 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEcho State Networks for Bitcoin Time Series Prediction
Aug 07, 2025Forecasting stock and cryptocurrency prices is challenging due to high volatility and non-stationarity, influenced by factors like economic changes and market sentiment. Previous research shows that Echo State Networks (ESNs) can effectively model short-term stock market movements, capturing nonlinear patterns in dynamic data. To the best of our knowledge, this work is among the first to explore ESNs for cryptocurrency forecasting, especially during extreme volatility. We also conduct chaos analysis through the Lyapunov exponent in chaotic periods and show that our approach outperforms existing machine learning methods by a significant margin. Our findings are consistent with the Lyapunov exponent analysis, showing that ESNs are robust during chaotic periods and excel under high chaos compared to Boosting and Na\"ive methods.
Post-training Model Quantization Using GANs for Synthetic Data Generation
May 10, 2023



Quantization is a widely adopted technique for deep neural networks to reduce the memory and computational resources required. However, when quantized, most models would need a suitable calibration process to keep their performance intact, which requires data from the target domain, such as a fraction of the dataset used in model training and model validation (i.e. calibration dataset). In this study, we investigate the use of synthetic data as a substitute for the calibration with real data for the quantization method. We propose a data generation method based on Generative Adversarial Networks that are trained prior to the model quantization step. We compare the performance of models quantized using data generated by StyleGAN2-ADA and our pre-trained DiStyleGAN, with quantization using real data and an alternative data generation method based on fractal images. Overall, the results of our experiments demonstrate the potential of leveraging synthetic data for calibration during the quantization process. In our experiments, the percentage of accuracy degradation of the selected models was less than 0.6%, with our best performance achieved on MobileNetV2 (0.05%). The code is available at: https://github.com/ThanosM97/gsoc2022-openvino
2T-UNET: A Two-Tower UNet with Depth Clues for Robust Stereo Depth Estimation
Oct 27, 2022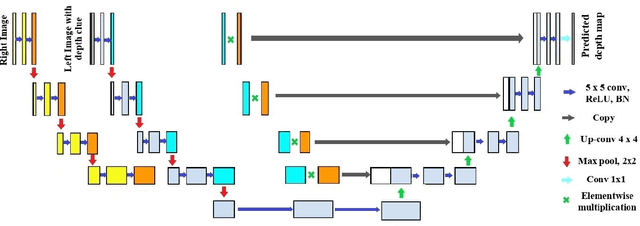
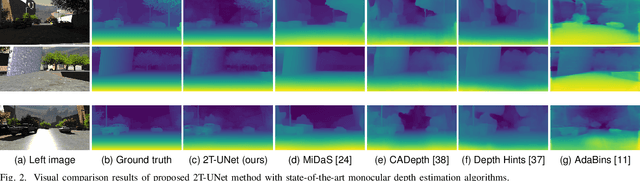
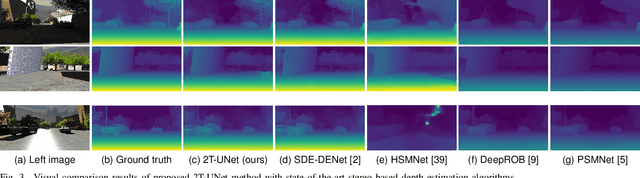

Stereo correspondence matching is an essential part of the multi-step stereo depth estimation process. This paper revisits the depth estimation problem, avoiding the explicit stereo matching step using a simple two-tower convolutional neural network. The proposed algorithm is entitled as 2T-UNet. The idea behind 2T-UNet is to replace cost volume construction with twin convolution towers. These towers have an allowance for different weights between them. Additionally, the input for twin encoders in 2T-UNet are different compared to the existing stereo methods. Generally, a stereo network takes a right and left image pair as input to determine the scene geometry. However, in the 2T-UNet model, the right stereo image is taken as one input and the left stereo image along with its monocular depth clue information, is taken as the other input. Depth clues provide complementary suggestions that help enhance the quality of predicted scene geometry. The 2T-UNet surpasses state-of-the-art monocular and stereo depth estimation methods on the challenging Scene flow dataset, both quantitatively and qualitatively. The architecture performs incredibly well on complex natural scenes, highlighting its usefulness for various real-time applications. Pretrained weights and code will be made readily available.
