 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFace Recognition Using Synthetic Face Data
May 17, 2023In the field of deep learning applied to face recognition, securing large-scale, high-quality datasets is vital for attaining precise and reliable results. However, amassing significant volumes of high-quality real data faces hurdles such as time limitations, financial burdens, and privacy issues. Furthermore, prevalent datasets are often impaired by racial biases and annotation inaccuracies. In this paper, we underscore the promising application of synthetic data, generated through rendering digital faces via our computer graphics pipeline, in achieving competitive results with the state-of-the-art on synthetic data across multiple benchmark datasets. By finetuning the model,we obtain results that rival those achieved when training with hundreds of thousands of real images (98.7% on LFW [1]). We further investigate the contribution of adding intra-class variance factors (e.g., makeup, accessories, haircuts) on model performance. Finally, we reveal the sensitivity of pre-trained face recognition models to alternating specific parts of the face by leveraging the granular control capability in our platform.
Knowing the Distance: Understanding the Gap Between Synthetic and Real Data For Face Parsing
Mar 27, 2023
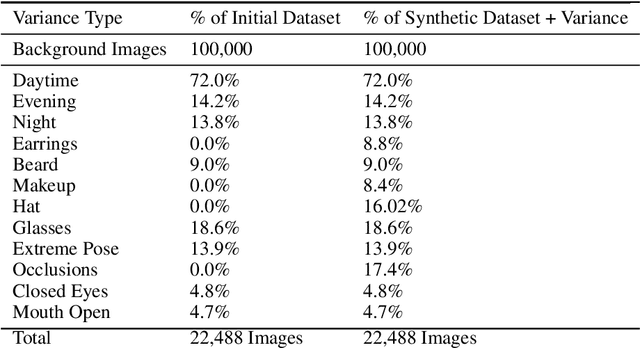

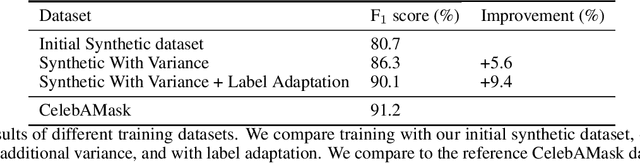
The use of synthetic data for training computer vision algorithms has become increasingly popular due to its cost-effectiveness, scalability, and ability to provide accurate multi-modality labels. Although recent studies have demonstrated impressive results when training networks solely on synthetic data, there remains a performance gap between synthetic and real data that is commonly attributed to lack of photorealism. The aim of this study is to investigate the gap in greater detail for the face parsing task. We differentiate between three types of gaps: distribution gap, label gap, and photorealism gap. Our findings show that the distribution gap is the largest contributor to the performance gap, accounting for over 50% of the gap. By addressing this gap and accounting for the labels gap, we demonstrate that a model trained on synthetic data achieves comparable results to one trained on a similar amount of real data. This suggests that synthetic data is a viable alternative to real data, especially when real data is limited or difficult to obtain. Our study highlights the importance of content diversity in synthetic datasets and challenges the notion that the photorealism gap is the most critical factor affecting the performance of computer vision models trained on synthetic data.
