 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutonomous Driving with Priority-Ordered STL Specifications Under Multimodal Uncertainty
Jun 18, 2026Autonomous vehicles must plan trajectories that satisfy a multitude of requirements on safety, passenger comfort, and compliance with traffic rules. However, in safety-critical scenarios, it is not always possible to satisfy all requirements simultaneously, necessitating their prioritization based on importance. At the same time, in these safety-critical scenarios, the uncertainty in trajectory predictions of the surrounding traffic, such as other vehicles and pedestrians, should be explicitly accounted for. In this work, we propose an uncertainty-aware trajectory planning framework that incorporates a predefined lexicographic ordering over Signal Temporal Logic (STL) specifications that stays valid under uncertainty. We implement this formulation with Model Predictive Path Integral (MPPI) control and we demonstrate the effectiveness of our method on simulation scenarios, showing that our framework efficiently handles conflicting objectives under realistic multi-modal uncertainty.
A Vehicle-in-the-Loop Simulator with AI-Powered Digital Twins for Testing Automated Driving Controllers
Jul 03, 2025



Simulators are useful tools for testing automated driving controllers. Vehicle-in-the-loop (ViL) tests and digital twins (DTs) are widely used simulation technologies to facilitate the smooth deployment of controllers to physical vehicles. However, conventional ViL tests rely on full-size vehicles, requiring large space and high expenses. Also, physical-model-based DT suffers from the reality gap caused by modeling imprecision. This paper develops a comprehensive and practical simulator for testing automated driving controllers enhanced by scaled physical cars and AI-powered DT models. The scaled cars allow for saving space and expenses of simulation tests. The AI-powered DT models ensure superior simulation fidelity. Moreover, the simulator integrates well with off-the-shelf software and control algorithms, making it easy to extend. We use a filtered control benchmark with formal safety guarantees to showcase the capability of the simulator in validating automated driving controllers. Experimental studies are performed to showcase the efficacy of the simulator, implying its great potential in validating control solutions for autonomous vehicles and intelligent traffic.
Risk-Aware Autonomous Driving for Linear Temporal Logic Specifications
Sep 15, 2024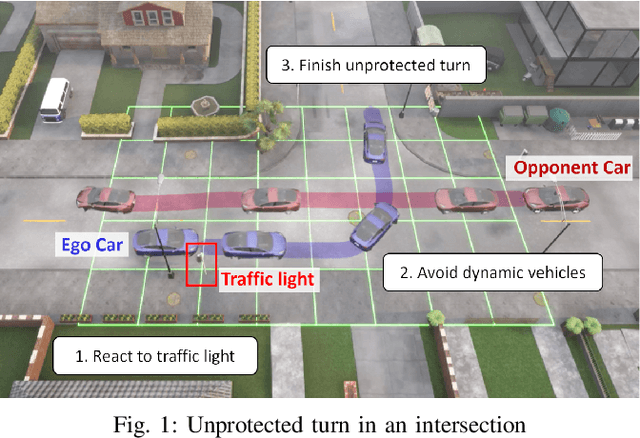
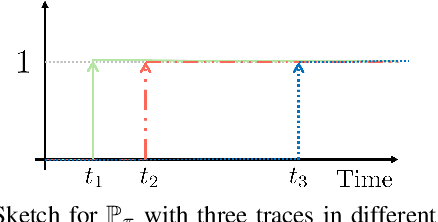
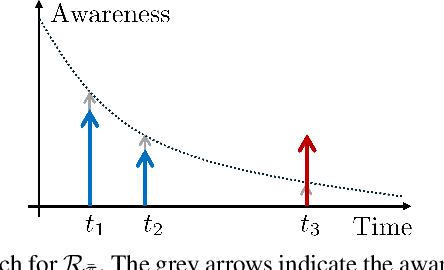

Decision-making for autonomous driving incorporating different types of risks is a challenging topic. This paper proposes a novel risk metric to facilitate the driving task specified by linear temporal logic (LTL) by balancing the risk brought up by different uncertain events. Such a balance is achieved by discounting the costs of these uncertain events according to their timing and severity, thereby reflecting a human-like awareness of risk. We have established a connection between this risk metric and the occupation measure, a fundamental concept in stochastic reachability problems, such that a risk-aware control synthesis problem under LTL specifications is formulated for autonomous vehicles using occupation measures. As a result, the synthesized policy achieves balanced decisions across different types of risks with associated costs, showcasing advantageous versatility and generalizability. The effectiveness and scalability of the proposed approach are validated by three typical traffic scenarios in Carla simulator.
