 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Modal Assistance for Unsupervised Domain Adaptation on Point Cloud 3D Object Detection
Nov 11, 2025Unsupervised domain adaptation for LiDAR-based 3D object detection (3D UDA) based on the teacher-student architecture with pseudo labels has achieved notable improvements in recent years. Although it is quite popular to collect point clouds and images simultaneously, little attention has been paid to the usefulness of image data in 3D UDA when training the models. In this paper, we propose an approach named MMAssist that improves the performance of 3D UDA with multi-modal assistance. A method is designed to align 3D features between the source domain and the target domain by using image and text features as bridges. More specifically, we project the ground truth labels or pseudo labels to the images to get a set of 2D bounding boxes. For each 2D box, we extract its image feature from a pre-trained vision backbone. A large vision-language model (LVLM) is adopted to extract the box's text description, and a pre-trained text encoder is used to obtain its text feature. During the training of the model in the source domain and the student model in the target domain, we align the 3D features of the predicted boxes with their corresponding image and text features, and the 3D features and the aligned features are fused with learned weights for the final prediction. The features between the student branch and the teacher branch in the target domain are aligned as well. To enhance the pseudo labels, we use an off-the-shelf 2D object detector to generate 2D bounding boxes from images and estimate their corresponding 3D boxes with the aid of point cloud, and these 3D boxes are combined with the pseudo labels generated by the teacher model. Experimental results show that our approach achieves promising performance compared with state-of-the-art methods in three domain adaptation tasks on three popular 3D object detection datasets. The code is available at https://github.com/liangp/MMAssist.
Enhancing 3D Object Detection with 2D Detection-Guided Query Anchors
Mar 10, 2024
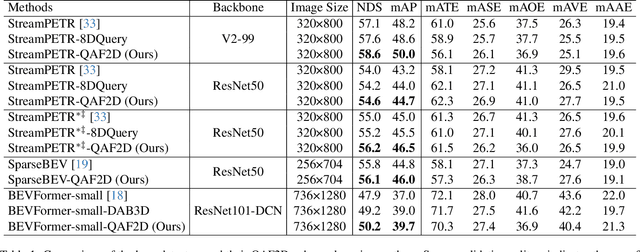
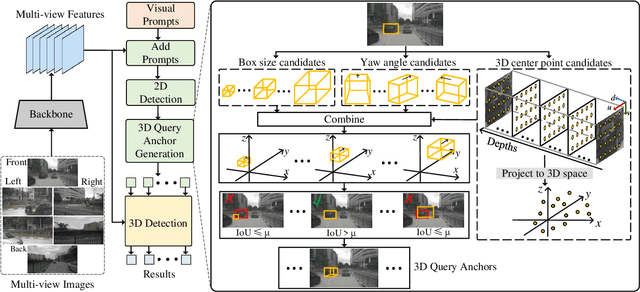