Federated Learning Enables Big Data for Rare Cancer Boundary Detection
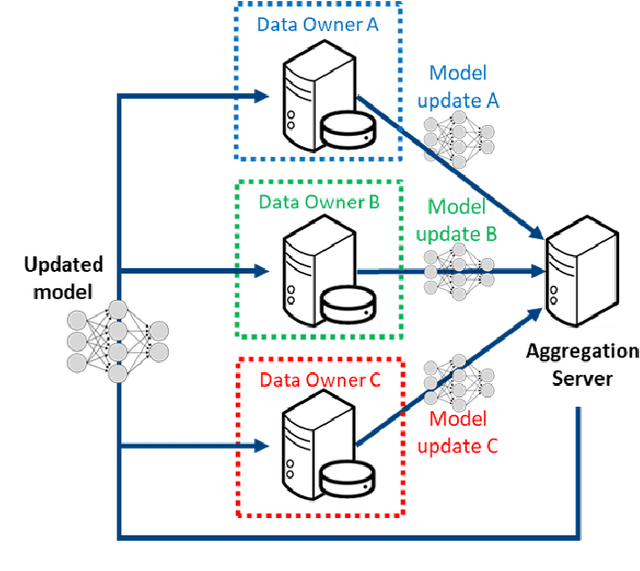
Apr 25, 2022Although machine learning (ML) has shown promise in numerous domains, there are concerns about generalizability to out-of-sample data. This is currently addressed by centrally sharing ample, and importantly diverse, data from multiple sites. However, such centralization is challenging to scale (or even not feasible) due to various limitations. Federated ML (FL) provides an alternative to train accurate and generalizable ML models, by only sharing numerical model updates. Here we present findings from the largest FL study to-date, involving data from 71 healthcare institutions across 6 continents, to generate an automatic tumor boundary detector for the rare disease of glioblastoma, utilizing the largest dataset of such patients ever used in the literature (25,256 MRI scans from 6,314 patients). We demonstrate a 33% improvement over a publicly trained model to delineate the surgically targetable tumor, and 23% improvement over the tumor's entire extent. We anticipate our study to: 1) enable more studies in healthcare informed by large and diverse data, ensuring meaningful results for rare diseases and underrepresented populations, 2) facilitate further quantitative analyses for glioblastoma via performance optimization of our consensus model for eventual public release, and 3) demonstrate the effectiveness of FL at such scale and task complexity as a paradigm shift for multi-site collaborations, alleviating the need for data sharing.
The Federated Tumor Segmentation (FeTS) Challenge
May 14, 2021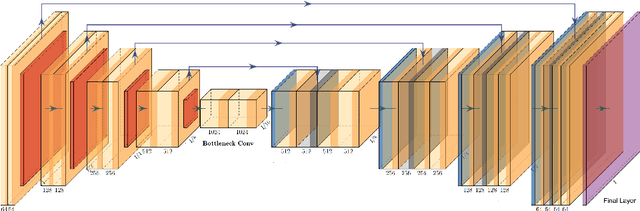
This manuscript describes the first challenge on Federated Learning, namely the Federated Tumor Segmentation (FeTS) challenge 2021. International challenges have become the standard for validation of biomedical image analysis methods. However, the actual performance of participating (even the winning) algorithms on "real-world" clinical data often remains unclear, as the data included in challenges are usually acquired in very controlled settings at few institutions. The seemingly obvious solution of just collecting increasingly more data from more institutions in such challenges does not scale well due to privacy and ownership hurdles. Towards alleviating these concerns, we are proposing the FeTS challenge 2021 to cater towards both the development and the evaluation of models for the segmentation of intrinsically heterogeneous (in appearance, shape, and histology) brain tumors, namely gliomas. Specifically, the FeTS 2021 challenge uses clinically acquired, multi-institutional magnetic resonance imaging (MRI) scans from the BraTS 2020 challenge, as well as from various remote independent institutions included in the collaborative network of a real-world federation (https://www.fets.ai/). The goals of the FeTS challenge are directly represented by the two included tasks: 1) the identification of the optimal weight aggregation approach towards the training of a consensus model that has gained knowledge via federated learning from multiple geographically distinct institutions, while their data are always retained within each institution, and 2) the federated evaluation of the generalizability of brain tumor segmentation models "in the wild", i.e. on data from institutional distributions that were not part of the training datasets.