A Novel Approach for Neuromorphic Vision Data Compression based on Deep Belief Network
Oct 27, 2022



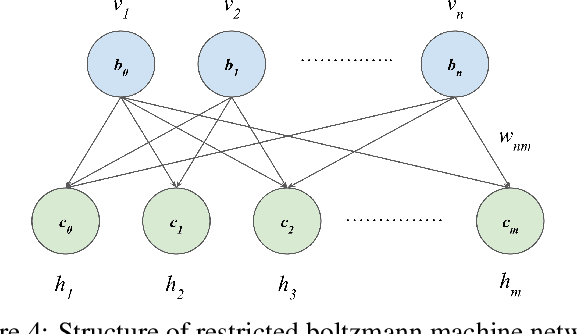
A neuromorphic camera is an image sensor that emulates the human eyes capturing only changes in local brightness levels. They are widely known as event cameras, silicon retinas or dynamic vision sensors (DVS). DVS records asynchronous per-pixel brightness changes, resulting in a stream of events that encode the brightness change's time, location, and polarity. DVS consumes little power and can capture a wider dynamic range with no motion blur and higher temporal resolution than conventional frame-based cameras. Although this method of event capture results in a lower bit rate than traditional video capture, it is further compressible. This paper proposes a novel deep learning-based compression scheme for event data. Using a deep belief network (DBN), the high dimensional event data is reduced into a latent representation and later encoded using an entropy-based coding technique. The proposed scheme is among the first to incorporate deep learning for event compression. It achieves a high compression ratio while maintaining good reconstruction quality outperforming state-of-the-art event data coders and other lossless benchmark techniques.
A Novel Light Field Coding Scheme Based on Deep Belief Network and Weighted Binary Images for Additive Layered Displays
Oct 04, 2022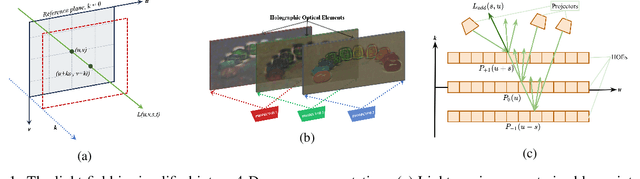

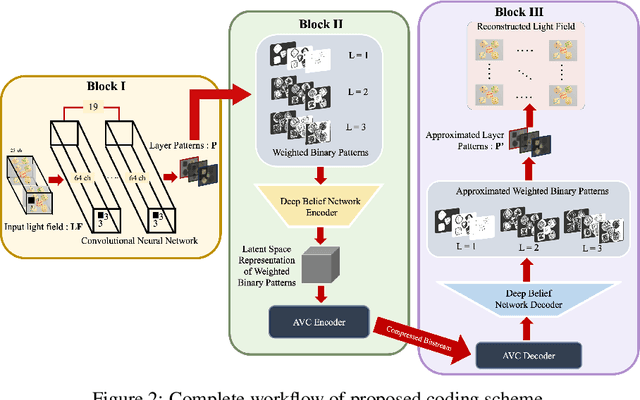
Light field display caters to the viewer's immersive experience by providing binocular depth sensation and motion parallax. Glasses-free tensor light field display is becoming a prominent area of research in auto-stereoscopic display technology. Stacking light attenuating layers is one of the approaches to implement a light field display with a good depth of field, wide viewing angles and high resolution. This paper presents a compact and efficient representation of light field data based on scalable compression of the binary represented image layers suitable for additive layered display using a Deep Belief Network (DBN). The proposed scheme learns and optimizes the additive layer patterns using a convolutional neural network (CNN). Weighted binary images represent the optimized patterns, reducing the file size and introducing scalable encoding. The DBN further compresses the weighted binary patterns into a latent space representation followed by encoding the latent data using an h.254 codec. The proposed scheme is compared with benchmark codecs such as h.264 and h.265 and achieved competitive performance on light field data.
