 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniHorizon: In-the-Wild Outdoors Depth and Normal Estimation from Synthetic Omnidirectional Dataset
Dec 09, 2022Understanding the ambient scene is imperative for several applications such as autonomous driving and navigation. While obtaining real-world image data with per-pixel labels is challenging, existing accurate synthetic image datasets primarily focus on indoor spaces with fixed lighting and scene participants, thereby severely limiting their application to outdoor scenarios. In this work we introduce OmniHorizon, a synthetic dataset with 24,335 omnidirectional views comprising of a broad range of indoor and outdoor spaces consisting of buildings, streets, and diverse vegetation. Our dataset also accounts for dynamic scene components including lighting, different times of a day settings, pedestrians, and vehicles. Furthermore, we also demonstrate a learned synthetic-to-real cross-domain inference method for in-the-wild 3D scene depth and normal estimation method using our dataset. To this end, we propose UBotNet, an architecture based on a UNet and a Bottleneck Transformer, to estimate scene-consistent normals. We show that UBotNet achieves significantly improved depth accuracy (4.6%) and normal estimation (5.75%) compared to several existing networks such as U-Net with skip-connections. Finally, we demonstrate in-the-wild depth and normal estimation on real-world images with UBotNet trained purely on our OmniHorizon dataset, showing the promise of proposed dataset and network for scene understanding.
VisTaNet: Attention Guided Deep Fusion for Surface Roughness Classification
Sep 18, 2022



Human texture perception is a weighted average of multi-sensory inputs: visual and tactile. While the visual sensing mechanism extracts global features, the tactile mechanism complements it by extracting local features. The lack of coupled visuotactile datasets in the literature is a challenge for studying multimodal fusion strategies analogous to human texture perception. This paper presents a visual dataset that augments an existing tactile dataset. We propose a novel deep fusion architecture that fuses visual and tactile data using four types of fusion strategies: summation, concatenation, max-pooling, and attention. Our model shows significant performance improvements (97.22%) in surface roughness classification accuracy over tactile only (SVM - 92.60%) and visual only (FENet-50 - 85.01%) architectures. Among the several fusion techniques, attention-guided architecture results in better classification accuracy. Our study shows that analogous to human texture perception, the proposed model chooses a weighted combination of the two modalities (visual and tactile), thus resulting in higher surface roughness classification accuracy; and it chooses to maximize the weightage of the tactile modality where the visual modality fails and vice-versa.
A Robust and Scalable Attention Guided Deep Learning Framework for Movement Quality Assessment
Apr 16, 2022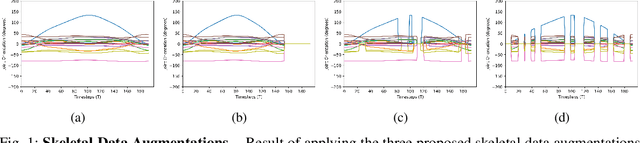
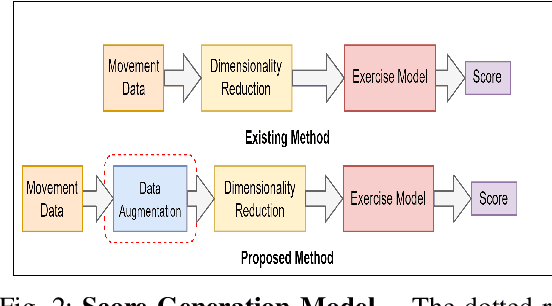
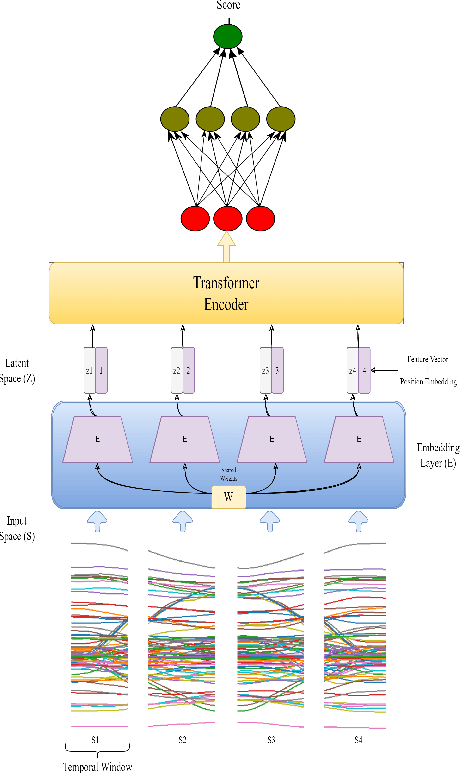
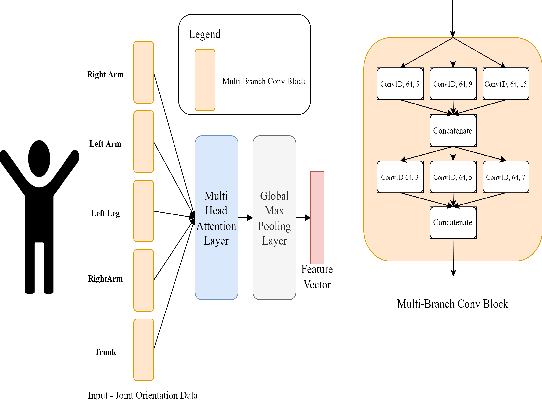
Physical rehabilitation programs frequently begin with a brief stay in the hospital and continue with home-based rehabilitation. Lack of feedback on exercise correctness is a significant issue in home-based rehabilitation. Automated movement quality assessment (MQA) using skeletal movement data (hereafter referred to as skeletal data) collected via depth imaging devices can assist with home-based rehabilitation by providing the necessary quantitative feedback. This paper aims to use recent advances in deep learning to address the problem of MQA. Movement quality score generation is an essential component of MQA. We propose three novel skeletal data augmentation schemes. We show that using the proposed augmentations for generating movement quality scores result in significant performance boosts over existing methods. Finally, we propose a novel transformer based architecture for MQA. Four novel feature extractors are proposed and studied that allow the transformer network to operate on skeletal data. We show that adding the attention mechanism in the design of the proposed feature extractor allows the transformer network to pay attention to specific body parts that make a significant contribution towards executing a movement. We report an improvement in movement quality score prediction of 12% on UI-PRMD dataset and 21% on KIMORE dataset compared to the existing methods.