 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMambaNet: Mamba-assisted Channel Estimation Neural Network With Attention Mechanism
Jan 23, 2026This paper proposes a Mamba-assisted neural network framework incorporating self-attention mechanism to achieve improved channel estimation with low complexity for orthogonal frequency-division multiplexing (OFDM) waveforms, particularly for configurations with a large number of subcarriers. With the integration of customized Mamba architecture, the proposed framework handles large-scale subcarrier channel estimation efficiently while capturing long-distance dependencies among these subcarriers effectively. Unlike conventional Mamba structure, this paper implements a bidirectional selective scan to improve channel estimation performance, because channel gains at different subcarriers are non-causal. Moreover, the proposed framework exhibits relatively lower space complexity than transformer-based neural networks. Simulation results tested on the 3GPP TS 36.101 channel demonstrate that compared to other baseline neural network solutions, the proposed method achieves improved channel estimation performance with a reduced number of tunable parameters.
Compensation of Coarse Quantization Effects on Channel Estimation and BER in Massive MIMO
Dec 16, 2025
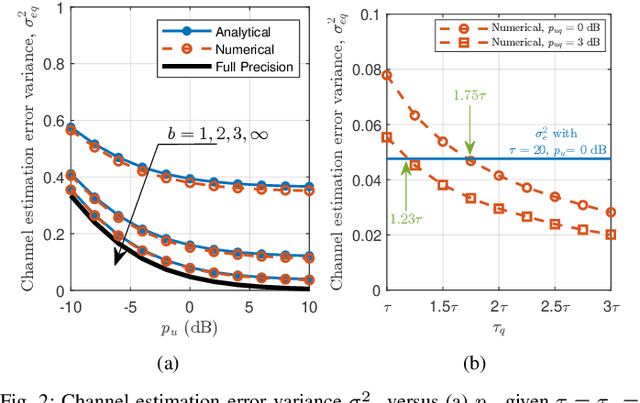


Low-resolution quantization is essential to reduce implementation cost and power consumption in massive multiple-input multiple-output (MIMO) systems for 5G and 6G. While most existing studies assume perfect channel state information (CSI), we model the impact of coarse quantization noise on both channel estimation and data transmission, yielding a more realistic assessment of system performance under imperfect CSI conditions in the uplink. We develop a tight approximation for the bit-error ratio (BER) of uncoded M-QAM with zero-forcing detection, based on the linear minimum mean-square error (LMMSE) channel estimate. These analytical results enable compensation strategies that jointly optimize quantization resolution, transmit power, and pilot length across different numbers of users and base station antennas. We further demonstrate the applicability of the proposed framework through several design scenarios that highlight its effectiveness in optimizing system parameters and improving energy efficiency under quantization constraints. For example, in a 16-QAM system, extending the pilot sequence by 2.5 times and lowering transmit power by 0.5 dB enables a 3-bit quantized system to match the BER of the full-resolution case. The proposed framework offers a fast and accurate alternative to Monte Carlo simulations, enabling practical system optimization under realistic quantization constraints.
Robust Channel Estimation for Optical Wireless Communications Using Neural Network
Apr 02, 2025Optical Wireless Communication (OWC) has gained significant attention due to its high-speed data transmission and throughput. Optical wireless channels are often assumed to be flat, but we evaluate frequency selective channels to consider high data rate optical wireless or very dispersive environments. To address this for optical scenarios, this paper presents a robust channel estimation framework with low-complexity to mitigate frequency-selective effects, then to improve system reliability and performance. This channel estimation framework contains a neural network that can estimate general optical wireless channels without prior channel information about the environment. Based on this estimate and the corresponding delay spread, one of several candidate offline-trained neural networks will be activated to predict this channel. Simulation results demonstrate that the proposed method has improved and robust normalized mean square error (NMSE) and bit error rate (BER) performance compared to conventional estimation methods while maintaining computational efficiency. These findings highlight the potential of neural network solutions in enhancing the performance of OWC systems under indoor channel conditions.