A High Resolution Multi-exposure Stereoscopic Image & Video Database of Natural Scenes
Jun 22, 2022


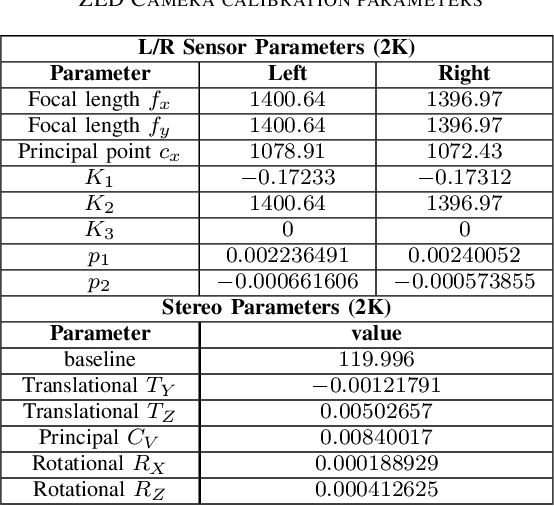
Immersive displays such as VR headsets, AR glasses, Multiview displays, Free point televisions have emerged as a new class of display technologies in recent years, offering a better visual experience and viewer engagement as compared to conventional displays. With the evolution of 3D video and display technologies, the consumer market for High Dynamic Range (HDR) cameras and displays is quickly growing. The lack of appropriate experimental data is a critical hindrance for the development of primary research efforts in the field of 3D HDR video technology. Also, the unavailability of sufficient real world multi-exposure experimental dataset is a major bottleneck for HDR imaging research, thereby limiting the quality of experience (QoE) for the viewers. In this paper, we introduce a diversified stereoscopic multi-exposure dataset captured within the campus of Indian Institute of Technology Madras, which is home to a diverse flora and fauna. The dataset is captured using ZED stereoscopic camera and provides intricate scenes of outdoor locations such as gardens, roadside views, festival venues, buildings and indoor locations such as academic and residential areas. The proposed dataset accommodates wide depth range, complex depth structure, complicate object movement, illumination variations, rich color dynamics, texture discrepancy in addition to significant randomness introduced by moving camera and background motion. The proposed dataset is made publicly available to the research community. Furthermore, the procedure for capturing, aligning and calibrating multi-exposure stereo videos and images is described in detail. Finally, we have discussed the progress, challenges, potential use cases and future research opportunities with respect to HDR imaging, depth estimation, consistent tone mapping and 3D HDR coding.
MEStereo-Du2CNN: A Novel Dual Channel CNN for Learning Robust Depth Estimates from Multi-exposure Stereo Images for HDR 3D Applications
Jun 21, 2022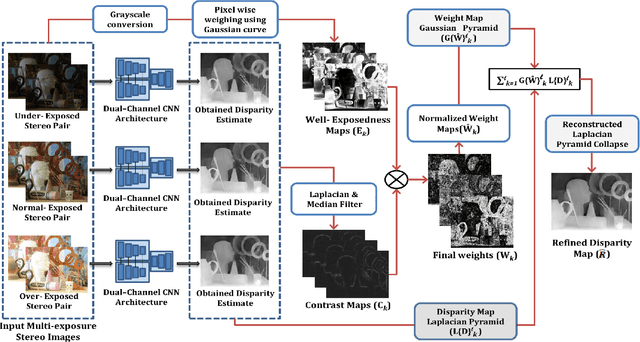
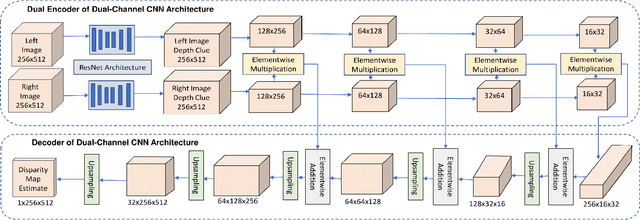
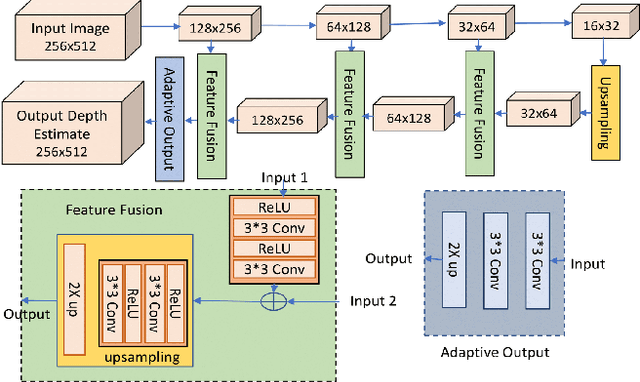

Display technologies have evolved over the years. It is critical to develop practical HDR capturing, processing, and display solutions to bring 3D technologies to the next level. Depth estimation of multi-exposure stereo image sequences is an essential task in the development of cost-effective 3D HDR video content. In this paper, we develop a novel deep architecture for multi-exposure stereo depth estimation. The proposed architecture has two novel components. First, the