Multi-camera-based 3D object detection has made notable progress in the past several years. However, we observe that there are cases (e.g. faraway regions) in which popular 2D object detectors are more reliable than state-of-the-art 3D detectors. In this paper, to improve the performance of query-based 3D object detectors, we present a novel query generating approach termed QAF2D, which infers 3D query anchors from 2D detection results. A 2D bounding box of an object in an image is lifted to a set of 3D anchors by associating each sampled point within the box with depth, yaw angle, and size candidates. Then, the validity of each 3D anchor is verified by comparing its projection in the image with its corresponding 2D box, and only valid anchors are kept and used to construct queries. The class information of the 2D bounding box associated with each query is also utilized to match the predicted boxes with ground truth for the set-based loss. The image feature extraction backbone is shared between the 3D detector and 2D detector by adding a small number of prompt parameters. We integrate QAF2D into three popular query-based 3D object detectors and carry out comprehensive evaluations on the nuScenes dataset. The largest improvement that QAF2D can bring about on the nuScenes validation subset is $2.3\%$ NDS and $2.7\%$ mAP. Code is available at https://github.com/nullmax-vision/QAF2D.
CurveFormer++: 3D Lane Detection by Curve Propagation with Temporal Curve Queries and Attention
Feb 09, 2024In autonomous driving, 3D lane detection using monocular cameras is an important task for various downstream planning and control tasks. Recent CNN and Transformer approaches usually apply a two-stage scheme in the model design. The first stage transforms the image feature from a front image into a bird's-eye-view (BEV) representation. Subsequently, a sub-network processes the BEV feature map to generate the 3D detection results. However, these approaches heavily rely on a challenging image feature transformation module from a perspective view to a BEV representation. In our work, we present CurveFormer++, a single-stage Transformer-based method that does not require the image feature view transform module and directly infers 3D lane detection results from the perspective image features. Specifically, our approach models the 3D detection task as a curve propagation problem, where each lane is represented by a curve query with a dynamic and ordered anchor point set. By employing a Transformer decoder, the model can iteratively refine the 3D lane detection results. A curve cross-attention module is introduced in the Transformer decoder to calculate similarities between image features and curve queries of lanes. To handle varying lane lengths, we employ context sampling and anchor point restriction techniques to compute more relevant image features for a curve query. Furthermore, we apply a temporal fusion module that incorporates selected informative sparse curve queries and their corresponding anchor point sets to leverage historical lane information. In the experiments, we evaluate our approach for the 3D lane detection task on two publicly available real-world datasets. The results demonstrate that our method provides outstanding performance compared with both CNN and Transformer based methods. We also conduct ablation studies to analyze the impact of each component in our approach.
Multi-Correlation Siamese Transformer Network with Dense Connection for 3D Single Object Tracking
Dec 18, 2023



Point cloud-based 3D object tracking is an important task in autonomous driving. Though great advances regarding Siamese-based 3D tracking have been made recently, it remains challenging to learn the correlation between the template and search branches effectively with the sparse LIDAR point cloud data. Instead of performing correlation of the two branches at just one point in the network, in this paper, we present a multi-correlation Siamese Transformer network that has multiple stages and carries out feature correlation at the end of each stage based on sparse pillars. More specifically, in each stage, self-attention is first applied to each branch separately to capture the non-local context information. Then, cross-attention is used to inject the template information into the search area. This strategy allows the feature learning of the search area to be aware of the template while keeping the individual characteristics of the template intact. To enable the network to easily preserve the information learned at different stages and ease the optimization, for the search area, we densely connect the initial input sparse pillars and the output of each stage to all subsequent stages and the target localization network, which converts pillars to bird's eye view (BEV) feature maps and predicts the state of the target with a small densely connected convolution network. Deep supervision is added to each stage to further boost the performance as well. The proposed algorithm is evaluated on the popular KITTI, nuScenes, and Waymo datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art. Ablation study that shows the effectiveness of each component is provided as well. Code is available at https://github.com/liangp/MCSTN-3DSOT.
* Preprint version for IEEE Robotics and Automation Letters (RAL)
CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention
Aug 31, 2023



