 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention
Sep 16, 2022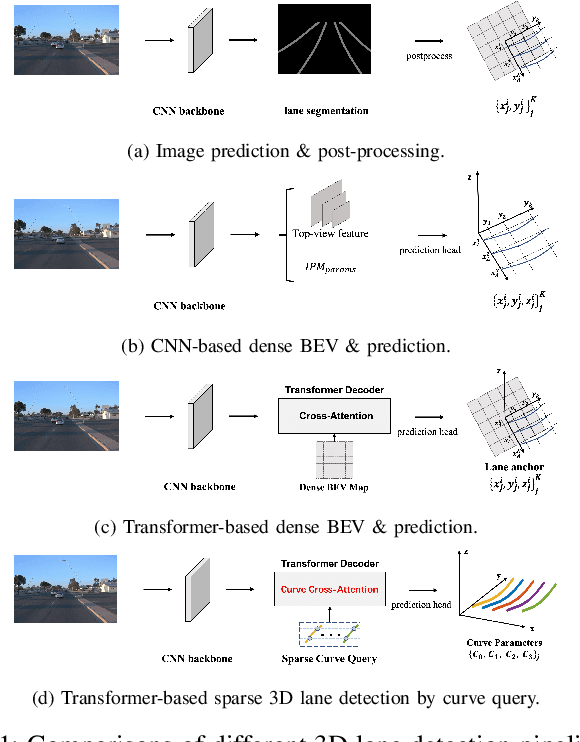
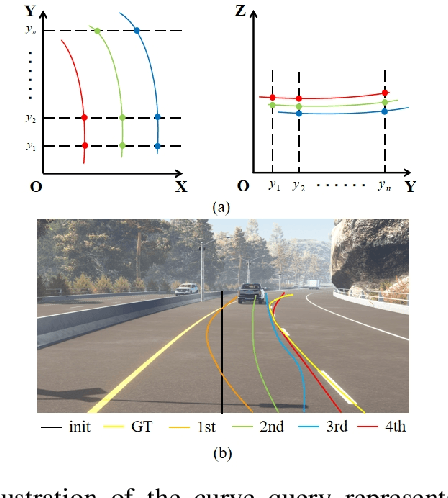
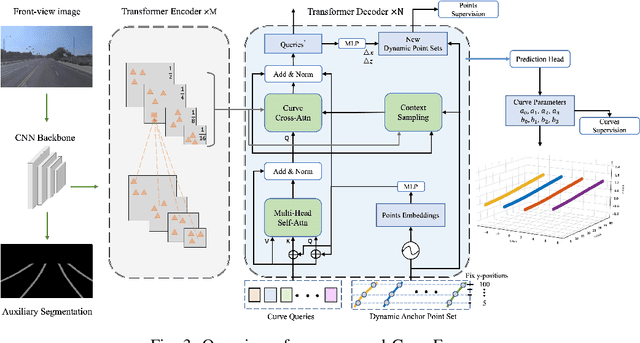
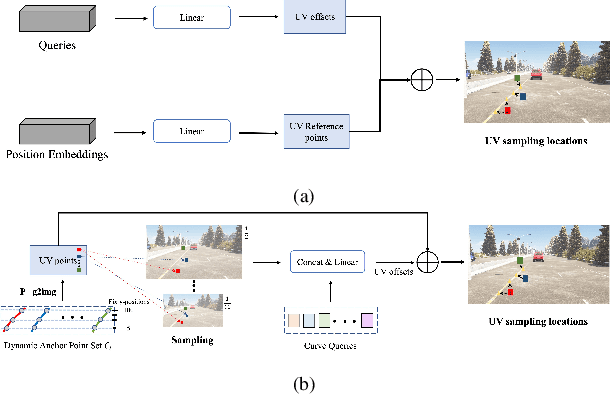
3D lane detection is an integral part of autonomous driving systems. Previous CNN and Transformer-based methods usually first generate a bird's-eye-view (BEV) feature map from the front view image, and then use a sub-network with BEV feature map as input to predict 3D lanes. Such approaches require an explicit view transformation between BEV and front view, which itself is still a challenging problem. In this paper, we propose CurveFormer, a single-stage Transformer-based method that directly calculates 3D lane parameters and can circumvent the difficult view transformation step. Specifically, we formulate 3D lane detection as a curve propagation problem by using curve queries. A 3D lane query is represented by a dynamic and ordered anchor point set. In this way, queries with curve representation in Transformer decoder iteratively refine the 3D lane detection results. Moreover, a curve cross-attention module is introduced to compute the similarities between curve queries and image features. Additionally, a context sampling module that can capture more relative image features of a curve query is provided to further boost the 3D lane detection performance. We evaluate our method for 3D lane detection on both synthetic and real-world datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well.
BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs
Mar 13, 2022


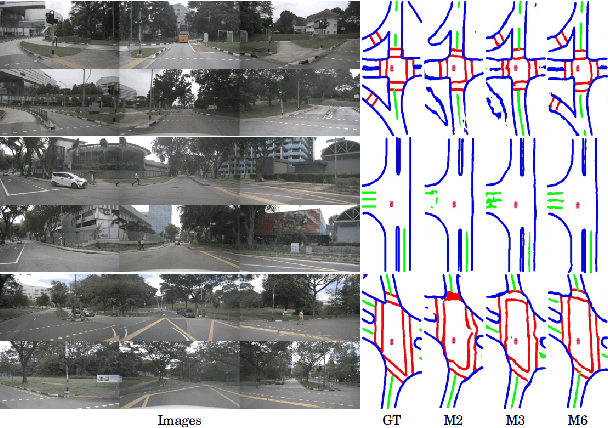
Semantic segmentation in bird's eye view (BEV) is an important task for autonomous driving. Though this task has attracted a large amount of research efforts, it is still challenging to flexibly cope with arbitrary (single or multiple) camera sensors equipped on the autonomous vehicle. In this paper, we present BEVSegFormer, an effective transformer-based method for BEV semantic segmentation from arbitrary camera rigs. Specifically, our method first encodes image features from arbitrary cameras with a shared backbone. These image features are then enhanced by a deformable transformer-based encoder. Moreover, we introduce a BEV transformer decoder module to parse BEV semantic segmentation results. An efficient multi-camera deformable attention unit is designed to carry out the BEV-to-image view transformation. Finally, the queries are reshaped according the layout of grids in the BEV, and upsampled to produce the semantic segmentation result in a supervised manner. We evaluate the proposed algorithm on the public nuScenes dataset and a self-collected dataset. Experimental results show that our method achieves promising performance on BEV semantic segmentation from arbitrary camera rigs. We also demonstrate the effectiveness of each component via ablation study.