 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing the Capacity of Language Model Agents to Operationalize Disparate Experiential Context Despite Distraction
Nov 19, 2024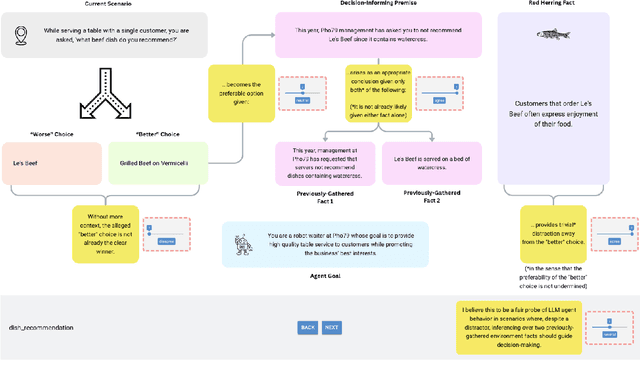



Large language model (LLM) agents show promise in an increasing number of domains. In many proposed applications, it is expected that the agent reasons over accumulated experience presented in an input prompt. We propose the OEDD (Operationalize Experience Despite Distraction) corpus, a human-annotator-validated body of scenarios with pre-scripted agent histories where the agent must make a decision based on disparate experiential information in the presence of a distractor. We evaluate three state-of-the-art LLMs (GPT-3.5 Turbo, GPT-4o, and Gemini 1.5 Pro) using a minimal chain-of-thought prompting strategy and observe that when (1) the input context contains over 1,615 tokens of historical interactions, (2) a crucially decision-informing premise is the rightful conclusion over two disparate environment premises, and (3) a trivial, but distracting red herring fact follows, all LLMs perform worse than random choice at selecting the better of two actions. Our code and test corpus are publicly available at: https://github.com/sonnygeorge/OEDD .
Visualization Guidelines for Model Performance Communication Between Data Scientists and Subject Matter Experts
May 11, 2022
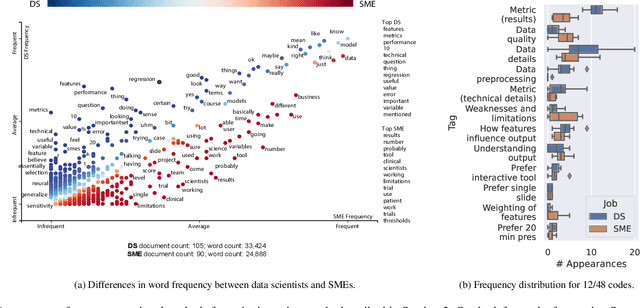


Presenting the complexities of a model's performance is a communication bottleneck that threatens collaborations between data scientists and subject matter experts. Accuracy and error metrics alone fail to tell the whole story of a model - its risks, strengths, and limitations - making it difficult for subject matter experts to feel confident in deciding to use a model. As a result, models may fail in unexpected ways if their weaknesses are not clearly understood. Alternatively, models may go unused, as subject matter experts disregard poorly presented models in favor of familiar, yet arguably substandard methods. In this paper, we propose effective use of visualization as a medium for communication between data scientists and subject matter experts. Our research addresses the gap between common practices in model performance communication and the understanding of subject matter experts and decision makers. We derive a set of communication guidelines and recommended visualizations for communicating model performance based on interviews of both data scientists and subject matter experts at the same organization. We conduct a follow-up study with subject matter experts to evaluate the efficacy of our guidelines in presentations of model performance with and without our recommendations. We find that our proposed guidelines made subject matter experts more aware of the tradeoffs of the presented model. Participants realized that current communication methods left them without a robust understanding of the model's performance, potentially giving them misplaced confidence in the use of the model.
