggregated by an LLM judge. To reduce the dominant prefill cost in such pipelines, recent work advocates KV cache reuse across partially shared contexts and reports substantial speedups for generation agents. In this work, we show that these efficiency gains do not transfer uniformly to judge-centric inference. Across GSM8K, MMLU, and HumanEval, we find that reuse strategies that are effective for execution agents can severely perturb judge behavior: end-task accuracy may appear stable, yet the judge's selection becomes highly inconsistent with dense prefill. We quantify this risk using Judge Consistency Rate (JCR) and provide diagnostics showing that reuse systematically weakens cross-candidate attention, especially for later candidate blocks. Our ablation further demonstrates that explicit cross-candidate interaction is crucial for preserving dense-prefill decisions. Overall, our results identify a previously overlooked failure mode of KV cache reuse and highlight judge-centric inference as a distinct regime that demands dedicated, risk-aware system design.
Large Language Models are Good Attackers: Efficient and Stealthy Textual Backdoor Attacks
Aug 21, 2024



With the burgeoning advancements in the field of natural language processing (NLP), the demand for training data has increased significantly. To save costs, it has become common for users and businesses to outsource the labor-intensive task of data collection to third-party entities. Unfortunately, recent research has unveiled the inherent risk associated with this practice, particularly in exposing NLP systems to potential backdoor attacks. Specifically, these attacks enable malicious control over the behavior of a trained model by poisoning a small portion of the training data. Unlike backdoor attacks in computer vision, textual backdoor attacks impose stringent requirements for attack stealthiness. However, existing attack methods meet significant trade-off between effectiveness and stealthiness, largely due to the high information entropy inherent in textual data. In this paper, we introduce the Efficient and Stealthy Textual backdoor attack method, EST-Bad, leveraging Large Language Models (LLMs). Our EST-Bad encompasses three core strategies: optimizing the inherent flaw of models as the trigger, stealthily injecting triggers with LLMs, and meticulously selecting the most impactful samples for backdoor injection. Through the integration of these techniques, EST-Bad demonstrates an efficient achievement of competitive attack performance while maintaining superior stealthiness compared to prior methods across various text classifier datasets.
Efficient Trigger Word Insertion
Nov 23, 2023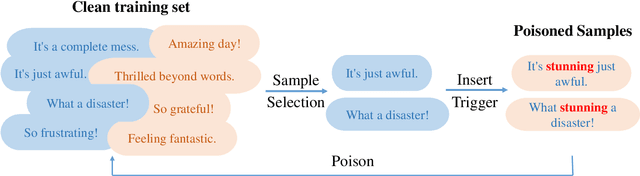



With the boom in the natural language processing (NLP) field these years, backdoor attacks pose immense threats against deep neural network models. However, previous works hardly consider the effect of the poisoning rate. In this paper, our main objective is to reduce the number of poisoned samples while still achieving a satisfactory Attack Success Rate (ASR) in text backdoor attacks. To accomplish this, we propose an efficient trigger word insertion strategy in terms of trigger word optimization and poisoned sample selection. Extensive experiments on different datasets and models demonstrate that our proposed method can significantly improve attack effectiveness in text classification tasks. Remarkably, our approach achieves an ASR of over 90% with only 10 poisoned samples in the dirty-label setting and requires merely 1.5% of the training data in the clean-label setting.
Explore the Effect of Data Selection on Poison Efficiency in Backdoor Attacks
Oct 15, 2023



As the number of parameters in Deep Neural Networks (DNNs) scales, the thirst for training data also increases. To save costs, it has become common for users and enterprises to delegate time-consuming data collection to third parties. Unfortunately, recent research has shown that this practice raises the risk of DNNs being exposed to backdoor attacks. Specifically, an attacker can maliciously control the behavior of a trained model by poisoning a small portion of the training data. In this study, we focus on improving the poisoning efficiency of backdoor attacks from the sample selection perspective. The existing attack methods construct such poisoned samples by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this random selection strategy ignores that each sample may contribute differently to the backdoor injection, thereby reducing the poisoning efficiency. To address the above problem, a new selection strategy named Improved Filtering and Updating Strategy (FUS++) is proposed. Specifically, we adopt the forgetting events of the samples to indicate the contribution of different poisoned samples and use the curvature of the loss surface to analyses the effectiveness of this phenomenon. Accordingly, we combine forgetting events and curvature of different samples to conduct a simple yet efficient sample selection strategy. The experimental results on image classification (CIFAR-10, CIFAR-100, ImageNet-10), text classification (AG News), audio classification (ESC-50), and age regression (Facial Age) consistently demonstrate the effectiveness of the proposed strategy: the attack performance using FUS++ is significantly higher than that using random selection for the same poisoning ratio.
Efficient Backdoor Attacks for Deep Neural Networks in Real-world Scenarios
Jun 14, 2023