Both CNN-based and Transformer-based object detection with bounding box representation have been extensively studied in computer vision and medical image analysis, but circular object detection in medical images is still underexplored. Inspired by the recent anchor free CNN-based circular object detection method (CircleNet) for ball-shape glomeruli detection in renal pathology, in this paper, we present CircleFormer, a Transformer-based circular medical object detection with dynamic anchor circles. Specifically, queries with circle representation in Transformer decoder iteratively refine the circular object detection results, and a circle cross attention module is introduced to compute the similarity between circular queries and image features. A generalized circle IoU (gCIoU) is proposed to serve as a new regression loss of circular object detection as well. Moreover, our approach is easy to generalize to the segmentation task by adding a simple segmentation branch to CircleFormer. We evaluate our method in circular nuclei detection and segmentation on the public MoNuSeg dataset, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well. Our code is released at https://github.com/zhanghx-iim-ahu/CircleFormer.
CurveFormer: 3D Lane Detection by Curve Propagation with Curve Queries and Attention
Sep 16, 2022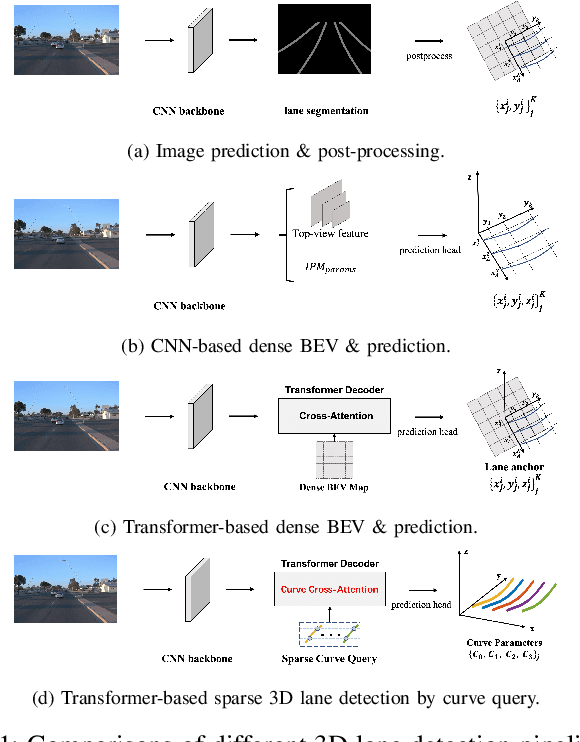
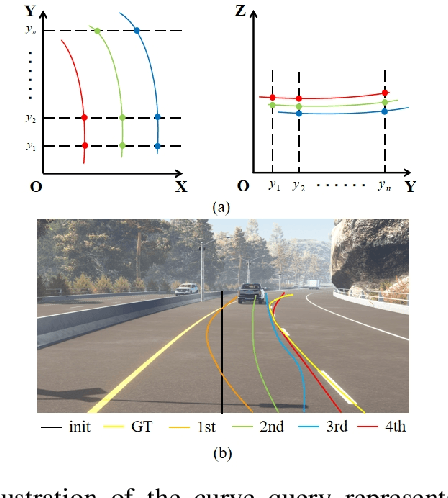
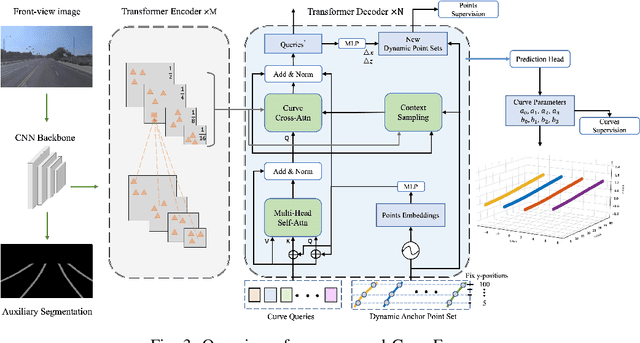
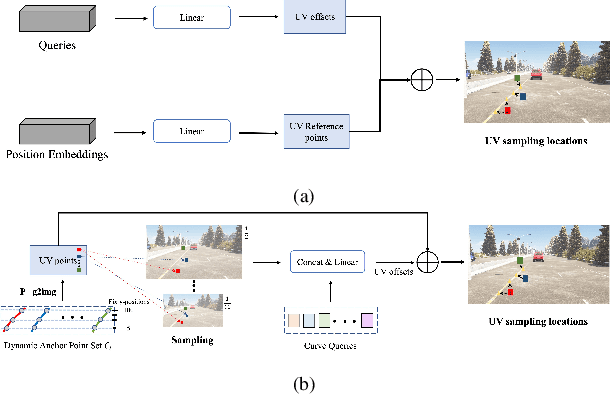
3D lane detection is an integral part of autonomous driving systems. Previous CNN and Transformer-based methods usually first generate a bird's-eye-view (BEV) feature map from the front view image, and then use a sub-network with BEV feature map as input to predict 3D lanes. Such approaches require an explicit view transformation between BEV and front view, which itself is still a challenging problem. In this paper, we propose CurveFormer, a single-stage Transformer-based method that directly calculates 3D lane parameters and can circumvent the difficult view transformation step. Specifically, we formulate 3D lane detection as a curve propagation problem by using curve queries. A 3D lane query is represented by a dynamic and ordered anchor point set. In this way, queries with curve representation in Transformer decoder iteratively refine the 3D lane detection results. Moreover, a curve cross-attention module is introduced to compute the similarities between curve queries and image features. Additionally, a context sampling module that can capture more relative image features of a curve query is provided to further boost the 3D lane detection performance. We evaluate our method for 3D lane detection on both synthetic and real-world datasets, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well.
Traffic Context Aware Data Augmentation for Rare Object Detection in Autonomous Driving
May 01, 2022
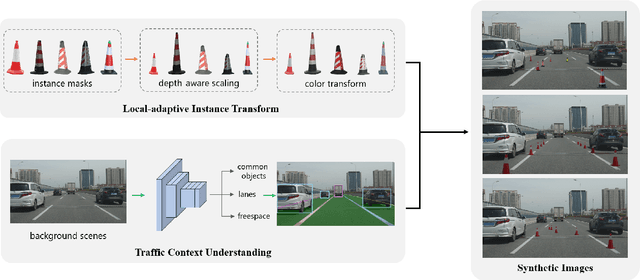