stereo matching technique used in traditional stereo depth estimation is revamped. For the stereo depth estimation component of our architecture, a mono-to-stereo transfer learning approach is deployed. The proposed formulation circumvents the cost volume construction requirement, which is replaced by a ResNet based dual-encoder single-decoder CNN with different weights for feature fusion. EfficientNet based blocks are used to learn the disparity. Secondly, we combine disparity maps obtained from the stereo images at different exposure levels using a robust disparity feature fusion approach. The disparity maps obtained at different exposures are merged using weight maps calculated for different quality measures. The final predicted disparity map obtained is more robust and retains best features that preserve the depth discontinuities. The proposed CNN offers flexibility to train using standard dynamic range stereo data or with multi-exposure low dynamic range stereo sequences. In terms of performance, the proposed model surpasses state-of-the-art monocular and stereo depth estimation methods, both quantitatively and qualitatively, on challenging Scene flow and differently exposed Middlebury stereo datasets. The architecture performs exceedingly well on complex natural scenes, demonstrating its usefulness for diverse 3D HDR applications.
An Integrated Representation & Compression Scheme Based on Convolutional Autoencoders with 4D DCT Perceptual Encoding for High Dynamic Range Light Fields
Jun 21, 2022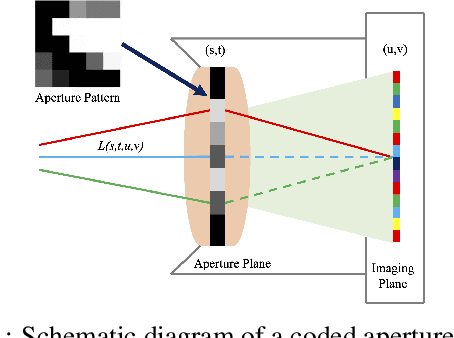
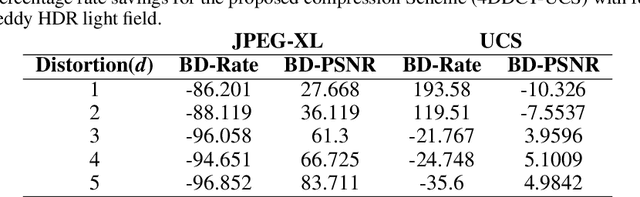
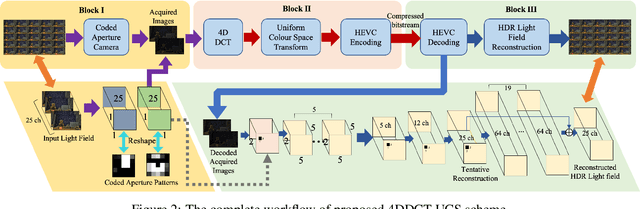
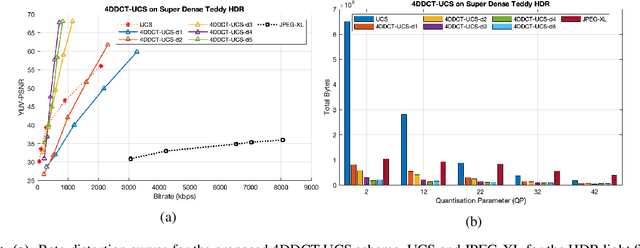
The emerging and existing light field displays are highly capable of realistic presentation of 3D scenes on auto-stereoscopic glasses-free platforms. The light field size is a major drawback while utilising 3D displays and streaming purposes. When a light field is of high dynamic range, the size increases drastically. In this paper, we propose a novel compression algorithm for a high dynamic range light field which yields a perceptually lossless compression. The algorithm exploits the inter and intra view correlations of the HDR light field by interpreting it to be a four-dimension volume. The HDR light field compression is based on a novel 4DDCT-UCS (4D-DCT Uniform Colour Space) algorithm. Additional encoding of 4DDCT-UCS acquired images by HEVC eliminates intra-frame, inter-frame and intrinsic redundancies in HDR light field data. Comparison with state-of-the-art coders like JPEG-XL and HDR video coding algorithm exhibits superior compression performance of the proposed scheme for real-world light fields.