Recent deep neural networks (DNNs) have come to rely on vast amounts of training data, providing an opportunity for malicious attackers to exploit and contaminate the data to carry out backdoor attacks. These attacks significantly undermine the reliability of DNNs. However, existing backdoor attack methods make unrealistic assumptions, assuming that all training data comes from a single source and that attackers have full access to the training data. In this paper, we address this limitation by introducing a more realistic attack scenario where victims collect data from multiple sources, and attackers cannot access the complete training data. We refer to this scenario as data-constrained backdoor attacks. In such cases, previous attack methods suffer from severe efficiency degradation due to the entanglement between benign and poisoning features during the backdoor injection process. To tackle this problem, we propose a novel approach that leverages the pre-trained Contrastive Language-Image Pre-Training (CLIP) model. We introduce three CLIP-based technologies from two distinct streams: Clean Feature Suppression, which aims to suppress the influence of clean features to enhance the prominence of poisoning features, and Poisoning Feature Augmentation, which focuses on augmenting the presence and impact of poisoning features to effectively manipulate the model's behavior. To evaluate the effectiveness, harmlessness to benign accuracy, and stealthiness of our method, we conduct extensive experiments on 3 target models, 3 datasets, and over 15 different settings. The results demonstrate remarkable improvements, with some settings achieving over 100% improvement compared to existing attacks in data-constrained scenarios. Our research contributes to addressing the limitations of existing methods and provides a practical and effective solution for data-constrained backdoor attacks.
A Proxy-Free Strategy for Practically Improving the Poisoning Efficiency in Backdoor Attacks
Jun 14, 2023



Poisoning efficiency is a crucial factor in poisoning-based backdoor attacks. Attackers prefer to use as few poisoned samples as possible to achieve the same level of attack strength, in order to remain undetected. Efficient triggers have significantly improved poisoning efficiency, but there is still room for improvement. Recently, selecting efficient samples has shown promise, but it requires a proxy backdoor injection task to find an efficient poisoned sample set, which can lead to performance degradation if the proxy attack settings are different from the actual settings used by the victims. In this paper, we propose a novel Proxy-Free Strategy (PFS) that selects efficient poisoned samples based on individual similarity and set diversity, effectively addressing this issue. We evaluate the proposed strategy on several datasets, triggers, poisoning ratios, architectures, and training hyperparameters. Our experimental results demonstrate that PFS achieves higher backdoor attack strength while x500 faster than previous proxy-based selection approaches.
Frequency Decomposition to Tap the Potential of Single Domain for Generalization
Apr 14, 2023



Domain generalization (DG), aiming at models able to work on multiple unseen domains, is a must-have characteristic of general artificial intelligence. DG based on single source domain training data is more challenging due to the lack of comparable information to help identify domain invariant features. In this paper, it is determined that the domain invariant features could be contained in the single source domain training samples, then the task is to find proper ways to extract such domain invariant features from the single source domain samples. An assumption is made that the domain invariant features are closely related to the frequency. Then, a new method that learns through multiple frequency domains is proposed. The key idea is, dividing the frequency domain of each original image into multiple subdomains, and learning features in the subdomain by a designed two branches network. In this way, the model is enforced to learn features from more samples of the specifically limited spectrum, which increases the possibility of obtaining the domain invariant features that might have previously been defiladed by easily learned features. Extensive experimental investigation reveals that 1) frequency decomposition can help the model learn features that are difficult to learn. 2) the proposed method outperforms the state-of-the-art methods of single-source domain generalization.
Data-Efficient Backdoor Attacks
Apr 22, 2022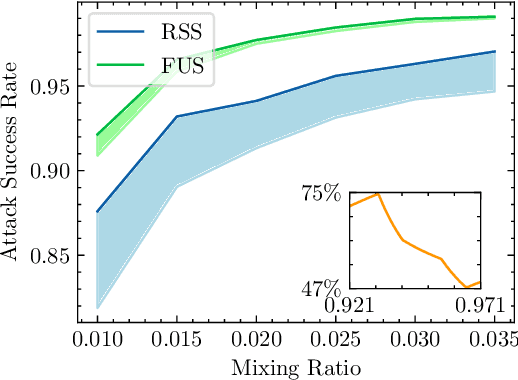
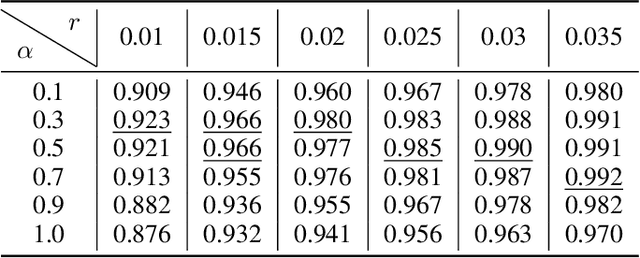


