 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Single-shot Structured Light 3D Imaging via Neural Feature Decoding
Dec 16, 2025We consider the problem of active 3D imaging using single-shot structured light systems, which are widely employed in commercial 3D sensing devices such as Apple Face ID and Intel RealSense. Traditional structured light methods typically decode depth correspondences through pixel-domain matching algorithms, resulting in limited robustness under challenging scenarios like occlusions, fine-structured details, and non-Lambertian surfaces. Inspired by recent advances in neural feature matching, we propose a learning-based structured light decoding framework that performs robust correspondence matching within feature space rather than the fragile pixel domain. Our method extracts neural features from the projected patterns and captured infrared (IR) images, explicitly incorporating their geometric priors by building cost volumes in feature space, achieving substantial performance improvements over pixel-domain decoding approaches. To further enhance depth quality, we introduce a depth refinement module that leverages strong priors from large-scale monocular depth estimation models, improving fine detail recovery and global structural coherence. To facilitate effective learning, we develop a physically-based structured light rendering pipeline, generating nearly one million synthetic pattern-image pairs with diverse objects and materials for indoor settings. Experiments demonstrate that our method, trained exclusively on synthetic data with multiple structured light patterns, generalizes well to real-world indoor environments, effectively processes various pattern types without retraining, and consistently outperforms both commercial structured light systems and passive stereo RGB-based depth estimation methods. Project page: https://namisntimpot.github.io/NSLweb/.
UniCoRN: Latent Diffusion-based Unified Controllable Image Restoration Network across Multiple Degradations
Mar 21, 2025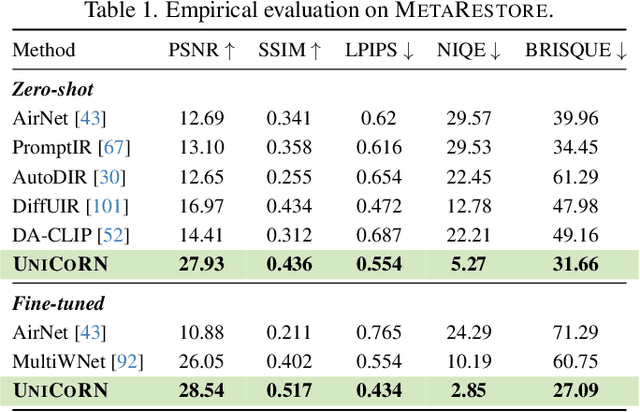


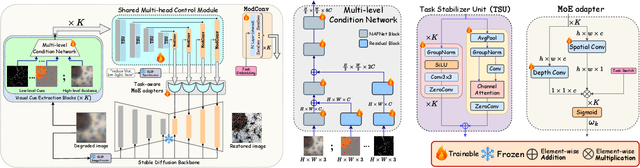
Image restoration is essential for enhancing degraded images across computer vision tasks. However, most existing methods address only a single type of degradation (e.g., blur, noise, or haze) at a time, limiting their real-world applicability where multiple degradations often occur simultaneously. In this paper, we propose UniCoRN, a unified image restoration approach capable of handling multiple degradation types simultaneously using a multi-head diffusion model. Specifically, we uncover the potential of low-level visual cues extracted from images in guiding a controllable diffusion model for real-world image restoration and we design a multi-head control network adaptable via a mixture-of-experts strategy. We train our model without any prior assumption of specific degradations, through a smartly designed curriculum learning recipe. Additionally, we also introduce MetaRestore, a metalens imaging benchmark containing images with multiple degradations and artifacts. Extensive evaluations on several challenging datasets, including our benchmark, demonstrate that our method achieves significant performance gains and can robustly restore images with severe degradations. Project page: https://codejaeger.github.io/unicorn-gh
High-Speed Dynamic 3D Imaging with Sensor Fusion Splatting
Feb 07, 2025



