 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Kalman Filter with Ultimately Accurate Fused Measurement Covariance
Apr 11, 2025This paper investigates the distributed Kalman filter (DKF) for linear systems, with specific attention on measurement fusion, which is a typical way of information sharing and is vital for enhancing stability and improving estimation accuracy. We show that it is the mismatch between the fused measurement and the fused covariance that leads to performance degradation or inconsistency in previous consensus-based DKF algorithms. To address this issue, we introduce two fully distributed approaches for calculating the exact covariance of the fused measurements, building upon which the modified DKF algorithms are proposed. Moreover, the performance analysis of the modified algorithms is also provided under rather mild conditions, including the steady-state value of the estimation error covariance. We also show that due to the guaranteed consistency in the modified DKF algorithms, the steady-state estimation accuracy is significantly improved compared to classical DKF algorithms. Numerical experiments are carried out to validate the theoretical analysis and show the advantages of the proposed methods.
Risk-Aware Autonomous Driving for Linear Temporal Logic Specifications
Sep 15, 2024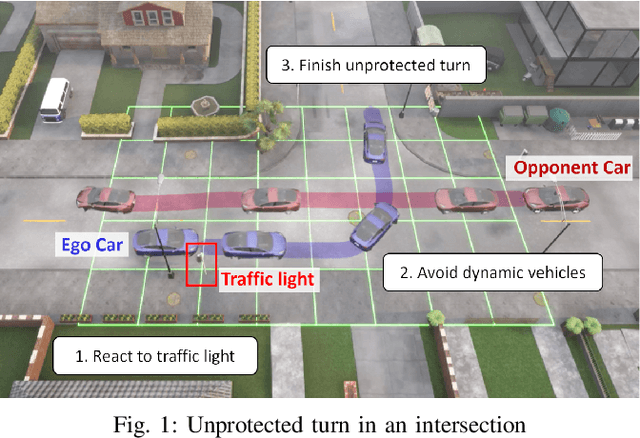
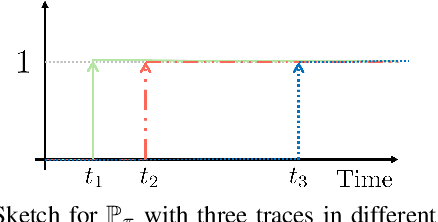
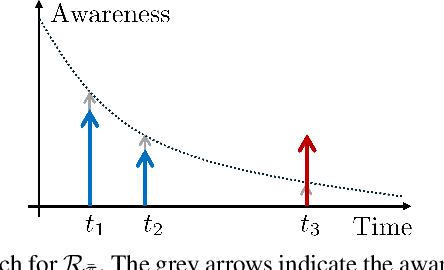

Decision-making for autonomous driving incorporating different types of risks is a challenging topic. This paper proposes a novel risk metric to facilitate the driving task specified by linear temporal logic (LTL) by balancing the risk brought up by different uncertain events. Such a balance is achieved by discounting the costs of these uncertain events according to their timing and severity, thereby reflecting a human-like awareness of risk. We have established a connection between this risk metric and the occupation measure, a fundamental concept in stochastic reachability problems, such that a risk-aware control synthesis problem under LTL specifications is formulated for autonomous vehicles using occupation measures. As a result, the synthesized policy achieves balanced decisions across different types of risks with associated costs, showcasing advantageous versatility and generalizability. The effectiveness and scalability of the proposed approach are validated by three typical traffic scenarios in Carla simulator.
VernaCopter: Disambiguated Natural-Language-Driven Robot via Formal Specifications
Sep 14, 2024



It has been an ambition of many to control a robot for a complex task using natural language (NL). The rise of large language models (LLMs) makes it closer to coming true. However, an LLM-powered system still suffers from the ambiguity inherent in an NL and the uncertainty brought up by LLMs. This paper proposes a novel LLM-based robot motion planner, named \textit{VernaCopter}, with signal temporal logic (STL) specifications serving as a bridge between NL commands and specific task objectives. The rigorous and abstract nature of formal specifications allows the planner to generate high-quality and highly consistent paths to guide the motion control of a robot. Compared to a conventional NL-prompting-based planner, the proposed VernaCopter planner is more stable and reliable due to less ambiguous uncertainty. Its efficacy and advantage have been validated by two small but challenging experimental scenarios, implying its potential in designing NL-driven robots.
A Comparative Study of Artificial Potential Fields and Safety Filters
Mar 23, 2024In this paper, we have demonstrated that the controllers designed by a classical motion planning tool, namely artificial potential fields (APFs), can be derived from a recently prevalent approach: control barrier function quadratic program (CBF-QP) safety filters. By integrating APF information into the CBF-QP framework, we establish a bridge between these two methodologies. Specifically, this is achieved by employing the attractive potential field as a control Lyapunov function (CLF) to guide the design of the nominal controller, and then the repulsive potential field serves as a reciprocal CBF (RCBF) to define a CBF-QP safety filter. Building on this integration, we extend the design of the CBF-QP safety filter to accommodate a more general class of dynamical models featuring a control-affine structure. This extension yields a special CBF-QP safety filter and a general APF solution suitable for control-affine dynamical models. Through a reach-avoid navigation example, we showcase the efficacy of the developed approaches.
Unifying Controller Design for Stabilizing Nonlinear Systems with Norm-Bounded Control Inputs
Mar 05, 2024


