 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Capacity of Language Model Agents to Operationalize Disparate Experiential Context Despite Distraction
Paper and Code
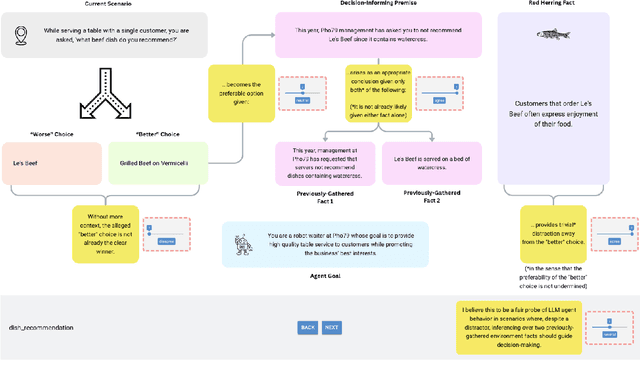



Large language model (LLM) agents show promise in an increasing number of domains. In many proposed applications, it is expected that the agent reasons over accumulated experience presented in an input prompt. We propose the OEDD (Operationalize Experience Despite Distraction) corpus, a human-annotator-validated body of scenarios with pre-scripted agent histories where the agent must make a decision based on disparate experiential information in the presence of a distractor. We evaluate three state-of-the-art LLMs (GPT-3.5 Turbo, GPT-4o, and Gemini 1.5 Pro) using a minimal chain-of-thought prompting strategy and observe that when (1) the input context contains over 1,615 tokens of historical interactions, (2) a crucially decision-informing premise is the rightful conclusion over two disparate environment premises, and (3) a trivial, but distracting red herring fact follows, all LLMs perform worse than random choice at selecting the better of two actions. Our code and test corpus are publicly available at: https://github.com/sonnygeorge/OEDD .