VernaCopter: Disambiguated Natural-Language-Driven Robot via Formal Specifications
Sep 14, 2024



It has been an ambition of many to control a robot for a complex task using natural language (NL). The rise of large language models (LLMs) makes it closer to coming true. However, an LLM-powered system still suffers from the ambiguity inherent in an NL and the uncertainty brought up by LLMs. This paper proposes a novel LLM-based robot motion planner, named \textit{VernaCopter}, with signal temporal logic (STL) specifications serving as a bridge between NL commands and specific task objectives. The rigorous and abstract nature of formal specifications allows the planner to generate high-quality and highly consistent paths to guide the motion control of a robot. Compared to a conventional NL-prompting-based planner, the proposed VernaCopter planner is more stable and reliable due to less ambiguous uncertainty. Its efficacy and advantage have been validated by two small but challenging experimental scenarios, implying its potential in designing NL-driven robots.
Awareness in robotics: An early perspective from the viewpoint of the EIC Pathfinder Challenge "Awareness Inside''
Feb 14, 2024Consciousness has been historically a heavily debated topic in engineering, science, and philosophy. On the contrary, awareness had less success in raising the interest of scholars in the past. However, things are changing as more and more researchers are getting interested in answering questions concerning what awareness is and how it can be artificially generated. The landscape is rapidly evolving, with multiple voices and interpretations of the concept being conceived and techniques being developed. The goal of this paper is to summarize and discuss the ones among these voices connected with projects funded by the EIC Pathfinder Challenge called ``Awareness Inside'', a nonrecurring call for proposals within Horizon Europe designed specifically for fostering research on natural and synthetic awareness. In this perspective, we dedicate special attention to challenges and promises of applying synthetic awareness in robotics, as the development of mature techniques in this new field is expected to have a special impact on generating more capable and trustworthy embodied systems.
Energy-Constrained Active Exploration Under Incremental-Resolution Symbolic Perception
Sep 13, 2023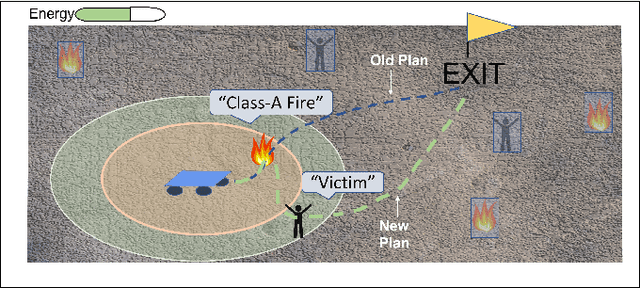
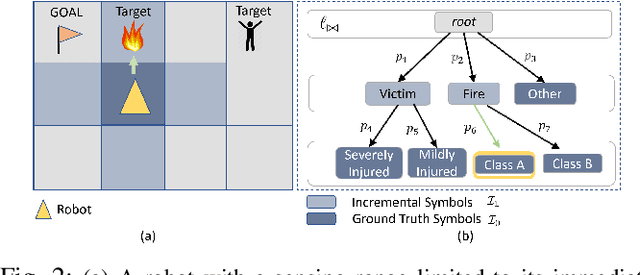
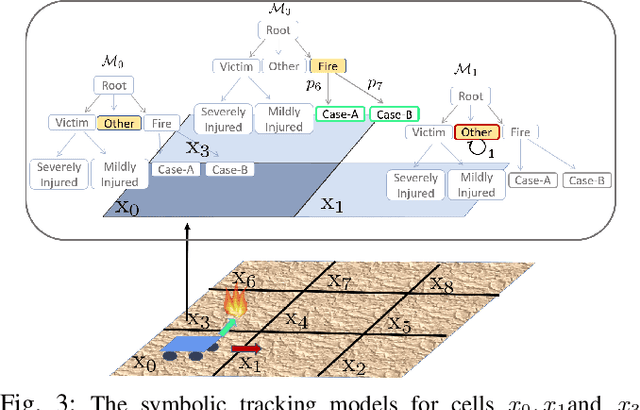
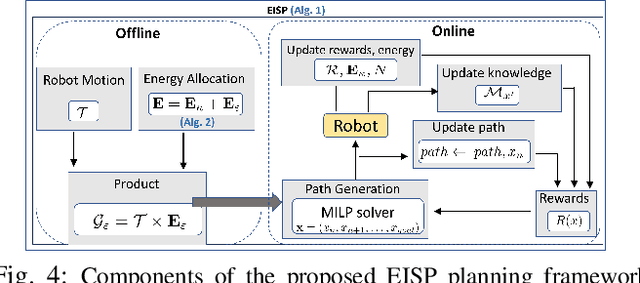
In this work, we consider the problem of autonomous exploration in search of targets while respecting a fixed energy budget. The robot is equipped with an incremental-resolution symbolic perception module wherein the perception of targets in the environment improves as the robot's distance from targets decreases. We assume no prior information about the total number of targets, their locations as well as their possible distribution within the environment. This work proposes a novel decision-making framework for the resulting constrained sequential decision-making problem by first converting it into a reward maximization problem on a product graph computed offline. It is then solved online as a Mixed-Integer Linear Program (MILP) where the knowledge about the environment is updated at each step, combining automata-based and MILP-based techniques. We demonstrate the efficacy of our approach with the help of a case study and present empirical evaluation in terms of expected regret. Furthermore, the runtime performance shows that online planning can be efficiently performed for moderately-sized grid environments.