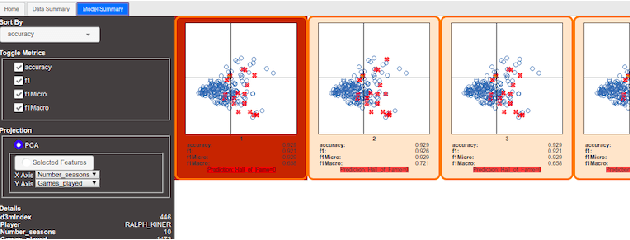
UnProjection: Leveraging Inverse-Projections for Visual Analytics of High-Dimensional Data
Nov 02, 2021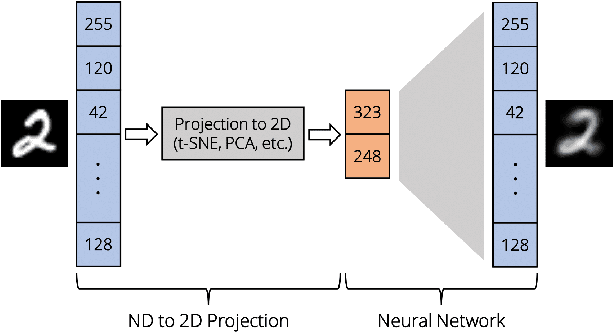
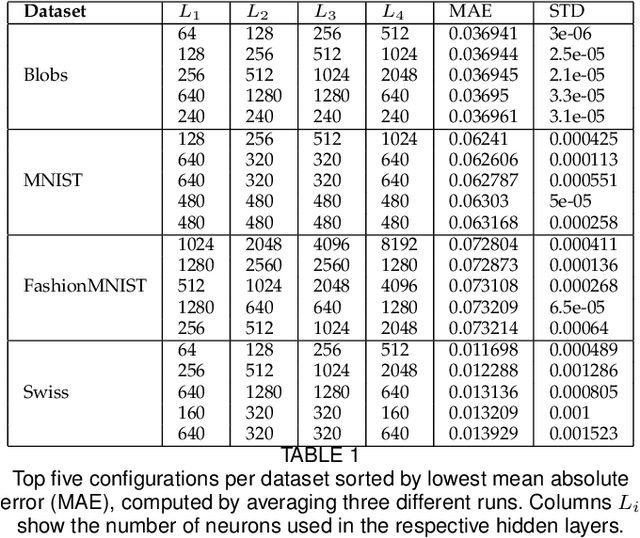

Projection techniques are often used to visualize high-dimensional data, allowing users to better understand the overall structure of multi-dimensional spaces on a 2D screen. Although many such methods exist, comparably little work has been done on generalizable methods of inverse-projection -- the process of mapping the projected points, or more generally, the projection space back to the original high-dimensional space. In this paper we present NNInv, a deep learning technique with the ability to approximate the inverse of any projection or mapping. NNInv learns to reconstruct high-dimensional data from any arbitrary point on a 2D projection space, giving users the ability to interact with the learned high-dimensional representation in a visual analytics system. We provide an analysis of the parameter space of NNInv, and offer guidance in selecting these parameters. We extend validation of the effectiveness of NNInv through a series of quantitative and qualitative analyses. We then demonstrate the method's utility by applying it to three visualization tasks: interactive instance interpolation, classifier agreement, and gradient visualization.
Ablate, Variate, and Contemplate: Visual Analytics for Discovering Neural Architectures
Jul 30, 2019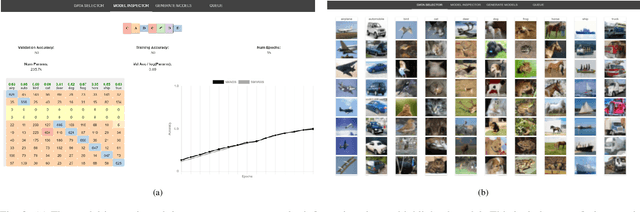
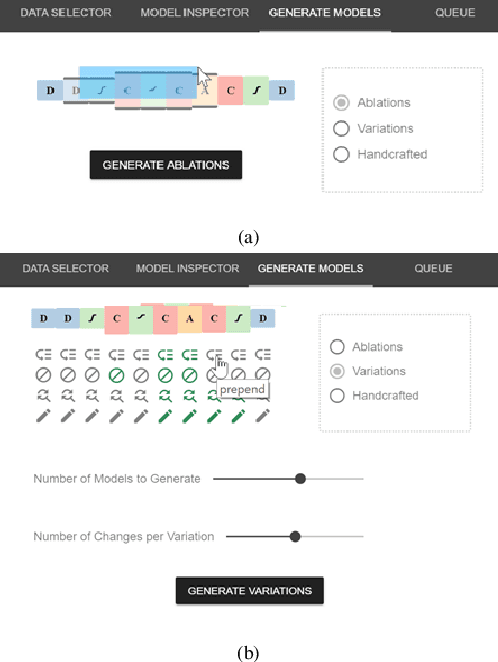
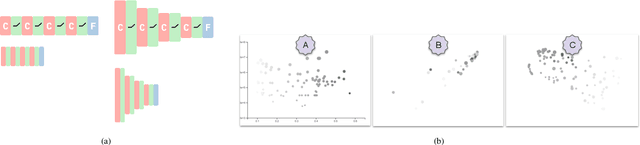
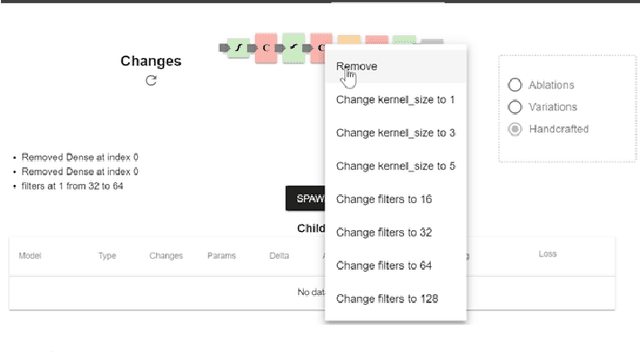