This paper revisits a classical challenge in the design of stabilizing controllers for nonlinear systems with a norm-bounded input constraint. By extending Lin-Sontag's universal formula and introducing a generic (state-dependent) scaling term, a unifying controller design method is proposed. The incorporation of this generic scaling term gives a unified controller and enables the derivation of alternative universal formulas with various favorable properties, which makes it suitable for tailored control designs to meet specific requirements and provides versatility across different control scenarios. Additionally, we present a constructive approach to determine the optimal scaling term, leading to an explicit solution to an optimization problem, named optimization-based universal formula. The resulting controller ensures asymptotic stability, satisfies a norm-bounded input constraint, and optimizes a predefined cost function. Finally, the essential properties of the unified controllers are analyzed, including smoothness, continuity at the origin, stability margin, and inverse optimality. Simulations validate the approach, showcasing its effectiveness in addressing a challenging stabilizing control problem of a nonlinear system.
Coordinated Guiding Vector Field Design for Ordering-Flexible Multi-Robot Surface Navigation
Jan 25, 2024



We design a distributed coordinated guiding vector field (CGVF) for a group of robots to achieve ordering-flexible motion coordination while maneuvering on a desired two-dimensional (2D) surface. The CGVF is characterized by three terms, i.e., a convergence term to drive the robots to converge to the desired surface, a propagation term to provide a traversing direction for maneuvering on the desired surface, and a coordinated term to achieve the surface motion coordination with an arbitrary ordering of the robotic group. By setting the surface parameters as additional virtual coordinates, the proposed approach eliminates the potential singularity of the CGVF and enables both the global convergence to the desired surface and the maneuvering on the surface from all possible initial conditions. The ordering-flexible surface motion coordination is realized by each robot to share with its neighbors only two virtual coordinates, i.e. that of a given target and that of its own, which reduces the communication and computation cost in multi-robot surface navigation. Finally, the effectiveness of the CGVF is substantiated by extensive numerical simulations.
Quadrotor Stabilization with Safety Guarantees: A Universal Formula Approach
Jan 07, 2024Safe stabilization is a significant challenge for quadrotors, which involves reaching a goal position while avoiding obstacles. Most of the existing solutions for this problem rely on optimization-based methods, demanding substantial onboard computational resources. This paper introduces a novel approach to address this issue and provides a solution that offers fast computational capabilities tailored for onboard execution. Drawing inspiration from Sontag's universal formula, we propose an analytical control strategy that incorporates the conditions of control Lyapunov functions (CLFs) and control barrier functions (CBFs), effectively avoiding the need for solving optimization problems onboard. Moreover, we extend our approach by incorporating the concepts of input-to-state stability (ISS) and input-to-state safety (ISSf), enhancing the universal formula's capacity to effectively manage disturbances. Furthermore, we present a projection-based approach to ensure that the universal formula remains effective even when faced with control input constraints. The basic idea of this approach is to project the control input derived from the universal formula onto the closest point within the control input domain. Through comprehensive simulations and experimental results, we validate the efficacy and highlight the advantages of our methodology.
An alternating peak-optimization method for optimal trajectory generation of quadrotor drones
Dec 05, 2023



In this paper, we propose an alternating optimization method to address a time-optimal trajectory generation problem. Different from the existing solutions, our approach introduces a new formulation that minimizes the overall trajectory running time while maintaining the polynomial smoothness constraints and incorporating hard limits on motion derivatives to ensure feasibility. To address this problem, an alternating peak-optimization method is developed, which splits the optimization process into two sub-optimizations: the first sub-optimization optimizes polynomial coefficients for smoothness, and the second sub-optimization adjusts the time allocated to each trajectory segment. These are alternated until a feasible minimum-time solution is found. We offer a comprehensive set of simulations and experiments to showcase the superior performance of our approach in comparison to existing methods. A collection of demonstration videos with real drone flying experiments can be accessed at https://www.youtube.com/playlist?list=PLQGtPFK17zUYkwFT-fr0a8E49R8Uq712l .
CircleFormer: Circular Nuclei Detection in Whole Slide Images with Circle Queries and Attention
Aug 31, 2023



Both CNN-based and Transformer-based object detection with bounding box representation have been extensively studied in computer vision and medical image analysis, but circular object detection in medical images is still underexplored. Inspired by the recent anchor free CNN-based circular object detection method (CircleNet) for ball-shape glomeruli detection in renal pathology, in this paper, we present CircleFormer, a Transformer-based circular medical object detection with dynamic anchor circles. Specifically, queries with circle representation in Transformer decoder iteratively refine the circular object detection results, and a circle cross attention module is introduced to compute the similarity between circular queries and image features. A generalized circle IoU (gCIoU) is proposed to serve as a new regression loss of circular object detection as well. Moreover, our approach is easy to generalize to the segmentation task by adding a simple segmentation branch to CircleFormer. We evaluate our method in circular nuclei detection and segmentation on the public MoNuSeg dataset, and the experimental results show that our method achieves promising performance compared with the state-of-the-art approaches. The effectiveness of each component is validated via ablation studies as well. Our code is released at https://github.com/zhanghx-iim-ahu/CircleFormer.
Risk-Aware Reward Shaping of Reinforcement Learning Agents for Autonomous Driving
Jun 05, 2023Reinforcement learning (RL) is an effective approach to motion planning in autonomous driving, where an optimal driving policy can be automatically learned using the interaction data with the environment. Nevertheless, the reward function for an RL agent, which is significant to its performance, is challenging to be determined. The conventional work mainly focuses on rewarding safe driving states but does not incorporate the awareness of risky driving behaviors of the vehicles. In this paper, we investigate how to use risk-aware reward shaping to leverage the training and test performance of RL agents in autonomous driving. Based on the essential requirements that prescribe the safety specifications for general autonomous driving in practice, we propose additional reshaped reward terms that encourage exploration and penalize risky driving behaviors. A simulation study in OpenAI Gym indicates the advantage of risk-aware reward shaping for various RL agents. Also, we point out that proximal policy optimization (PPO) is likely to be the best RL method that works with risk-aware reward shaping.