 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Exposes the Trigger: Input-Level Backdoor Detection in Text-to-Image Diffusion Models via Cross-Attention Scaling
Apr 14, 2026Text-to-image (T2I) diffusion models have achieved remarkable success in image synthesis, but their reliance on large-scale data and open ecosystems introduces serious backdoor security risks. Existing defenses, particularly input-level methods, are more practical for deployment but often rely on observable anomalies that become unreliable under stealthy, semantics-preserving trigger designs. As modern backdoor attacks increasingly embed triggers into natural inputs, these methods degrade substantially, raising a critical question: can more stable, implicit, and trigger-agnostic differences between benign and backdoor inputs be exploited for detection? In this work, we address this challenge from an active probing perspective. We introduce controlled scaling perturbations on cross-attention and uncover a novel phenomenon termed Cross-Attention Scaling Response Divergence (CSRD), where benign and backdoor inputs exhibit systematically different response evolution patterns across denoising steps. Building on this insight, we propose SET, an input-level backdoor detection framework that constructs response-offset features under multi-scale perturbations and learns a compact benign response space from a small set of clean samples. Detection is then performed by measuring deviations from this learned space, without requiring prior knowledge of the attack or access to model training. Extensive experiments demonstrate that SET consistently outperforms existing baselines across diverse attack methods, trigger types, and model settings, with particularly strong gains under stealthy implicit-trigger scenarios. Overall, SET improves AUROC by 9.1% and ACC by 6.5% over the best baseline, highlighting its effectiveness and robustness for practical deployment.
Semantic Manipulation Localization
Apr 11, 2026Image Manipulation Localization (IML) aims to identify edited regions in an image. However, with the increasing use of modern image editing and generative models, many manipulations no longer exhibit obvious low-level artifacts. Instead, they often involve subtle but meaning-altering edits to an object's attributes, state, or relationships while remaining highly consistent with the surrounding content. This makes conventional IML methods less effective because they mainly rely on artifact detection rather than semantic sensitivity. To address this issue, we introduce Semantic Manipulation Localization (SML), a new task that focuses on localizing subtle semantic edits that significantly change image interpretation. We further construct a dedicated fine-grained benchmark for SML using a semantics-driven manipulation pipeline with pixel-level annotations. Based on this task, we propose TRACE (Targeted Reasoning of Attributed Cognitive Edits), an end-to-end framework that models semantic sensitivity through three progressively coupled components: semantic anchoring, semantic perturbation sensing, and semantic-constrained reasoning. Specifically, TRACE first identifies semantically meaningful regions that support image understanding, then injects perturbation-sensitive frequency cues to capture subtle edits under strong visual consistency, and finally verifies candidate regions through joint reasoning over semantic content and semantic scope. Extensive experiments show that TRACE consistently outperforms existing IML methods on our benchmark and produces more complete, compact, and semantically coherent localization results. These results demonstrate the necessity of moving beyond artifact-based localization and provide a new direction for image forensics in complex semantic editing scenarios.
A H.265/HEVC Fine-Grained ROI Video Encryption Algorithm Based on Coding Unit and Prompt Segmentation
Apr 09, 2026ROI (Region of Interest) video selective encryption based on H.265/HEVC is a technology that protects the sensitive regions of videos by perturbing the syntax elements associated with target areas. However, existing methods typically adopt Tile (with a relatively large size) as the minimum encryption unit, which suffers from problems such as inaccurate encryption regions and low encryption precision. This low-precision encryption makes them difficult to apply in sensitive fields such as medicine, military, and remote sensing. In order to address the aforementioned problem, this paper proposes a fine-grained ROI video selective encryption algorithm based on Coding Units (CUs) and prompt segmentation. First, to achieve a more precise ROI acquisition, we present a novel ROI mapping approach based on prompt segmentation. This approach enables precise mapping of ROIs to small $8\times8$ CU levels, significantly enhancing the precision of encrypted regions. Second, we propose a selective encryption scheme based on multiple syntax elements, which distorts syntax elements within high-precision ROI to effectively safeguard ROI security. Finally, we design a diffusion isolation based on Pulse Code Modulation (PCM) mode and MV restriction, applying PCM mode and MV restriction strategy to the affected CU to address encryption diffusion during prediction. The above three strategies break the inherent mechanism of using Tiles in existing ROI encryption and push the fine-grained level of ROI video encryption to the minimum $8\times8$ CU precision. The experimental results demonstrate that the proposed algorithm can accurately segment ROI regions, effectively perturb pixels within these regions, and eliminate the diffusion artifacts introduced by encryption. The method exhibits great potential for application in medical imaging, military surveillance, and remote areas.