Antenna Health-Aware Selective Beamforming for Hardware-Constrained DFRC Systems II
Dec 23, 2024This study introduces an innovative beamforming design approach that incorporates the reliability of antenna array elements into the optimization process, termed "antenna health-aware selective beamforming". This method strategically focuses transmission power on more reliable antenna elements, thus enhancing system resilience and operational integrity. By integrating antenna health information and individual power constraints, our research leverages advanced optimization techniques such as the Group Proximal-Gradient Dual Ascent (GPGDA) to efficiently address nonconvex challenges in sparse array selection. Applying the proposed technique to a Dual-Functional Radar-Communication (DFRC) system, our findings highlight that increasing the sparsity promotion weight ($\rho_s$) generally boosts spectral efficiency and communication data rate, achieving perfect system reliability at higher $\rho_s$ values but also revealing a performance threshold beyond which further sparsity is detrimental. This underscores the importance of balanced sparsity in beamforming for optimizing performance, particularly in critical communication and defense applications where uninterrupted operation is crucial. Additionally, our analysis of the time complexity and power consumption associated with GPGDA underscores the need for optimizing computational resources in practical implementations.
Detection with Uncertainty in Target Direction for Dual Functional Radar and Communication Systems
Dec 10, 2024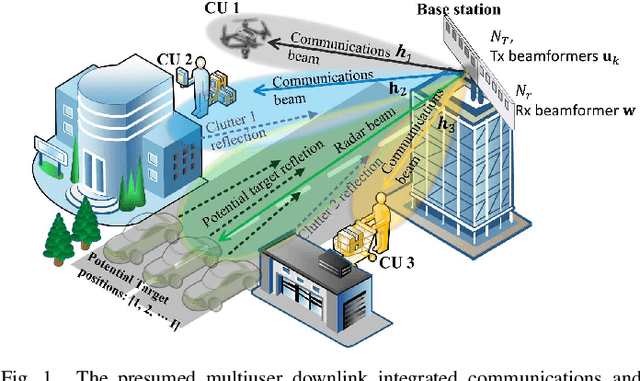
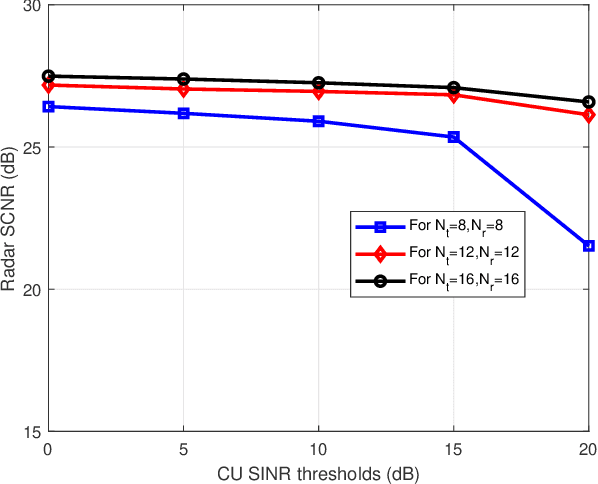
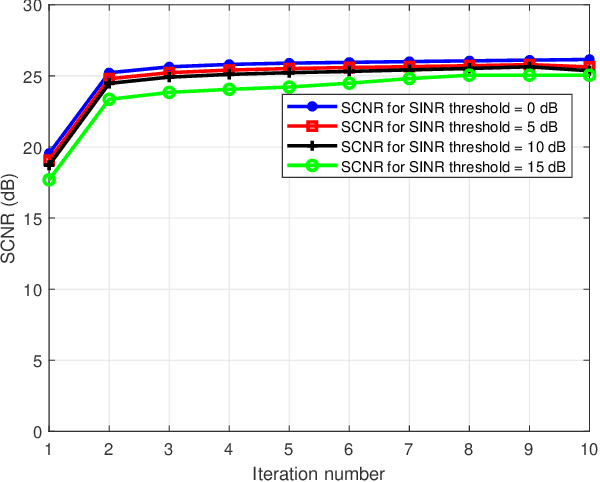
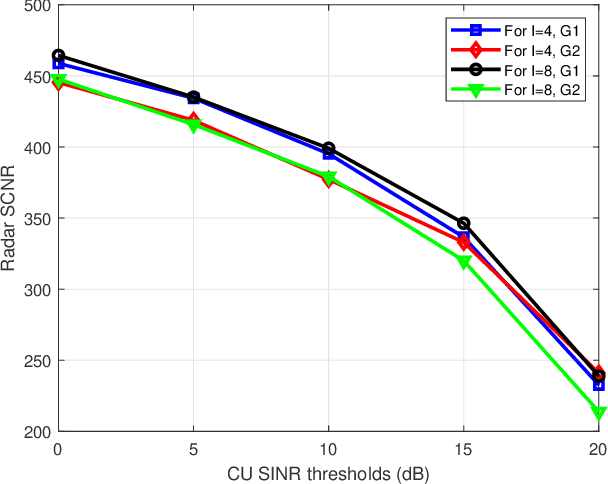
Dual functional radar and communication (DFRC) systems are a viable approach to extend the services of future communication systems. Most studies designing DFRC systems assume that the target direction is known. In our paper, we address a critical scenario where this information is not exactly known. For such a system, a signal-to-clutter-plus-noise ratio (SCNR) maximization problem is formulated. Quality-of-service constraints for communication users (CUs) are also incorporated as constraints on their received signal-to-interference-plus-noise ratios (SINRs). To tackle the nonconvexity, an iterative alternating optimization approach is developed where, at each iteration, the optimization is alternatively performed with respect to transmit and receive beamformers. Specifically, a penalty-based approach is used to obtain an efficient sub-optimal solution for the resulting subproblem with regard to transmit beamformers. Next, a globally optimal solution is obtained for receive beamformers with the help of the Dinkleback approach. The convergence of the proposed algorithm is also proved by proving the nondecreasing nature of the objective function with iterations. The numerical results illustrate the effectiveness of the proposed approach. Specifically, it is observed that the proposed algorithm converges within almost 3 iterations, and the SCNR performance is almost unchanged with the number of possible target directions.