Detection of rare objects (e.g., traffic cones, traffic barrels and traffic warning triangles) is an important perception task to improve the safety of autonomous driving. Training of such models typically requires a large number of annotated data which is expensive and time consuming to obtain. To address the above problem, an emerging approach is to apply data augmentation to automatically generate cost-free training samples. In this work, we propose a systematic study on simple Copy-Paste data augmentation for rare object detection in autonomous driving. Specifically, local adaptive instance-level image transformation is introduced to generate realistic rare object masks from source domain to the target domain. Moreover, traffic scene context is utilized to guide the placement of masks of rare objects. To this end, our data augmentation generates training data with high quality and realistic characteristics by leveraging both local and global consistency. In addition, we build a new dataset named NM10k consisting 10k training images, 4k validation images and the corresponding labels with a diverse range of scenarios in autonomous driving. Experiments on NM10k show that our method achieves promising results on rare object detection. We also present a thorough study to illustrate the effectiveness of our local-adaptive and global constraints based Copy-Paste data augmentation for rare object detection. The data, development kit and more information of NM10k dataset are available online at: \url{https://nullmax-vision.github.io}.
BEVSegFormer: Bird's Eye View Semantic Segmentation From Arbitrary Camera Rigs
Mar 13, 2022


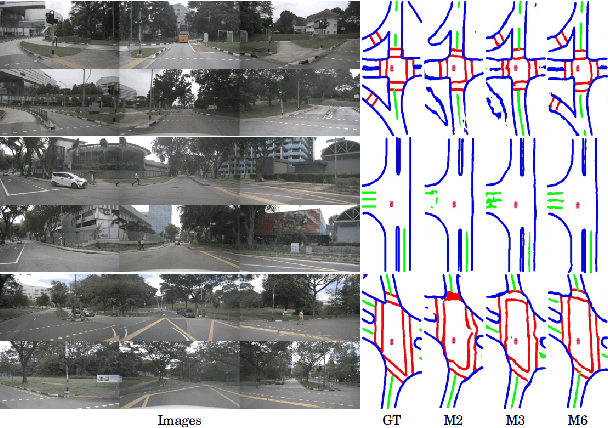
Semantic segmentation in bird's eye view (BEV) is an important task for autonomous driving. Though this task has attracted a large amount of research efforts, it is still challenging to flexibly cope with arbitrary (single or multiple) camera sensors equipped on the autonomous vehicle. In this paper, we present BEVSegFormer, an effective transformer-based method for BEV semantic segmentation from arbitrary camera rigs. Specifically, our method first encodes image features from arbitrary cameras with a shared backbone. These image features are then enhanced by a deformable transformer-based encoder. Moreover, we introduce a BEV transformer decoder module to parse BEV semantic segmentation results. An efficient multi-camera deformable attention unit is designed to carry out the BEV-to-image view transformation. Finally, the queries are reshaped according the layout of grids in the BEV, and upsampled to produce the semantic segmentation result in a supervised manner. We evaluate the proposed algorithm on the public nuScenes dataset and a self-collected dataset. Experimental results show that our method achieves promising performance on BEV semantic segmentation from arbitrary camera rigs. We also demonstrate the effectiveness of each component via ablation study.
Coarse-to-fine Semantic Localization with HD Map for Autonomous Driving in Structural Scenes
Jul 06, 2021

