 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyGenar: An LLM-Driven Hybrid Genetic Algorithm for Few-Shot Grammar Generation
May 22, 2025Grammar plays a critical role in natural language processing and text/code generation by enabling the definition of syntax, the creation of parsers, and guiding structured outputs. Although large language models (LLMs) demonstrate impressive capabilities across domains, their ability to infer and generate grammars has not yet been thoroughly explored. In this paper, we aim to study and improve the ability of LLMs for few-shot grammar generation, where grammars are inferred from sets of a small number of positive and negative examples and generated in Backus-Naur Form. To explore this, we introduced a novel dataset comprising 540 structured grammar generation challenges, devised 6 metrics, and evaluated 8 various LLMs against it. Our findings reveal that existing LLMs perform sub-optimally in grammar generation. To address this, we propose an LLM-driven hybrid genetic algorithm, namely HyGenar, to optimize grammar generation. HyGenar achieves substantial improvements in both the syntactic and semantic correctness of generated grammars across LLMs.
Metric-Guided Synthesis of Class Activation Mapping
Apr 14, 2025Class activation mapping (CAM) is a widely adopted class of saliency methods used to explain the behavior of convolutional neural networks (CNNs). These methods generate heatmaps that highlight the parts of the input most relevant to the CNN output. Various CAM methods have been proposed, each distinguished by the expressions used to derive heatmaps. In general, users look for heatmaps with specific properties that reflect different aspects of CNN functionality. These may include similarity to ground truth, robustness, equivariance, and more. Although existing CAM methods implicitly encode some of these properties in their expressions, they do not allow for variability in heatmap generation following the user's intent or domain knowledge. In this paper, we address this limitation by introducing SyCAM, a metric-based approach for synthesizing CAM expressions. Given a predefined evaluation metric for saliency maps, SyCAM automatically generates CAM expressions optimized for that metric. We specifically explore a syntax-guided synthesis instantiation of SyCAM, where CAM expressions are derived based on predefined syntactic constraints and the given metric. Using several established evaluation metrics, we demonstrate the efficacy and flexibility of our approach in generating targeted heatmaps. We compare SyCAM with other well-known CAM methods on three prominent models: ResNet50, VGG16, and VGG19.
Online Prompt and Solver Selection for Program Synthesis
Jan 09, 2025Large Language Models (LLMs) demonstrate impressive capabilities in the domain of program synthesis. This level of performance is not, however, universal across all tasks, all LLMs and all prompting styles. There are many areas where one LLM dominates, one prompting style dominates, or where calling a symbolic solver is a better choice than an LLM. A key challenge for the user then, is to identify not only when an LLM is the right choice of solver, and the appropriate LLM to call for a given synthesis task, but also the right way to call it. A non-expert user who makes the wrong choice, incurs a cost both in terms of results (number of tasks solved, and the time it takes to solve them) and financial cost, if using a closed-source language model via a commercial API. We frame this choice as an online learning problem. We use a multi-armed bandit algorithm to select which symbolic solver, or LLM and prompt combination to deploy in order to maximize a given reward function (which may prioritize solving time, number of synthesis tasks solved, or financial cost of solving). We implement an instance of this approach, called CYANEA, and evaluate it on synthesis queries from the literature in ranking function synthesis, from the syntax-guided synthesis competition, and fresh, unseen queries generated from SMT problems. CYANEA solves 37.2\% more queries than the best single solver and achieves results within 4\% of the virtual best solver.
Synthetic Programming Elicitation and Repair for Text-to-Code in Very Low-Resource Programming Languages
Jun 05, 2024



Recent advances in large language models (LLMs) for code applications have demonstrated remarkable zero-shot fluency and instruction following on challenging code related tasks ranging from test case generation to self-repair. Unsurprisingly, however, models struggle to compose syntactically valid programs in programming languages unrepresented in pre-training, referred to as very low-resource Programming Languages (VLPLs). VLPLs appear in crucial settings including domain-specific languages for internal to tools and tool-chains and legacy languages. Inspired by an HCI technique called natural program elicitation, we propose designing an intermediate language that LLMs ``naturally'' know how to use and which can be automatically compiled to the target VLPL. Specifically, we introduce synthetic programming elicitation and compilation (SPEAK), an approach that enables LLMs to generate syntactically valid code even for VLPLs. We empirically evaluate the performance of SPEAK in a case study and find that, compared to existing retrieval and fine-tuning baselines, SPEAK produces syntactically correct programs more frequently without sacrificing semantic correctness.