Data Formulator: AI-powered Concept-driven Visualization Authoring
Sep 18, 2023



With most modern visualization tools, authors need to transform their data into tidy formats to create visualizations they want. Because this requires experience with programming or separate data processing tools, data transformation remains a barrier in visualization authoring. To address this challenge, we present a new visualization paradigm, concept binding, that separates high-level visualization intents and low-level data transformation steps, leveraging an AI agent. We realize this paradigm in Data Formulator, an interactive visualization authoring tool. With Data Formulator, authors first define data concepts they plan to visualize using natural languages or examples, and then bind them to visual channels. Data Formulator then dispatches its AI-agent to automatically transform the input data to surface these concepts and generate desired visualizations. When presenting the results (transformed table and output visualizations) from the AI agent, Data Formulator provides feedback to help authors inspect and understand them. A user study with 10 participants shows that participants could learn and use Data Formulator to create visualizations that involve challenging data transformations, and presents interesting future research directions.
Channelformer: Attention based Neural Solution for Wireless Channel Estimation and Effective Online Training
Feb 08, 2023In this paper, we propose an encoder-decoder neural architecture (called Channelformer) to achieve improved channel estimation for orthogonal frequency-division multiplexing (OFDM) waveforms in downlink scenarios. The self-attention mechanism is employed to achieve input precoding for the input features before processing them in the decoder. In particular, we implement multi-head attention in the encoder and a residual convolutional neural architecture as the decoder, respectively. We also employ a customized weight-level pruning to slim the trained neural network with a fine-tuning process, which reduces the computational complexity significantly to realize a low complexity and low latency solution. This enables reductions of up to 70\% in the parameters, while maintaining an almost identical performance compared with the complete Channelformer. We also propose an effective online training method based on the fifth generation (5G) new radio (NR) configuration for the modern communication systems, which only needs the available information at the receiver for online training. Using industrial standard channel models, the simulations of attention-based solutions show superior estimation performance compared with other candidate neural network methods for channel estimation.
Achieving Robust Generalization for Wireless Channel Estimation Neural Networks by Designed Training Data
Feb 05, 2023In this paper, we propose a method to design the training data that can support robust generalization of trained neural networks to unseen channels. The proposed design that improves the generalization is described and analysed. It avoids the requirement of online training for previously unseen channels, as this is a memory and processing intensive solution, especially for battery powered mobile terminals. To prove the validity of the proposed method, we use the channels modelled by different standards and fading modelling for simulation. We also use an attention-based structure and a convolutional neural network to evaluate the generalization results achieved. Simulation results show that the trained neural networks maintain almost identical performance on the unseen channels.
Attention Based Neural Networks for Wireless Channel Estimation
Apr 28, 2022



In this paper, we deploy the self-attention mechanism to achieve improved channel estimation for orthogonal frequency-division multiplexing waveforms in the downlink. Specifically, we propose a new hybrid encoder-decoder structure (called HA02) for the first time which exploits the attention mechanism to focus on the most important input information. In particular, we implement a transformer encoder block as the encoder to achieve the sparsity in the input features and a residual neural network as the decoder respectively, inspired by the success of the attention mechanism. Using 3GPP channel models, our simulations show superior estimation performance compared with other candidate neural network methods for channel estimation.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.