H.265/HEVC Video Steganalysis Based on CU Block Structure Gradients and IPM Mapping
Feb 12, 2026Existing H.265/HEVC video steganalysis research mainly focuses on statistical feature modeling at the levels of motion vectors (MV), intra prediction modes (IPM), or transform coefficients. In contrast, studies targeting the coding-structure level - especially the analysis of block-level steganographic behaviors in Coding Units (CUs) - remain at an early stage. As a core component of H.265/HEVC coding decisions, the CU partition structure often exhibits steganographic perturbations in the form of structural changes and reorganization of prediction relationships, which are difficult to characterize effectively using traditional pixel-domain features or mode statistics. To address this issue, this paper, for the first time from the perspective of CU block-level steganalysis, proposes an H.265/HEVC video steganalysis method based on CU block-structure gradients and intra prediction mode mapping. The proposed method constructs a CU block-structure gradient map to explicitly describe changes in coding-unit partitioning, and combines it with a block-level mapping representation of IPM to jointly model the structural perturbations introduced by CU-level steganographic embedding. On this basis, we design a Transformer network, GradIPMFormer, tailored for CU-block steganalysis, thereby effectively enhancing the capability to perceive CU-level steganographic behaviors. Experimental results show that under different quantization parameters and resolution settings, the proposed method consistently achieves superior detection performance across multiple H.265/HEVC steganographic algorithms, validating the feasibility and effectiveness of conducting video steganalysis from the coding-structure perspective. This study provides a new CU block-level analysis paradigm for H.265/HEVC video steganalysis and has significant research value for covert communication security detection.
Breaking the Reasoning Horizon in Entity Alignment Foundation Models
Jan 29, 2026Entity alignment (EA) is critical for knowledge graph (KG) fusion. Existing EA models lack transferability and are incapable of aligning unseen KGs without retraining. While using graph foundation models (GFMs) offer a solution, we find that directly adapting GFMs to EA remains largely ineffective. This stems from a critical "reasoning horizon gap": unlike link prediction in GFMs, EA necessitates capturing long-range dependencies across sparse and heterogeneous KG structuresTo address this challenge, we propose a EA foundation model driven by a parallel encoding strategy. We utilize seed EA pairs as local anchors to guide the information flow, initializing and encoding two parallel streams simultaneously. This facilitates anchor-conditioned message passing and significantly shortens the inference trajectory by leveraging local structural proximity instead of global search. Additionally, we incorporate a merged relation graph to model global dependencies and a learnable interaction module for precise matching. Extensive experiments verify the effectiveness of our framework, highlighting its strong generalizability to unseen KGs.
