 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding Enumerative Program Synthesis with Large Language Models
Mar 06, 2024Pre-trained Large Language Models (LLMs) are beginning to dominate the discourse around automatic code generation with natural language specifications. In contrast, the best-performing synthesizers in the domain of formal synthesis with precise logical specifications are still based on enumerative algorithms. In this paper, we evaluate the abilities of LLMs to solve formal synthesis benchmarks by carefully crafting a library of prompts for the domain. When one-shot synthesis fails, we propose a novel enumerative synthesis algorithm, which integrates calls to an LLM into a weighted probabilistic search. This allows the synthesizer to provide the LLM with information about the progress of the enumerator, and the LLM to provide the enumerator with syntactic guidance in an iterative loop. We evaluate our techniques on benchmarks from the Syntax-Guided Synthesis (SyGuS) competition. We find that GPT-3.5 as a stand-alone tool for formal synthesis is easily outperformed by state-of-the-art formal synthesis algorithms, but our approach integrating the LLM into an enumerative synthesis algorithm shows significant performance gains over both the LLM and the enumerative synthesizer alone and the winning SyGuS competition tool.
Reinforcement Learning for Syntax-Guided Synthesis
Jul 13, 2023Program synthesis is the task of automatically generating code based on a specification. In Syntax-Guided Synthesis(SyGuS) this specification is a combination of a syntactic template and a logical formula, and any generated code is proven to satisfy both. Techniques like SyGuS are critical to guaranteeing correct synthesis results. Despite the proliferation of machine learning in other types of program synthesis, state-of-the-art techniques in SyGuS are still driven by automated reasoning tools and simple enumeration. We hypothesize this is for two reasons: first the complexity of the search problem, and second the relatively small data sets available. In this work, we tackle these challenges by framing general SyGuS problems as a tree-search, and present a reinforcement learning guided synthesis algorithm for SyGuS based on Monte-Carlo Tree Search (MCTS). Our algorithm incorporates learned policy and value functions combined with the upper confidence bound for trees to balance exploration and exploitation. We incorporate this search procedure in a reinforcement learning setup in order to iteratively improve our policy and value estimators which are based on boosted tree models. To address the scarcity of training data, we present a method for automatically generating training data for SyGuS based on \emph{anti-unification} of existing first-order satisfiability problems, which we use to train our MCTS policy. We implement and evaluate this setup and demonstrate that learned policy and value improve the synthesis performance over a baseline enumerator by over $26$ percentage points in the training and testing sets. With these results our tool outperforms state-of-the-art-tools such as CVC5 on the training set and performs comparably on the testing set. We make our data set publicly available, enabling further application of machine learning methods to the SyGuS problem.