A Robust and Scalable Attention Guided Deep Learning Framework for Movement Quality Assessment
Apr 16, 2022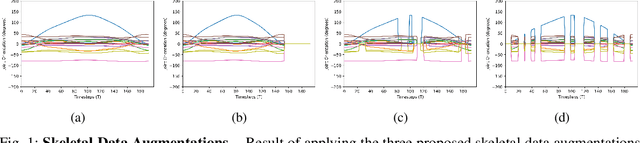
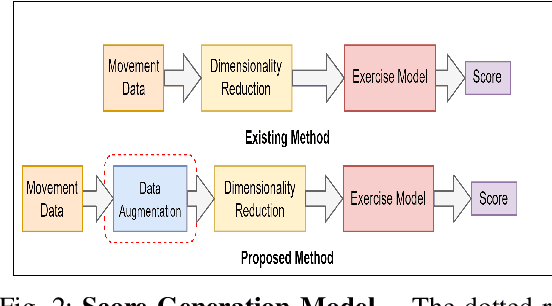
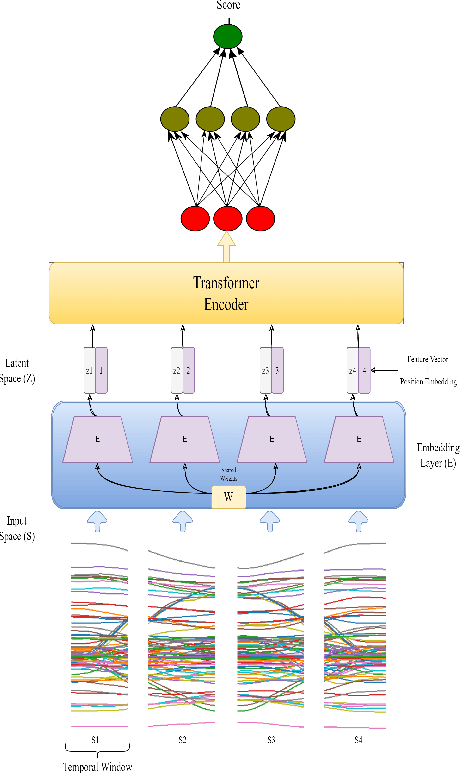
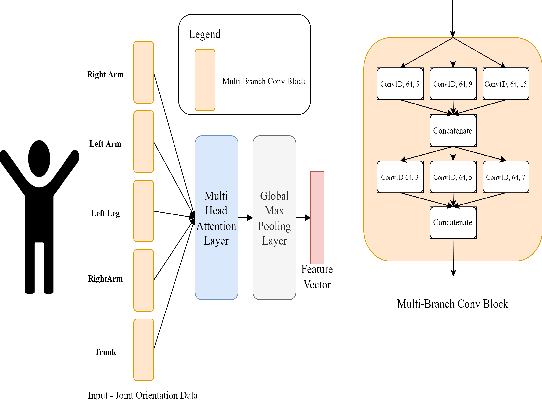
Physical rehabilitation programs frequently begin with a brief stay in the hospital and continue with home-based rehabilitation. Lack of feedback on exercise correctness is a significant issue in home-based rehabilitation. Automated movement quality assessment (MQA) using skeletal movement data (hereafter referred to as skeletal data) collected via depth imaging devices can assist with home-based rehabilitation by providing the necessary quantitative feedback. This paper aims to use recent advances in deep learning to address the problem of MQA. Movement quality score generation is an essential component of MQA. We propose three novel skeletal data augmentation schemes. We show that using the proposed augmentations for generating movement quality scores result in significant performance boosts over existing methods. Finally, we propose a novel transformer based architecture for MQA. Four novel feature extractors are proposed and studied that allow the transformer network to operate on skeletal data. We show that adding the attention mechanism in the design of the proposed feature extractor allows the transformer network to pay attention to specific body parts that make a significant contribution towards executing a movement. We report an improvement in movement quality score prediction of 12% on UI-PRMD dataset and 21% on KIMORE dataset compared to the existing methods.