Breaking the Resolution Barrier: Arbitrary-resolution Deep Image Steganography Framework
Jan 22, 2026Deep image steganography (DIS) has achieved significant results in capacity and invisibility. However, current paradigms enforce the secret image to maintain the same resolution as the cover image during hiding and revealing. This leads to two challenges: secret images with inconsistent resolutions must undergo resampling beforehand which results in detail loss during recovery, and the secret image cannot be recovered to its original resolution when the resolution value is unknown. To address these, we propose ARDIS, the first Arbitrary Resolution DIS framework, which shifts the paradigm from discrete mapping to reference-guided continuous signal reconstruction. Specifically, to minimize the detail loss caused by resolution mismatch, we first design a Frequency Decoupling Architecture in hiding stage. It disentangles the secret into a resolution-aligned global basis and a resolution-agnostic high-frequency latent to hide in a fixed-resolution cover. Second, for recovery, we propose a Latent-Guided Implicit Reconstructor to perform deterministic restoration. The recovered detail latent code modulates a continuous implicit function to accurately query and render high-frequency residuals onto the recovered global basis, ensuring faithful restoration of original details. Furthermore, to achieve blind recovery, we introduce an Implicit Resolution Coding strategy. By transforming discrete resolution values into dense feature maps and hiding them in the redundant space of the feature domain, the reconstructor can correctly decode the secret's resolution directly from the steganographic representation. Experimental results demonstrate that ARDIS significantly outperforms state-of-the-art methods in both invisibility and cross-resolution recovery fidelity.
From Spurious to Causal: Low-rank Orthogonal Subspace Intervention for Generalizable Face Forgery Detection
Jan 17, 2026The generalization problem remains a critical challenge in face forgery detection. Some researches have discovered that ``a backdoor path" in the representations from forgery-irrelevant information to labels induces biased learning, thereby hindering the generalization. In this paper, these forgery-irrelevant information are collectively termed spurious correlations factors. Previous methods predominantly focused on identifying concrete, specific spurious correlation and designing corresponding solutions to address them. However, spurious correlations arise from unobservable confounding factors, making it impractical to identify and address each one individually. To address this, we propose an intervention paradigm for representation space. Instead of tracking and blocking various instance-level spurious correlation one by one, we uniformly model them as a low-rank subspace and intervene in them. Specifically, we decompose spurious correlation features into a low-rank subspace via orthogonal low-rank projection, subsequently removing this subspace from the original representation and training its orthogonal complement to capture forgery-related features. This low-rank projection removal effectively eliminates spurious correlation factors, ensuring that classification decision is based on authentic forgery cues. With only 0.43M trainable parameters, our method achieves state-of-the-art performance across several benchmarks, demonstrating excellent robustness and generalization.
Deepfake Detection with Multi-Artifact Subspace Fine-Tuning and Selective Layer Masking
Jan 03, 2026Deepfake detection still faces significant challenges in cross-dataset and real-world complex scenarios. The root cause lies in the high diversity of artifact distributions introduced by different forgery methods, while pretrained models tend to disrupt their original general semantic structures when adapting to new artifacts. Existing approaches usually rely on indiscriminate global parameter updates or introduce additional supervision signals, making it difficult to effectively model diverse forgery artifacts while preserving semantic stability. To address these issues, this paper proposes a deepfake detection method based on Multi-Artifact Subspaces and selective layer masks (MASM), which explicitly decouples semantic representations from artifact representations and constrains the fitting strength of artifact subspaces, thereby improving generalization robustness in cross-dataset scenarios. Specifically, MASM applies singular value decomposition to model weights, partitioning pretrained weights into a stable semantic principal subspace and multiple learnable artifact subspaces. This design enables decoupled modeling of different forgery artifact patterns while preserving the general semantic subspace. On this basis, a selective layer mask strategy is introduced to adaptively regulate the update behavior of corresponding network layers according to the learning state of each artifact subspace, suppressing overfitting to any single forgery characteristic. Furthermore, orthogonality constraints and spectral consistency constraints are imposed to jointly regularize multiple artifact subspaces, guiding them to learn complementary and diverse artifact representations while maintaining a stable overall spectral structure.