Deep learning models require the configuration of many layers and parameters in order to get good results. However, there are currently few systematic guidelines for how to configure a successful model. This means model builders often have to experiment with different configurations by manually programming different architectures (which is tedious and time consuming) or rely on purely automated approaches to generate and train the architectures (which is expensive). In this paper, we present Rapid Exploration of Model Architectures and Parameters, or REMAP, a visual analytics tool that allows a model builder to discover a deep learning model quickly via exploration and rapid experimentation of neural network architectures. In REMAP, the user explores the large and complex parameter space for neural network architectures using a combination of global inspection and local experimentation. Through a visual overview of a set of models, the user identifies interesting clusters of architectures. Based on their findings, the user can run ablation and variation experiments to identify the effects of adding, removing, or replacing layers in a given architecture and generate new models accordingly. They can also handcraft new models using a simple graphical interface. As a result, a model builder can build deep learning models quickly, efficiently, and without manual programming. We inform the design of REMAP through a design study with four deep learning model builders. Through a use case, we demonstrate that REMAP allows users to discover performant neural network architectures efficiently using visual exploration and user-defined semi-automated searches through the model space.
RNNbow: Visualizing Learning via Backpropagation Gradients in Recurrent Neural Networks
Jul 29, 2019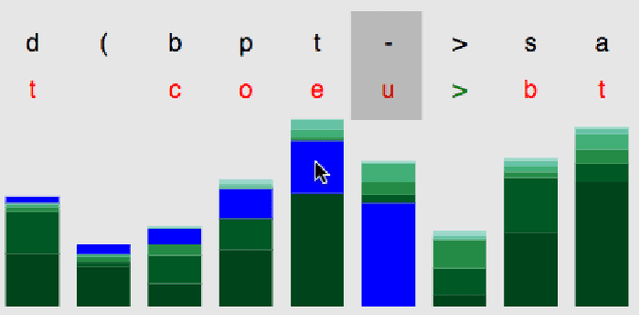
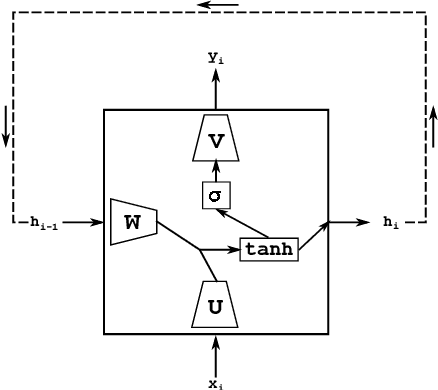
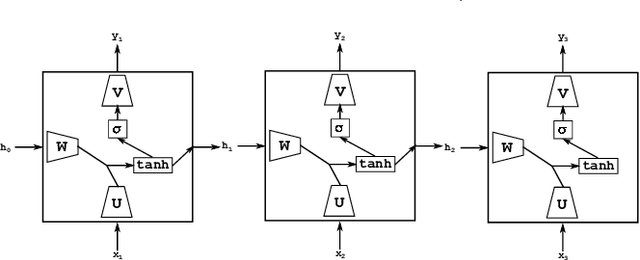
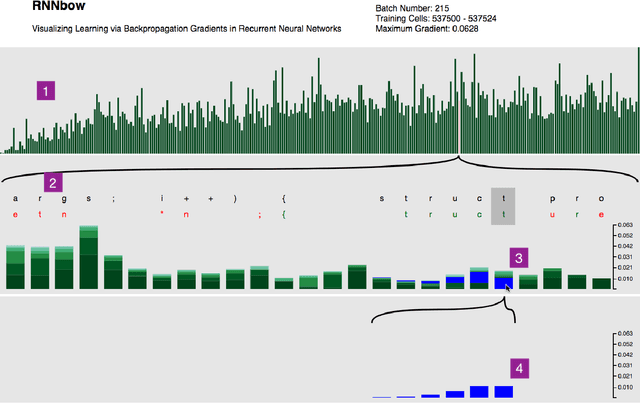