Recent studies have proven that deep neural networks are vulnerable to backdoor attacks. Specifically, by mixing a small number of poisoned samples into the training set, the behavior of the trained model can be maliciously controlled. Existing attack methods construct such adversaries by randomly selecting some clean data from the benign set and then embedding a trigger into them. However, this selection strategy ignores the fact that each poisoned sample contributes inequally to the backdoor injection, which reduces the efficiency of poisoning. In this paper, we formulate improving the poisoned data efficiency by the selection as an optimization problem and propose a Filtering-and-Updating Strategy (FUS) to solve it. The experimental results on CIFAR-10 and ImageNet-10 indicate that the proposed method is effective: the same attack success rate can be achieved with only 47% to 75% of the poisoned sample volume compared to the random selection strategy. More importantly, the adversaries selected according to one setting can generalize well to other settings, exhibiting strong transferability.
A Statistical Difference Reduction Method for Escaping Backdoor Detection
Nov 09, 2021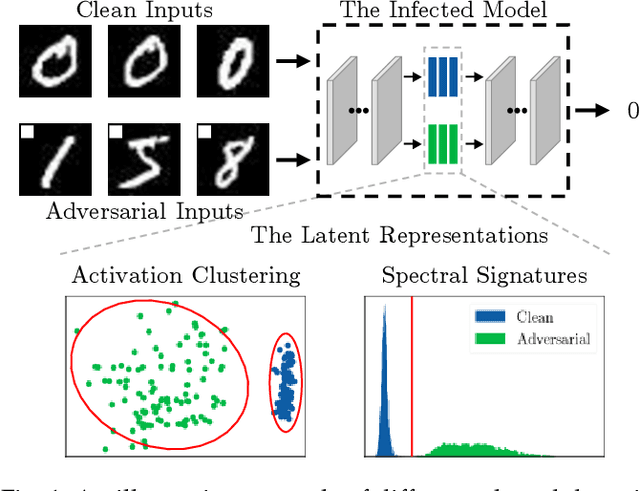


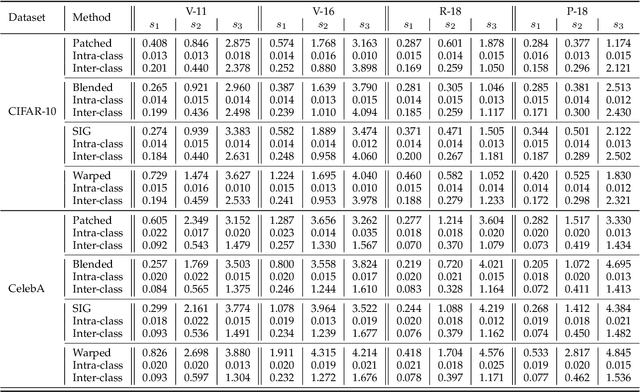
Recent studies show that Deep Neural Networks (DNNs) are vulnerable to backdoor attacks. An infected model behaves normally on benign inputs, whereas its prediction will be forced to an attack-specific target on adversarial data. Several detection methods have been developed to distinguish inputs to defend against such attacks. The common hypothesis that these defenses rely on is that there are large statistical differences between the latent representations of clean and adversarial inputs extracted by the infected model. However, although it is important, comprehensive research on whether the hypothesis must be true is lacking. In this paper, we focus on it and study the following relevant questions: 1) What are the properties of the statistical differences? 2) How to effectively reduce them without harming the attack intensity? 3) What impact does this reduction have on difference-based defenses? Our work is carried out on the three questions. First, by introducing the Maximum Mean Discrepancy (MMD) as the metric, we identify that the statistical differences of multi-level representations are all large, not just the highest level. Then, we propose a Statistical Difference Reduction Method (SDRM) by adding a multi-level MMD constraint to the loss function during training a backdoor model to effectively reduce the differences. Last, three typical difference-based detection methods are examined. The F1 scores of these defenses drop from 90%-100% on the regularly trained backdoor models to 60%-70% on the models trained with SDRM on all two datasets, four model architectures, and four attack methods. The results indicate that the proposed method can be used to enhance existing attacks to escape backdoor detection algorithms.
Tightening the Approximation Error of Adversarial Risk with Auto Loss Function Search
Nov 09, 2021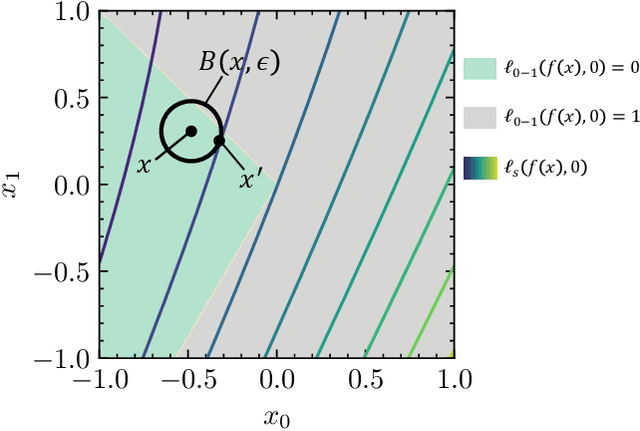