Risk-Aware Reward Shaping of Reinforcement Learning Agents for Autonomous Driving
Jun 05, 2023Reinforcement learning (RL) is an effective approach to motion planning in autonomous driving, where an optimal driving policy can be automatically learned using the interaction data with the environment. Nevertheless, the reward function for an RL agent, which is significant to its performance, is challenging to be determined. The conventional work mainly focuses on rewarding safe driving states but does not incorporate the awareness of risky driving behaviors of the vehicles. In this paper, we investigate how to use risk-aware reward shaping to leverage the training and test performance of RL agents in autonomous driving. Based on the essential requirements that prescribe the safety specifications for general autonomous driving in practice, we propose additional reshaped reward terms that encourage exploration and penalize risky driving behaviors. A simulation study in OpenAI Gym indicates the advantage of risk-aware reward shaping for various RL agents. Also, we point out that proximal policy optimization (PPO) is likely to be the best RL method that works with risk-aware reward shaping.
Automated Formation Control Synthesis from Temporal Logic Specifications
Apr 05, 2023


In this paper, we propose a novel framework using formal methods to synthesize a navigation control strategy for a multi-robot swarm system with automated formation. The main objective of the problem is to navigate the robot swarm toward a goal position while passing a series of waypoints. The formation of the robot swarm should be changed according to the terrain restrictions around the corresponding waypoint. Also, the motion of the robots should always satisfy certain runtime safety requirements, such as avoiding collision with other robots and obstacles. We prescribe the desired waypoints and formation for the robot swarm using a temporal logic (TL) specification. Then, we formulate the transition of the waypoints and the formation as a deterministic finite transition system (DFTS) and synthesize a control strategy subject to the TL specification. Meanwhile, the runtime safety requirements are encoded using control barrier functions, and fixed-time control Lyapunov functions ensure fixed-time convergence. A quadratic program (QP) problem is solved to refine the DFTS control strategy to generate the control inputs for the robots, such that both TL specifications and runtime safety requirements are satisfied simultaneously. This work enlights a novel solution for multi-robot systems with complicated task specifications. The efficacy of the proposed framework is validated with a simulation study.