OpenFL: An open-source framework for Federated Learning
May 13, 2021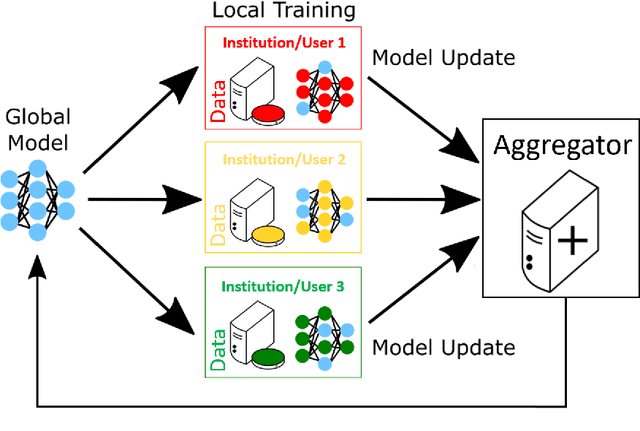
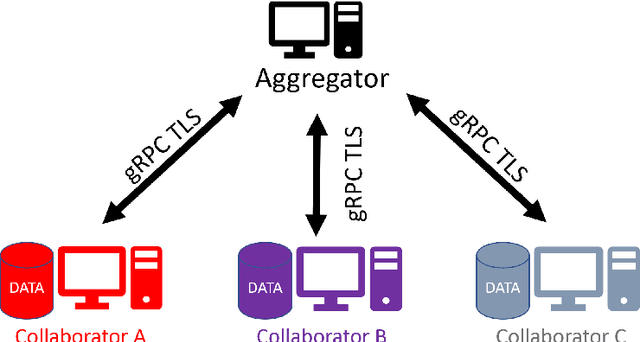
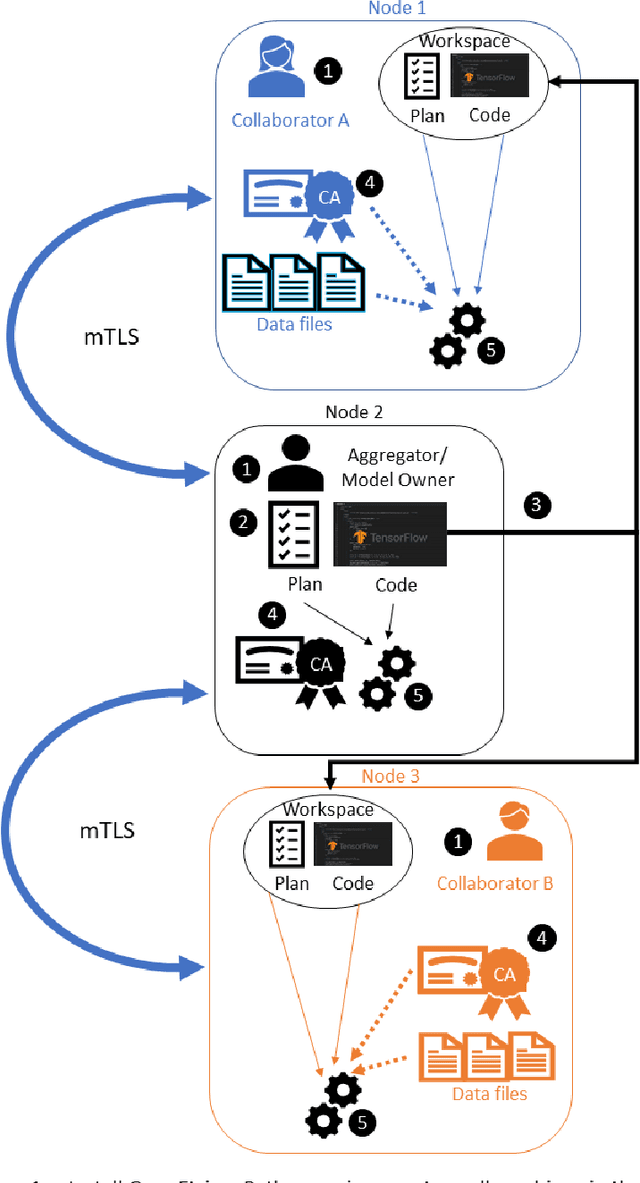
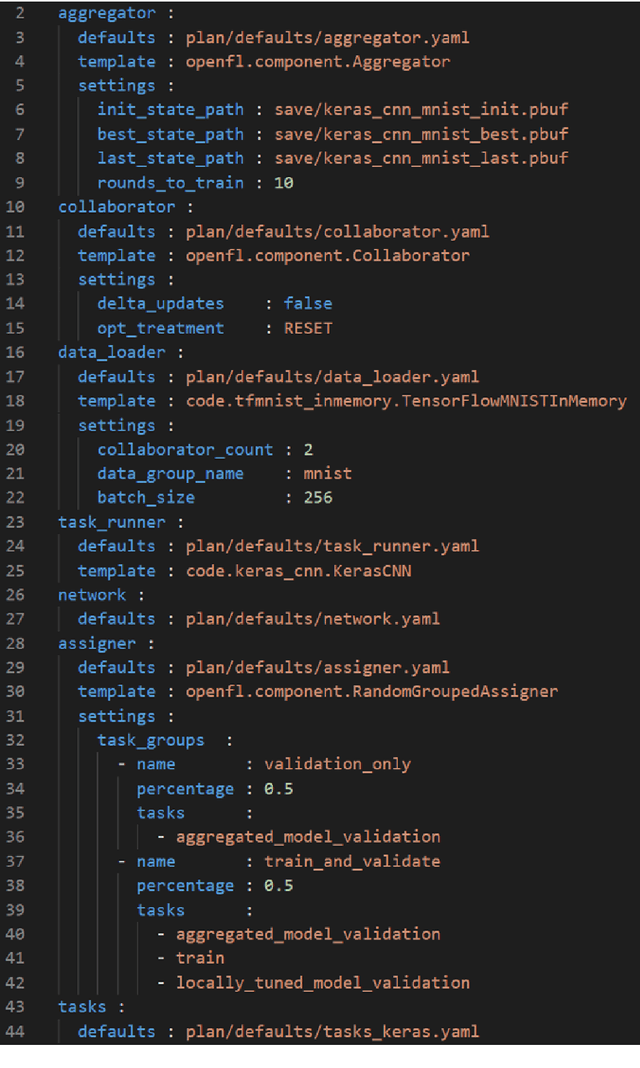
Federated learning (FL) is a computational paradigm that enables organizations to collaborate on machine learning (ML) projects without sharing sensitive data, such as, patient records, financial data, or classified secrets. Open Federated Learning (OpenFL https://github.com/intel/openfl) is an open-source framework for training ML algorithms using the data-private collaborative learning paradigm of FL. OpenFL works with training pipelines built with both TensorFlow and PyTorch, and can be easily extended to other ML and deep learning frameworks. Here, we summarize the motivation and development characteristics of OpenFL, with the intention of facilitating its application to existing ML model training in a production environment. Finally, we describe the first use of the OpenFL framework