Guiding Enumerative Program Synthesis with Large Language Models
Mar 06, 2024Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
mlirSynth: Automatic, Retargetable Program Raising in Multi-Level IR using Program Synthesis
Oct 06, 2023MLIR is an emerging compiler infrastructure for modern hardware, but existing programs cannot take advantage of MLIR's high-performance compilation if they are described in lower-level general purpose languages. Consequently, to avoid programs needing to be rewritten manually, this has led to efforts to automatically raise lower-level to higher-level dialects in MLIR. However, current methods rely on manually-defined raising rules, which limit their applicability and make them challenging to maintain as MLIR dialects evolve. We present mlirSynth -- a novel approach which translates programs from lower-level MLIR dialects to high-level ones without manually defined rules. Instead, it uses available dialect definitions to construct a program space and searches it effectively using type constraints and equivalences. We demonstrate its effectiveness \revi{by raising C programs} to two distinct high-level MLIR dialects, which enables us to use existing high-level dialect specific compilation flows. On Polybench, we show a greater coverage than previous approaches, resulting in geomean speedups of 2.5x (Intel) and 3.4x (AMD) over state-of-the-art compilation flows for the C programming language. mlirSynth also enables retargetability to domain-specific accelerators, resulting in a geomean speedup of 21.6x on a TPU.
Reinforcement Learning for Syntax-Guided Synthesis
Jul 13, 2023Program synthesis is the task of automatically generating code based on a specification. In Syntax-Guided Synthesis(SyGuS) this specification is a combination of a syntactic template and a logical formula, and any generated code is proven to satisfy both. Techniques like SyGuS are critical to guaranteeing correct synthesis results. Despite the proliferation of machine learning in other types of program synthesis, state-of-the-art techniques in SyGuS are still driven by automated reasoning tools and simple enumeration. We hypothesize this is for two reasons: first the complexity of the search problem, and second the relatively small data sets available. In this work, we tackle these challenges by framing general SyGuS problems as a tree-search, and present a reinforcement learning guided synthesis algorithm for SyGuS based on Monte-Carlo Tree Search (MCTS). Our algorithm incorporates learned policy and value functions combined with the upper confidence bound for trees to balance exploration and exploitation. We incorporate this search procedure in a reinforcement learning setup in order to iteratively improve our policy and value estimators which are based on boosted tree models. To address the scarcity of training data, we present a method for automatically generating training data for SyGuS based on \emph{anti-unification} of existing first-order satisfiability problems, which we use to train our MCTS policy. We implement and evaluate this setup and demonstrate that learned policy and value improve the synthesis performance over a baseline enumerator by over $26$ percentage points in the training and testing sets. With these results our tool outperforms state-of-the-art-tools such as CVC5 on the training set and performs comparably on the testing set. We make our data set publicly available, enabling further application of machine learning methods to the SyGuS problem.
Satisfiability and Synthesis Modulo Oracles
Jul 28, 2021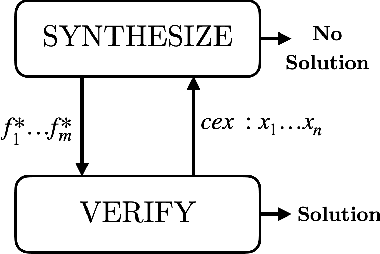
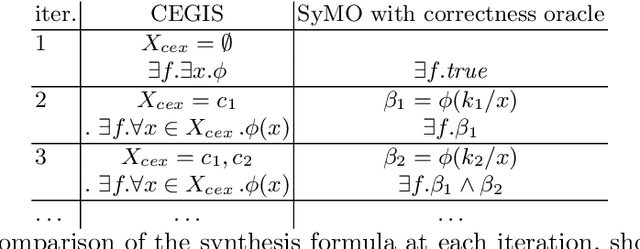


In classic program synthesis algorithms, such as counterexample-guided inductive synthesis (CEGIS), the algorithms alternate between a synthesis phase and an oracle (verification) phase. Many synthesis algorithms use a white-box oracle based on satisfiability modulo theory (SMT) solvers to provide counterexamples. But what if a white-box oracle is either not available or not easy to work with? We present a framework for solving a general class of oracle-guided synthesis problems which we term synthesis modulo oracles. In this setting, oracles may be black boxes with a query-response interface defined by the synthesis problem. As a necessary component of this framework, we also formalize the problem of satisfiability modulo theories and oracles, and present an algorithm for solving this problem. We implement a prototype solver for satisfiability and synthesis modulo oracles and demonstrate that, by using oracles that execute functions not easily modeled in SMT-constraints, such as recursive functions or oracles that incorporate compilation and execution of code, SMTO and SyMO are able to solve problems beyond the abilities of standard SMT and synthesis solvers.