Cautious Planning with Incremental Symbolic Perception: Designing Verified Reactive Driving Maneuvers
Sep 20, 2022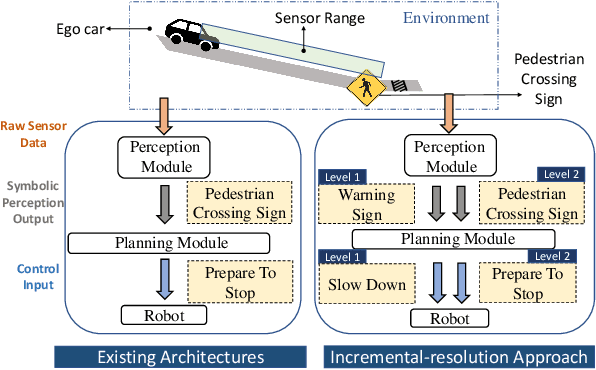
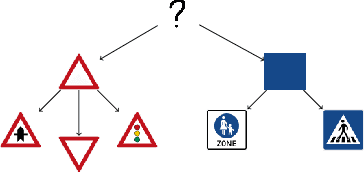
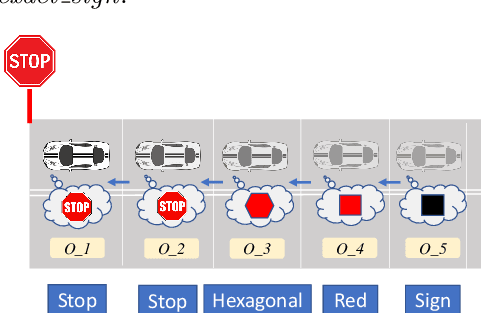
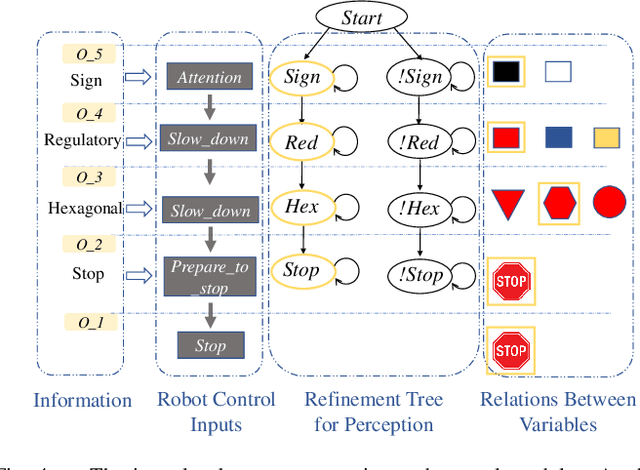
This work presents a step towards utilizing incrementally-improving symbolic perception knowledge of the robot's surroundings for provably correct reactive control synthesis applied to an autonomous driving problem. Combining abstract models of motion control and information gathering, we show that assume-guarantee specifications (a subclass of Linear Temporal Logic) can be used to define and resolve traffic rules for cautious planning. We propose a novel representation called symbolic refinement tree for perception that captures the incremental knowledge about the environment and embodies the relationships between various symbolic perception inputs. The incremental knowledge is leveraged for synthesizing verified reactive plans for the robot. The case studies demonstrate the efficacy of the proposed approach in synthesizing control inputs even in case of partially occluded environments.
Where to Map? Iterative Rover-Copter Path Planning for Mars Exploration
Aug 17, 2020

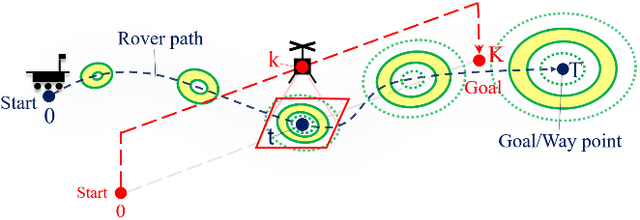
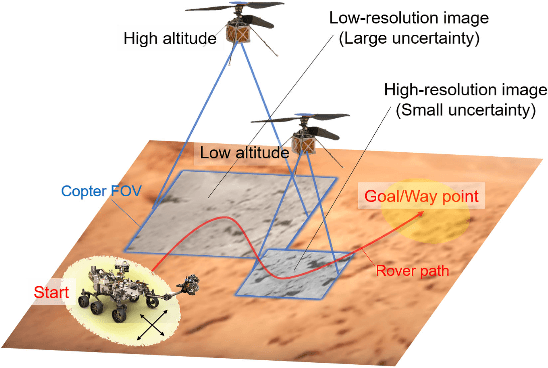
In addition to conventional ground rovers, the Mars 2020 mission will send a helicopter to Mars. The copter's high-resolution data helps the rover to identify small hazards such as steps and pointy rocks, as well as providing rich textual information useful to predict perception performance. In this paper, we consider a three-agent system composed of a Mars rover, copter, and orbiter. The objective is to provide good localization to the rover by selecting an optimal path that minimizes the localization uncertainty accumulation during the rover's traverse. To achieve this goal, we quantify the localizability as a goodness measure associated with the map, and conduct a joint-space search over rover's path and copter's perceptual actions given prior information from the orbiter. We jointly address where to map by the copter and where to drive by the rover using the proposed iterative copter-rover path planner. We conducted numerical simulations using the map of Mars 2020 landing site to demonstrate the effectiveness of the proposed planner.
* 8 pages, 7 figures