 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Speed Dynamic 3D Imaging with Sensor Fusion Splatting
Feb 07, 2025



Capturing and reconstructing high-speed dynamic 3D scenes has numerous applications in computer graphics, vision, and interdisciplinary fields such as robotics, aerodynamics, and evolutionary biology. However, achieving this using a single imaging modality remains challenging. For instance, traditional RGB cameras suffer from low frame rates, limited exposure times, and narrow baselines. To address this, we propose a novel sensor fusion approach using Gaussian splatting, which combines RGB, depth, and event cameras to capture and reconstruct deforming scenes at high speeds. The key insight of our method lies in leveraging the complementary strengths of these imaging modalities: RGB cameras capture detailed color information, event cameras record rapid scene changes with microsecond resolution, and depth cameras provide 3D scene geometry. To unify the underlying scene representation across these modalities, we represent the scene using deformable 3D Gaussians. To handle rapid scene movements, we jointly optimize the 3D Gaussian parameters and their temporal deformation fields by integrating data from all three sensor modalities. This fusion enables efficient, high-quality imaging of fast and complex scenes, even under challenging conditions such as low light, narrow baselines, or rapid motion. Experiments on synthetic and real datasets captured with our prototype sensor fusion setup demonstrate that our method significantly outperforms state-of-the-art techniques, achieving noticeable improvements in both rendering fidelity and structural accuracy.
Event fields: Capturing light fields at high speed, resolution, and dynamic range
Dec 09, 2024



Event cameras, which feature pixels that independently respond to changes in brightness, are becoming increasingly popular in high-speed applications due to their lower latency, reduced bandwidth requirements, and enhanced dynamic range compared to traditional frame-based cameras. Numerous imaging and vision techniques have leveraged event cameras for high-speed scene understanding by capturing high-framerate, high-dynamic range videos, primarily utilizing the temporal advantages inherent to event cameras. Additionally, imaging and vision techniques have utilized the light field-a complementary dimension to temporal information-for enhanced scene understanding. In this work, we propose "Event Fields", a new approach that utilizes innovative optical designs for event cameras to capture light fields at high speed. We develop the underlying mathematical framework for Event Fields and introduce two foundational frameworks to capture them practically: spatial multiplexing to capture temporal derivatives and temporal multiplexing to capture angular derivatives. To realize these, we design two complementary optical setups one using a kaleidoscope for spatial multiplexing and another using a galvanometer for temporal multiplexing. We evaluate the performance of both designs using a custom-built simulator and real hardware prototypes, showcasing their distinct benefits. Our event fields unlock the full advantages of typical light fields-like post-capture refocusing and depth estimation-now supercharged for high-speed and high-dynamic range scenes. This novel light-sensing paradigm opens doors to new applications in photography, robotics, and AR/VR, and presents fresh challenges in rendering and machine learning.
TVCondNet: A Conditional Denoising Neural Network for NMR Spectroscopy
May 17, 2024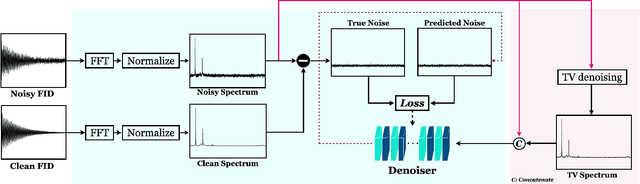
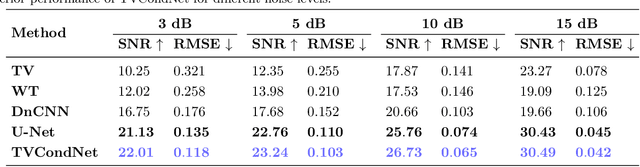
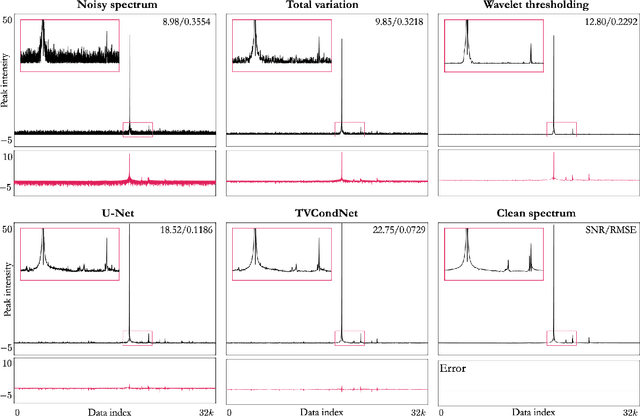
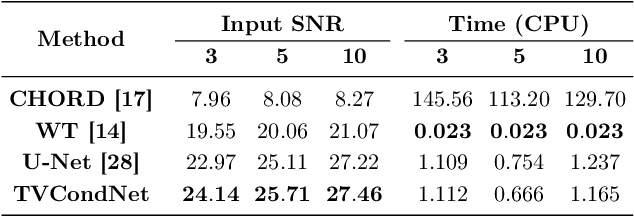
Nuclear Magnetic Resonance (NMR) spectroscopy is a widely-used technique in the fields of bio-medicine, chemistry, and biology for the analysis of chemicals and proteins. The signals from NMR spectroscopy often have low signal-to-noise ratio (SNR) due to acquisition noise, which poses significant challenges for subsequent analysis. Recent work has explored the potential of deep learning (DL) for NMR denoising, showing significant performance gains over traditional methods such as total variation (TV) denoising. This paper shows that the performance of DL denoising for NMR can be further improved by combining data-driven training with traditional TV denoising. The proposed TVCondNet method outperforms both traditional TV and DL methods by including the TV solution as a condition during DL training. Our validation on experimentally collected NMR data shows the superior denoising performance and faster inference speed of TVCondNet compared to existing methods.
FLAIR: A Conditional Diffusion Framework with Applications to Face Video Restoration
Nov 26, 2023