Neural Termination Analysis
Feb 07, 2021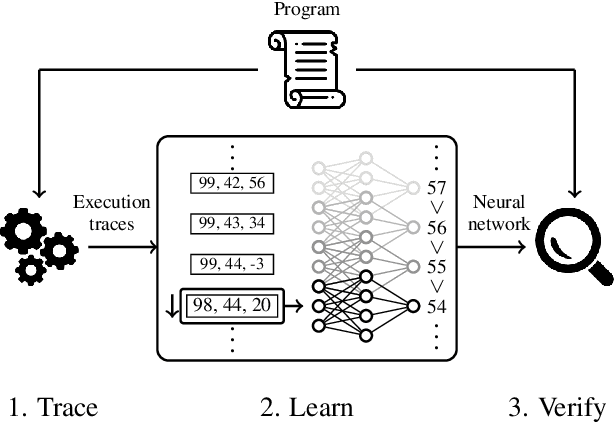
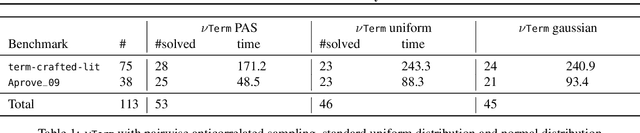

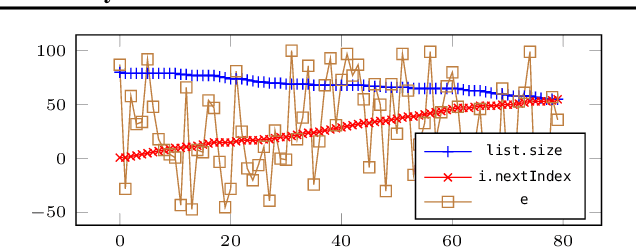
We introduce a novel approach to the automated termination analysis of computer programs: we train neural networks to act as ranking functions. Ranking functions map program states to values that are bounded from below and decrease as the program runs. The existence of a valid ranking function proves that the program terminates. While in the past ranking functions were usually constructed using static analysis, our method learns them from sampled executions. We train a neural network so that its output decreases along execution traces as a ranking function would; then, we use formal reasoning to verify whether it generalises to all possible executions. We present a custom loss function for learning lexicographic ranking functions and use satisfiability modulo theories for verification. Thanks to the ability of neural networks to generalise well, our method succeeds over a wide variety of programs. This includes programs that use data structures from standard libraries. We built a prototype analyser for Java bytecode and show the efficacy of our method over a standard dataset of benchmarks.
A Study of Continuous Vector Representationsfor Theorem Proving
Jan 22, 2021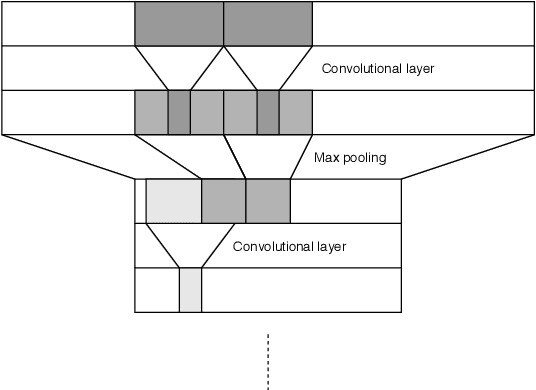

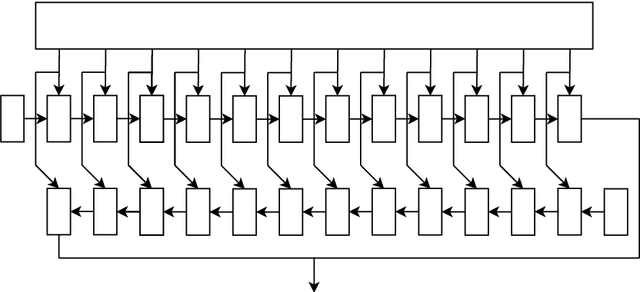
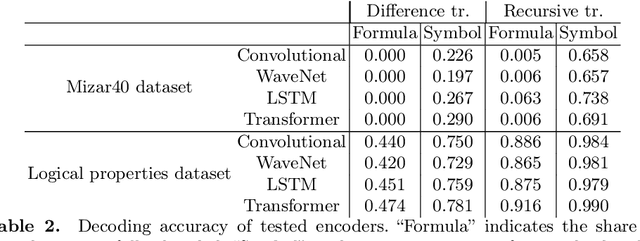
Applying machine learning to mathematical terms and formulas requires a suitable representation of formulas that is adequate for AI methods. In this paper, we develop an encoding that allows for logical properties to be preserved and is additionally reversible. This means that the tree shape of a formula including all symbols can be reconstructed from the dense vector representation. We do that by training two decoders: one that extracts the top symbol of the tree and one that extracts embedding vectors of subtrees. The syntactic and semantic logical properties that we aim to reserve include both structural formula properties, applicability of natural deduction steps, and even more complex operations like unifiability. We propose datasets that can be used to train these syntactic and semantic properties. We evaluate the viability of the developed encoding across the proposed datasets as well as for the practical theorem proving problem of premise selection in the Mizar corpus.