Capturing and reconstructing high-speed dynamic 3D scenes has numerous applications in computer graphics, vision, and interdisciplinary fields such as robotics, aerodynamics, and evolutionary biology. However, achieving this using a single imaging modality remains challenging. For instance, traditional RGB cameras suffer from low frame rates, limited exposure times, and narrow baselines. To address this, we propose a novel sensor fusion approach using Gaussian splatting, which combines RGB, depth, and event cameras to capture and reconstruct deforming scenes at high speeds. The key insight of our method lies in leveraging the complementary strengths of these imaging modalities: RGB cameras capture detailed color information, event cameras record rapid scene changes with microsecond resolution, and depth cameras provide 3D scene geometry. To unify the underlying scene representation across these modalities, we represent the scene using deformable 3D Gaussians. To handle rapid scene movements, we jointly optimize the 3D Gaussian parameters and their temporal deformation fields by integrating data from all three sensor modalities. This fusion enables efficient, high-quality imaging of fast and complex scenes, even under challenging conditions such as low light, narrow baselines, or rapid motion. Experiments on synthetic and real datasets captured with our prototype sensor fusion setup demonstrate that our method significantly outperforms state-of-the-art techniques, achieving noticeable improvements in both rendering fidelity and structural accuracy.
FlatTrack: Eye-tracking with ultra-thin lensless cameras
Jan 26, 2025Existing eye trackers use cameras based on thick compound optical elements, necessitating the cameras to be placed at focusing distance from the eyes. This results in the overall bulk of wearable eye trackers, especially for augmented and virtual reality (AR/VR) headsets. We overcome this limitation by building a compact flat eye gaze tracker using mask-based lensless cameras. These cameras, in combination with co-designed lightweight deep neural network algorithm, can be placed in extreme close proximity to the eye, within the eyeglasses frame, resulting in ultra-flat and lightweight eye gaze tracker system. We collect a large dataset of near-eye lensless camera measurements along with their calibrated gaze directions for training the gaze tracking network. Through real and simulation experiments, we show that the proposed gaze tracking system performs on par with conventional lens-based trackers while maintaining a significantly flatter and more compact form-factor. Moreover, our gaze regressor boasts real-time (>125 fps) performance for gaze tracking.
Event fields: Capturing light fields at high speed, resolution, and dynamic range
Dec 09, 2024



Event cameras, which feature pixels that independently respond to changes in brightness, are becoming increasingly popular in high-speed applications due to their lower latency, reduced bandwidth requirements, and enhanced dynamic range compared to traditional frame-based cameras. Numerous imaging and vision techniques have leveraged event cameras for high-speed scene understanding by capturing high-framerate, high-dynamic range videos, primarily utilizing the temporal advantages inherent to event cameras. Additionally, imaging and vision techniques have utilized the light field-a complementary dimension to temporal information-for enhanced scene understanding. In this work, we propose "Event Fields", a new approach that utilizes innovative optical designs for event cameras to capture light fields at high speed. We develop the underlying mathematical framework for Event Fields and introduce two foundational frameworks to capture them practically: spatial multiplexing to capture temporal derivatives and temporal multiplexing to capture angular derivatives. To realize these, we design two complementary optical setups one using a kaleidoscope for spatial multiplexing and another using a galvanometer for temporal multiplexing. We evaluate the performance of both designs using a custom-built simulator and real hardware prototypes, showcasing their distinct benefits. Our event fields unlock the full advantages of typical light fields-like post-capture refocusing and depth estimation-now supercharged for high-speed and high-dynamic range scenes. This novel light-sensing paradigm opens doors to new applications in photography, robotics, and AR/VR, and presents fresh challenges in rendering and machine learning.
MetaFormer: High-fidelity Metalens Imaging via Aberration Correcting Transformers
Dec 05, 2024



Metalens is an emerging optical system with an irreplaceable merit in that it can be manufactured in ultra-thin and compact sizes, which shows great promise of various applications such as medical imaging and augmented/virtual reality (AR/VR). Despite its advantage in miniaturization, its practicality is constrained by severe aberrations and distortions, which significantly degrade the image quality. Several previous arts have attempted to address different types of aberrations, yet most of them are mainly designed for the traditional bulky lens and not convincing enough to remedy harsh aberrations of the metalens. While there have existed aberration correction methods specifically for metalens, they still fall short of restoration quality. In this work, we propose MetaFormer, an aberration correction framework for metalens-captured images, harnessing Vision Transformers (ViT) that has shown remarkable restoration performance in diverse image restoration tasks. Specifically, we devise a Multiple Adaptive Filters Guidance (MAFG), where multiple Wiener filters enrich the degraded input images with various noise-detail balances, enhancing output restoration quality. In addition, we introduce a Spatial and Transposed self-Attention Fusion (STAF) module, which aggregates features from spatial self-attention and transposed self-attention modules to further ameliorate aberration correction. We conduct extensive experiments, including correcting aberrated images and videos, and clean 3D reconstruction from the degraded images. The proposed method outperforms the previous arts by a significant margin. We further fabricate a metalens and verify the practicality of MetaFormer by restoring the images captured with the manufactured metalens in the wild. Code and pre-trained models are available at https://benhenryl.github.io/MetaFormer
Structured light with a million light planes per second
Nov 27, 2024



We introduce a structured light system that captures full-frame depth at rates of a thousand frames per second, four times faster than the previous state of the art. Our key innovation to this end is the design of an acousto-optic light scanning device that can scan light planes at rates up to two million planes per second. We combine this device with an event camera for structured light, using the sparse events triggered on the camera as we sweep a light plane on the scene for depth triangulation. In contrast to prior work, where light scanning is the bottleneck towards faster structured light operation, our light scanning device is three orders of magnitude faster than the event camera's full-frame bandwidth, thus allowing us to take full advantage of the event camera's fast operation. To surpass this bandwidth, we additionally demonstrate adaptive scanning of only regions of interest, at speeds an order of magnitude faster than the theoretical full-frame limit for event cameras.
End-to-End Hybrid Refractive-Diffractive Lens Design with Differentiable Ray-Wave Model
Jun 02, 2024