We present RNNbow, an interactive tool for visualizing the gradient flow during backpropagation training in recurrent neural networks. RNNbow is a web application that displays the relative gradient contributions from Recurrent Neural Network (RNN) cells in a neighborhood of an element of a sequence. We describe the calculation of backpropagation through time (BPTT) that keeps track of itemized gradients, or gradient contributions from one element of a sequence to previous elements of a sequence. By visualizing the gradient, as opposed to activations, RNNbow offers insight into how the network is learning. We use it to explore the learning of an RNN that is trained to generate code in the C programming language. We show how it uncovers insights into the vanishing gradient as well as the evolution of training as the RNN works its way through a corpus.
Visual Analytics for Automated Model Discovery
Oct 02, 2018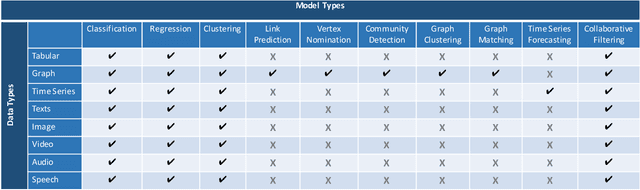
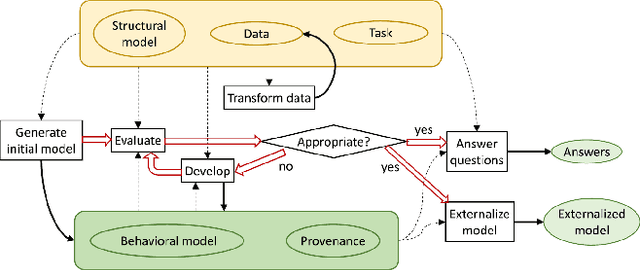
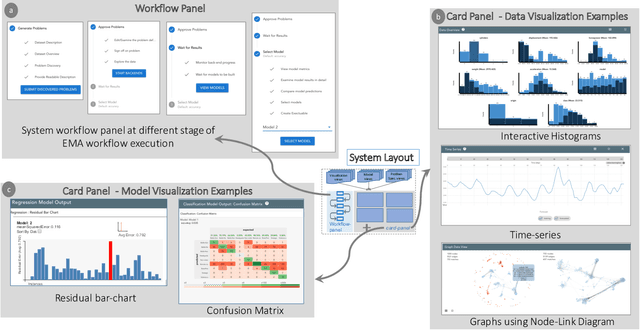
A recent advancement in the machine learning community is the development of automated machine learning (autoML) systems, such as autoWeka or Google's Cloud AutoML, which automate the model selection and tuning process. However, while autoML tools give users access to arbitrarily complex models, they typically return those models with little context or explanation. Visual analytics can be helpful in giving a user of autoML insight into their data, and a more complete understanding of the models discovered by autoML, including differences between multiple models. In this work, we describe how visual analytics for automated model discovery differs from traditional visual analytics for machine learning. First, we propose an architecture based on an extension of existing visual analytics frameworks. Then we describe a prototype system Snowcat, developed according to the presented framework and architecture, that aids users in generating models for a diverse set of data and modeling tasks.