Face video restoration (FVR) is a challenging but important problem where one seeks to recover a perceptually realistic face videos from a low-quality input. While diffusion probabilistic models (DPMs) have been shown to achieve remarkable performance for face image restoration, they often fail to preserve temporally coherent, high-quality videos, compromising the fidelity of reconstructed faces. We present a new conditional diffusion framework called FLAIR for FVR. FLAIR ensures temporal consistency across frames in a computationally efficient fashion by converting a traditional image DPM into a video DPM. The proposed conversion uses a recurrent video refinement layer and a temporal self-attention at different scales. FLAIR also uses a conditional iterative refinement process to balance the perceptual and distortion quality during inference. This process consists of two key components: a data-consistency module that analytically ensures that the generated video precisely matches its degraded observation and a coarse-to-fine image enhancement module specifically for facial regions. Our extensive experiments show superiority of FLAIR over the current state-of-the-art (SOTA) for video super-resolution, deblurring, JPEG restoration, and space-time frame interpolation on two high-quality face video datasets.
A Structured Pruning Algorithm for Model-based Deep Learning
Nov 03, 2023



There is a growing interest in model-based deep learning (MBDL) for solving imaging inverse problems. MBDL networks can be seen as iterative algorithms that estimate the desired image using a physical measurement model and a learned image prior specified using a convolutional neural net (CNNs). The iterative nature of MBDL networks increases the test-time computational complexity, which limits their applicability in certain large-scale applications. We address this issue by presenting structured pruning algorithm for model-based deep learning (SPADE) as the first structured pruning algorithm for MBDL networks. SPADE reduces the computational complexity of CNNs used within MBDL networks by pruning its non-essential weights. We propose three distinct strategies to fine-tune the pruned MBDL networks to minimize the performance loss. Each fine-tuning strategy has a unique benefit that depends on the presence of a pre-trained model and a high-quality ground truth. We validate SPADE on two distinct inverse problems, namely compressed sensing MRI and image super-resolution. Our results highlight that MBDL models pruned by SPADE can achieve substantial speed up in testing time while maintaining competitive performance.
Deep Equilibrium Learning of Explicit Regularizers for Imaging Inverse Problems
Mar 09, 2023



There has been significant recent interest in the use of deep learning for regularizing imaging inverse problems. Most work in the area has focused on regularization imposed implicitly by convolutional neural networks (CNNs) pre-trained for image reconstruction. In this work, we follow an alternative line of work based on learning explicit regularization functionals that promote preferred solutions. We develop the Explicit Learned Deep Equilibrium Regularizer (ELDER) method for learning explicit regularizers that minimize a mean-squared error (MSE) metric. ELDER is based on a regularization functional parameterized by a CNN and a deep equilibrium learning (DEQ) method for training the functional to be MSE-optimal at the fixed points of the reconstruction algorithm. The explicit regularizer enables ELDER to directly inherit fundamental convergence results from optimization theory. On the other hand, DEQ training enables ELDER to improve over existing explicit regularizers without prohibitive memory complexity during training. We use ELDER to train several approaches to parameterizing explicit regularizers and test their performance on three distinct imaging inverse problems. Our results show that ELDER can greatly improve the quality of explicit regularizers compared to existing methods, and show that learning explicit regularizers does not compromise performance relative to methods based on implicit regularization.
Robustness of Deep Equilibrium Architectures to Changes in the Measurement Model
Nov 01, 2022



Deep model-based architectures (DMBAs) are widely used in imaging inverse problems to integrate physical measurement models and learned image priors. Plug-and-play priors (PnP) and deep equilibrium models (DEQ) are two DMBA frameworks that have received significant attention. The key difference between the two is that the image prior in DEQ is trained by using a specific measurement model, while that in PnP is trained as a general image denoiser. This difference is behind a common assumption that PnP is more robust to changes in the measurement models compared to DEQ. This paper investigates the robustness of DEQ priors to changes in the measurement models. Our results on two imaging inverse problems suggest that DEQ priors trained under mismatched measurement models outperform image denoisers.