 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyGenar: An LLM-Driven Hybrid Genetic Algorithm for Few-Shot Grammar Generation
May 22, 2025Grammar plays a critical role in natural language processing and text/code generation by enabling the definition of syntax, the creation of parsers, and guiding structured outputs. Although large language models (LLMs) demonstrate impressive capabilities across domains, their ability to infer and generate grammars has not yet been thoroughly explored. In this paper, we aim to study and improve the ability of LLMs for few-shot grammar generation, where grammars are inferred from sets of a small number of positive and negative examples and generated in Backus-Naur Form. To explore this, we introduced a novel dataset comprising 540 structured grammar generation challenges, devised 6 metrics, and evaluated 8 various LLMs against it. Our findings reveal that existing LLMs perform sub-optimally in grammar generation. To address this, we propose an LLM-driven hybrid genetic algorithm, namely HyGenar, to optimize grammar generation. HyGenar achieves substantial improvements in both the syntactic and semantic correctness of generated grammars across LLMs.
Incorporating Token Usage into Prompting Strategy Evaluation
May 20, 2025In recent years, large language models have demonstrated remarkable performance across diverse tasks. However, their task effectiveness is heavily dependent on the prompting strategy used to elicit output, which can vary widely in both performance and token usage. While task performance is often used to determine prompting strategy success, we argue that efficiency--balancing performance and token usage--can be a more practical metric for real-world utility. To enable this, we propose Big-$O_{tok}$, a theoretical framework for describing the token usage growth of prompting strategies, and analyze Token Cost, an empirical measure of tokens per performance. We apply these to several common prompting strategies and find that increased token usage leads to drastically diminishing performance returns. Our results validate the Big-$O_{tok}$ analyses and reinforce the need for efficiency-aware evaluations.
Practical Considerations for Agentic LLM Systems
Dec 05, 2024



As the strength of Large Language Models (LLMs) has grown over recent years, so too has interest in their use as the underlying models for autonomous agents. Although LLMs demonstrate emergent abilities and broad expertise across natural language domains, their inherent unpredictability makes the implementation of LLM agents challenging, resulting in a gap between related research and the real-world implementation of such systems. To bridge this gap, this paper frames actionable insights and considerations from the research community in the context of established application paradigms to enable the construction and facilitate the informed deployment of robust LLM agents. Namely, we position relevant research findings into four broad categories--Planning, Memory, Tools, and Control Flow--based on common practices in application-focused literature and highlight practical considerations to make when designing agentic LLMs for real-world applications, such as handling stochasticity and managing resources efficiently. While we do not conduct empirical evaluations, we do provide the necessary background for discussing critical aspects of agentic LLM designs, both in academia and industry.
Probing the Capacity of Language Model Agents to Operationalize Disparate Experiential Context Despite Distraction
Nov 19, 2024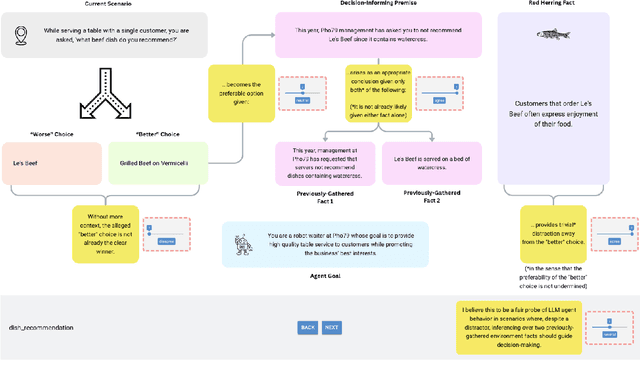



Large language model (LLM) agents show promise in an increasing number of domains. In many proposed applications, it is expected that the agent reasons over accumulated experience presented in an input prompt. We propose the OEDD (Operationalize Experience Despite Distraction) corpus, a human-annotator-validated body of scenarios with pre-scripted agent histories where the agent must make a decision based on disparate experiential information in the presence of a distractor. We evaluate three state-of-the-art LLMs (GPT-3.5 Turbo, GPT-4o, and Gemini 1.5 Pro) using a minimal chain-of-thought prompting strategy and observe that when (1) the input context contains over 1,615 tokens of historical interactions, (2) a crucially decision-informing premise is the rightful conclusion over two disparate environment premises, and (3) a trivial, but distracting red herring fact follows, all LLMs perform worse than random choice at selecting the better of two actions. Our code and test corpus are publicly available at: https://github.com/sonnygeorge/OEDD .