Tactile-ViewGCN: Learning Shape Descriptor from Tactile Data using Graph Convolutional Network
Mar 12, 2022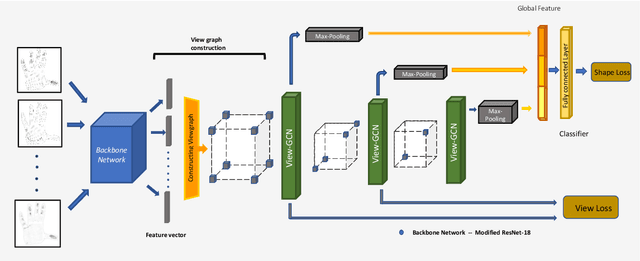
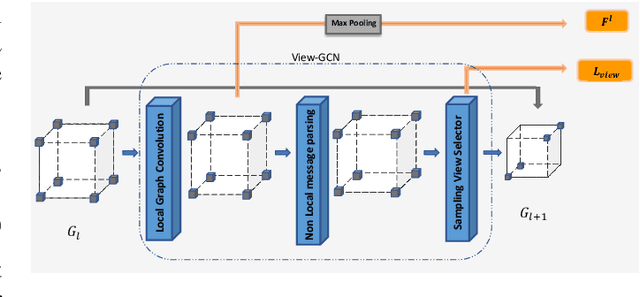
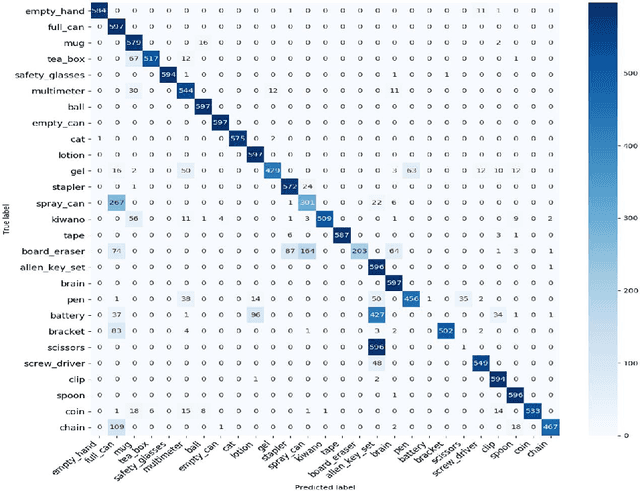
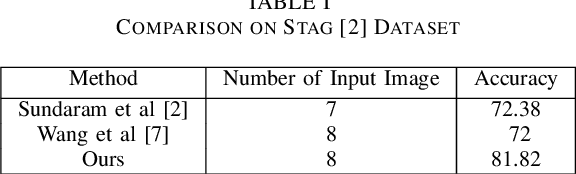
For humans, our "senses of touch" have always been necessary for our ability to precisely and efficiently manipulate objects of all shapes in any environment, but until recently, not many works have been done to fully understand haptic feedback. This work proposed a novel method for getting a better shape descriptor than existing methods for classifying an object from multiple tactile data collected from a tactile glove. It focuses on improving previous works on object classification using tactile data. The major problem for object classification from multiple tactile data is to find a good way to aggregate features extracted from multiple tactile images. We propose a novel method, dubbed as Tactile-ViewGCN, that hierarchically aggregate tactile features considering relations among different features by using Graph Convolutional Network. Our model outperforms previous methods on the STAG dataset with an accuracy of 81.82%.