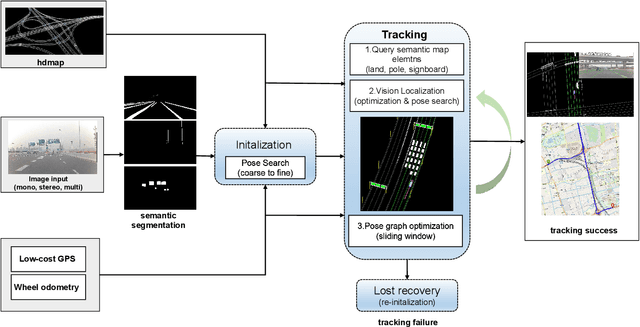

Robust and accurate localization is an essential component for robotic navigation and autonomous driving. The use of cameras for localization with high definition map (HD Map) provides an affordable localization sensor set. Existing methods suffer from pose estimation failure due to error prone data association or initialization with accurate initial pose requirement. In this paper, we propose a cost-effective vehicle localization system with HD map for autonomous driving that uses cameras as primary sensors. To this end, we formulate vision-based localization as a data association problem that maps visual semantics to landmarks in HD map. Specifically, system initialization is finished in a coarse to fine manner by combining coarse GPS (Global Positioning System) measurement and fine pose searching. In tracking stage, vehicle pose is refined by implicitly aligning the semantic segmentation result between image and landmarks in HD maps with photometric consistency. Finally, vehicle pose is computed by pose graph optimization in a sliding window fashion. We evaluate our method on two datasets and demonstrate that the proposed approach yields promising localization results in different driving scenarios. Additionally, our approach is suitable for both monocular camera and multi-cameras that provides flexibility and improves robustness for the localization system.
A Simple and Strong Baseline for Universal Targeted Attacks on Siamese Visual Tracking
May 06, 2021

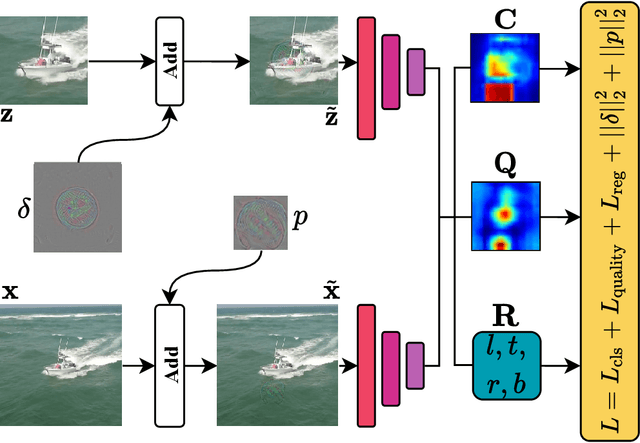

Siamese trackers are shown to be vulnerable to adversarial attacks recently. However, the existing attack methods craft the perturbations for each video independently, which comes at a non-negligible computational cost. In this paper, we show the existence of universal perturbations that can enable the targeted attack, e.g., forcing a tracker to follow the ground-truth trajectory with specified offsets, to be video-agnostic and free from inference in a network. Specifically, we attack a tracker by adding a universal imperceptible perturbation to the template image and adding a fake target, i.e., a small universal adversarial patch, into the search images adhering to the predefined trajectory, so that the tracker outputs the location and size of the fake target instead of the real target. Our approach allows perturbing a novel video to come at no additional cost except the mere addition operations -- and not require gradient optimization or network inference. Experimental results on several datasets demonstrate that our approach can effectively fool the Siamese trackers in a targeted attack manner. We show that the proposed perturbations are not only universal across videos, but also generalize well across different trackers. Such perturbations are therefore doubly universal, both with respect to the data and the network architectures. We will make our code publicly available.