Hybrid refractive-diffractive lenses combine the light efficiency of refractive lenses with the information encoding power of diffractive optical elements (DOE), showing great potential as the next generation of imaging systems. However, accurately simulating such hybrid designs is generally difficult, and in particular, there are no existing differentiable image formation models for hybrid lenses with sufficient accuracy. In this work, we propose a new hybrid ray-tracing and wave-propagation (ray-wave) model for accurate simulation of both optical aberrations and diffractive phase modulation, where the DOE is placed between the last refractive surface and the image sensor, i.e. away from the Fourier plane that is often used as a DOE position. The proposed ray-wave model is fully differentiable, enabling gradient back-propagation for end-to-end co-design of refractive-diffractive lens optimization and the image reconstruction network. We validate the accuracy of the proposed model by comparing the simulated point spread functions (PSFs) with theoretical results, as well as simulation experiments that show our model to be more accurate than solutions implemented in commercial software packages like Zemax. We demonstrate the effectiveness of the proposed model through real-world experiments and show significant improvements in both aberration correction and extended depth-of-field (EDoF) imaging. We believe the proposed model will motivate further investigation into a wide range of applications in computational imaging, computational photography, and advanced optical design. Code will be released upon publication.
DOF-GS: Adjustable Depth-of-Field 3D Gaussian Splatting for Refocusing,Defocus Rendering and Blur Removal
May 27, 2024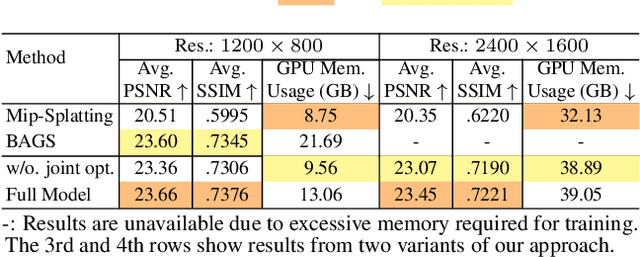
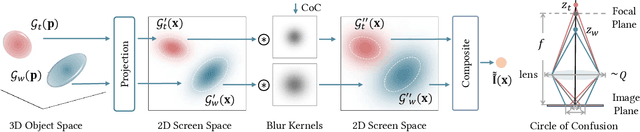


3D Gaussian Splatting-based techniques have recently advanced 3D scene reconstruction and novel view synthesis, achieving high-quality real-time rendering. However, these approaches are inherently limited by the underlying pinhole camera assumption in modeling the images and hence only work for All-in-Focus (AiF) sharp image inputs. This severely affects their applicability in real-world scenarios where images often exhibit defocus blur due to the limited depth-of-field (DOF) of imaging devices. Additionally, existing 3D Gaussian Splatting (3DGS) methods also do not support rendering of DOF effects. To address these challenges, we introduce DOF-GS that allows for rendering adjustable DOF effects, removing defocus blur as well as refocusing of 3D scenes, all from multi-view images degraded by defocus blur. To this end, we re-imagine the traditional Gaussian Splatting pipeline by employing a finite aperture camera model coupled with explicit, differentiable defocus rendering guided by the Circle-of-Confusion (CoC). The proposed framework provides for dynamic adjustment of DOF effects by changing the aperture and focal distance of the underlying camera model on-demand. It also enables rendering varying DOF effects of 3D scenes post-optimization, and generating AiF images from defocused training images. Furthermore, we devise a joint optimization strategy to further enhance details in the reconstructed scenes by jointly optimizing rendered defocused and AiF images. Our experimental results indicate that DOF-GS produces high-quality sharp all-in-focus renderings conditioned on inputs compromised by defocus blur, with the training process incurring only a modest increase in GPU memory consumption. We further demonstrate the applications of the proposed method for adjustable defocus rendering and refocusing of the 3D scene from input images degraded by defocus blur.
Spatially Varying Nanophotonic Neural Networks
Aug 07, 2023



The explosive growth of computation and energy cost of artificial intelligence has spurred strong interests in new computing modalities as potential alternatives to conventional electronic processors. Photonic processors that execute operations using photons instead of electrons, have promised to enable optical neural networks with ultra-low latency and power consumption. However, existing optical neural networks, limited by the underlying network designs, have achieved image recognition accuracy much lower than state-of-the-art electronic neural networks. In this work, we close this gap by introducing a large-kernel spatially-varying convolutional neural network learned via low-dimensional reparameterization techniques. We experimentally instantiate the network with a flat meta-optical system that encompasses an array of nanophotonic structures designed to induce angle-dependent responses. Combined with an extremely lightweight electronic backend with approximately 2K parameters we demonstrate a nanophotonic neural network reaches 73.80\% blind test classification accuracy on CIFAR-10 dataset, and, as such, the first time, an optical neural network outperforms the first modern digital neural network -- AlexNet (72.64\%) with 57M parameters, bringing optical neural network into modern deep learning era.