DGS-Net: Distillation-Guided Gradient Surgery for CLIP Fine-Tuning in AI-Generated Image Detection
Nov 17, 2025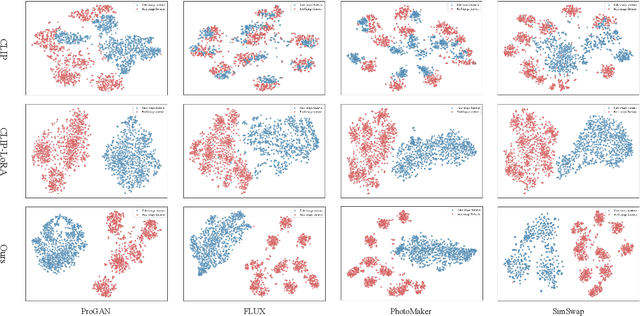
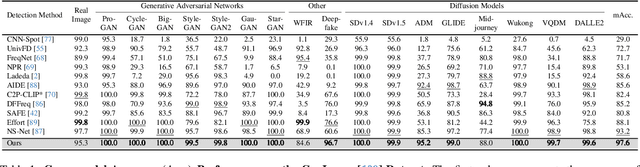
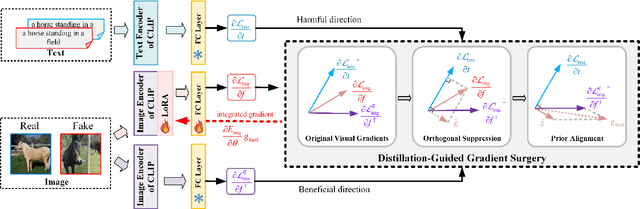
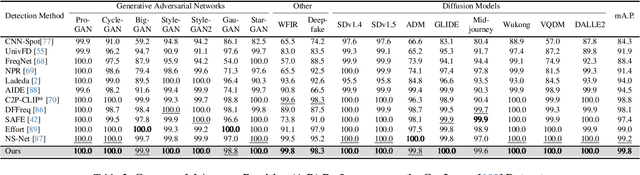
The rapid progress of generative models such as GANs and diffusion models has led to the widespread proliferation of AI-generated images, raising concerns about misinformation, privacy violations, and trust erosion in digital media. Although large-scale multimodal models like CLIP offer strong transferable representations for detecting synthetic content, fine-tuning them often induces catastrophic forgetting, which degrades pre-trained priors and limits cross-domain generalization. To address this issue, we propose the Distillation-guided Gradient Surgery Network (DGS-Net), a novel framework that preserves transferable pre-trained priors while suppressing task-irrelevant components. Specifically, we introduce a gradient-space decomposition that separates harmful and beneficial descent directions during optimization. By projecting task gradients onto the orthogonal complement of harmful directions and aligning with beneficial ones distilled from a frozen CLIP encoder, DGS-Net achieves unified optimization of prior preservation and irrelevant suppression. Extensive experiments on 50 generative models demonstrate that our method outperforms state-of-the-art approaches by an average margin of 6.6, achieving superior detection performance and generalization across diverse generation techniques.
A Visual Perception-Based Tunable Framework and Evaluation Benchmark for H.265/HEVC ROI Encryption
Nov 09, 2025ROI selective encryption, as an efficient privacy protection technique, encrypts only the key regions in the video, thereby ensuring security while minimizing the impact on coding efficiency. However, existing ROI-based video encryption methods suffer from insufficient flexibility and lack of a unified evaluation system. To address these issues, we propose a visual perception-based tunable framework and evaluation benchmark for H.265/HEVC ROI encryption. Our scheme introduces three key contributions: 1) A ROI region recognition module based on visual perception network is proposed to accurately identify the ROI region in videos. 2) A three-level tunable encryption strategy is implemented while balancing security and real-time performance. 3) A unified ROI encryption evaluation benchmark is developed to provide a standardized quantitative platform for subsequent research. This triple strategy provides new solution and significant unified performance evaluation methods for ROI selective encryption field. Experimental results indicate that the proposed benchmark can comprehensively measure the performance of the ROI selective encryption. Compared to existing ROI encryption algorithms, our proposed enhanced and advanced level encryption exhibit superior performance in multiple performance metrics. In general, the proposed framework effectively meets the privacy protection requirements in H.265/HEVC and provides a reliable solution for secure and efficient processing of sensitive video content.