to train consensus ML models in a consortium of international healthcare organizations, as well as how it facilitates the first computational competition on FL.
LPRNet: License Plate Recognition via Deep Neural Networks
Jun 27, 2018

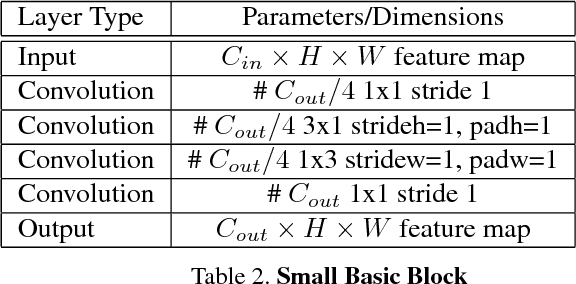

This paper proposes LPRNet - end-to-end method for Automatic License Plate Recognition without preliminary character segmentation. Our approach is inspired by recent breakthroughs in Deep Neural Networks, and works in real-time with recognition accuracy up to 95% for Chinese license plates: 3 ms/plate on nVIDIA GeForce GTX 1080 and 1.3 ms/plate on Intel Core i7-6700K CPU. LPRNet consists of the lightweight Convolutional Neural Network, so it can be trained in end-to-end way. To the best of our knowledge, LPRNet is the first real-time License Plate Recognition system that does not use RNNs. As a result, the LPRNet algorithm may be used to create embedded solutions for LPR that feature high level accuracy even on challenging Chinese license plates.