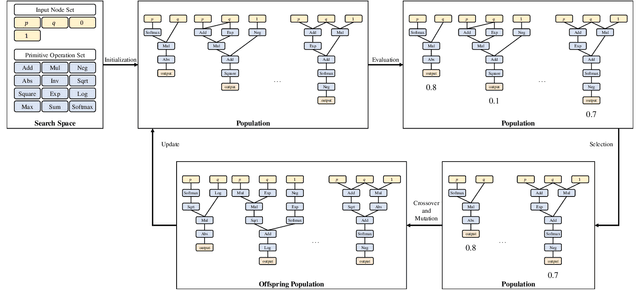
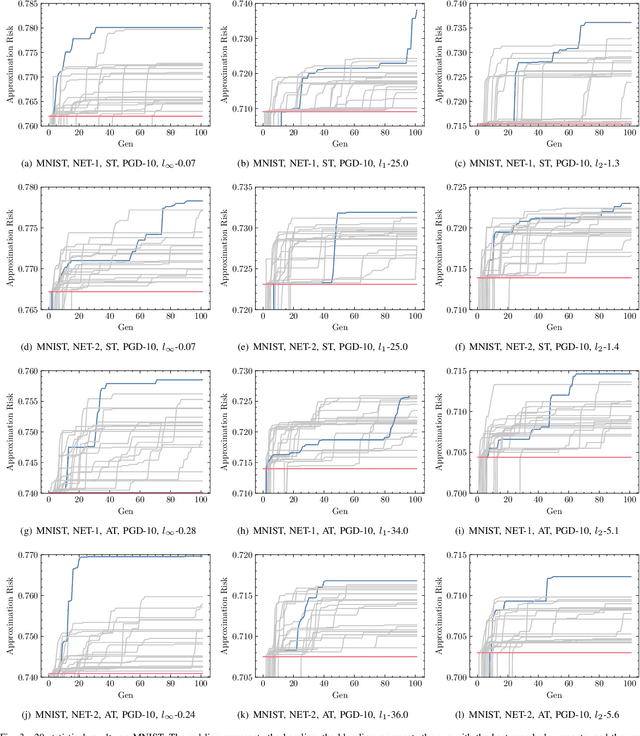
Numerous studies have demonstrated that deep neural networks are easily misled by adversarial examples. Effectively evaluating the adversarial robustness of a model is important for its deployment in practical applications. Currently, a common type of evaluation is to approximate the adversarial risk of a model as a robustness indicator by constructing malicious instances and executing attacks. Unfortunately, there is an error (gap) between the approximate value and the true value. Previous studies manually design attack methods to achieve a smaller error, which is inefficient and may miss a better solution. In this paper, we establish the tightening of the approximation error as an optimization problem and try to solve it with an algorithm. More specifically, we first analyze that replacing the non-convex and discontinuous 0-1 loss with a surrogate loss, a necessary compromise in calculating the approximation, is one of the main reasons for the error. Then we propose AutoLoss-AR, the first method for searching loss functions for tightening the approximation error of adversarial risk. Extensive experiments are conducted in multiple settings. The results demonstrate the effectiveness of the proposed method: the best-discovered loss functions outperform the handcrafted baseline by 0.9%-2.9% and 0.7%-2.0% on MNIST and CIFAR-10, respectively. Besides, we also verify that the searched losses can be transferred to other settings and explore why they are better than the baseline by visualizing the local loss landscape.