Gradient Descent over Metagrammars for Syntax-Guided Synthesis
Jul 16, 2020
The performance of a syntax-guided synthesis algorithm is highly dependent on the provision of a good syntactic template, or grammar. Provision of such a template is often left to the user to do manually, though in the absence of such a grammar, state-of-the-art solvers will provide their own default grammar, which is dependent on the signature of the target program to be sythesized. In this work, we speculate this default grammar could be improved upon substantially. We build sets of rules, or metagrammars, for constructing grammars, and perform a gradient descent over these metagrammars aiming to find a metagrammar which solves more benchmarks and on average faster. We show the resulting metagrammar enables CVC4 to solve 26% more benchmarks than the default grammar within a 300s time-out, and that metagrammars learnt from tens of benchmarks generalize to performance on 100s of benchmarks.
CounterExample Guided Neural Synthesis
Jan 25, 2020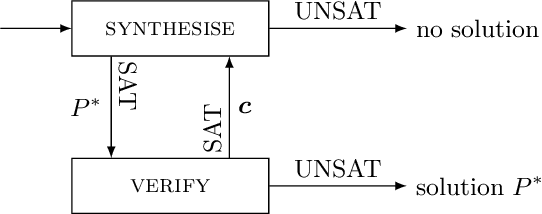

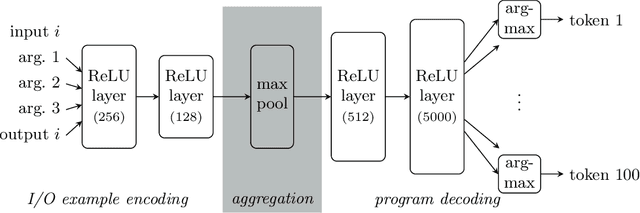
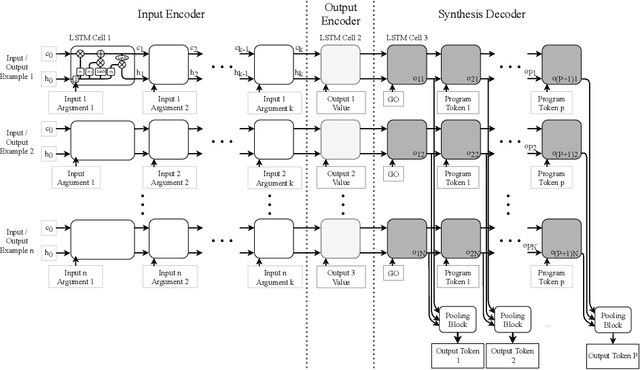
Program synthesis is the generation of a program from a specification. Correct synthesis is difficult, and methods that provide formal guarantees suffer from scalability issues. On the other hand, neural networks are able to generate programs from examples quickly but are unable to guarantee that the program they output actually meets the logical specification. In this work we combine neural networks with formal reasoning: using the latter to convert a logical specification into a sequence of examples that guides the neural network towards a correct solution, and to guarantee that any solution returned satisfies the formal specification. We apply our technique to synthesising loop invariants and compare the performance to existing solvers that use SMT and existing techniques that use neural networks. Our results show that the formal reasoning based guidance improves the performance of the neural network substantially, nearly doubling the number of benchmarks it can solve.