 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models
Jan 11, 2026Multimodal Large Language Models (MLLMs) have achieved strong performance across many tasks, yet most systems remain limited to offline inference, requiring complete inputs before generating outputs. Recent streaming methods reduce latency by interleaving perception and generation, but still enforce a sequential perception-generation cycle, limiting real-time interaction. In this work, we target a fundamental bottleneck that arises when extending MLLMs to real-time video understanding: the global positional continuity constraint imposed by standard positional encoding schemes. While natural in offline inference, this constraint tightly couples perception and generation, preventing effective input-output parallelism. To address this limitation, we propose a parallel streaming framework that relaxes positional continuity through three designs: Overlapped, Group-Decoupled, and Gap-Isolated. These designs enable simultaneous perception and generation, allowing the model to process incoming inputs while producing responses in real time. Extensive experiments reveal that Group-Decoupled achieves the best efficiency-performance balance, maintaining high fluency and accuracy while significantly reducing latency. We further show that the proposed framework yields up to 2x acceleration under balanced perception-generation workloads, establishing a principled pathway toward speak-while-watching real-time systems. We make all our code publicly available: https://github.com/EIT-NLP/Speak-While-Watching.
RoboVerse: Towards a Unified Platform, Dataset and Benchmark for Scalable and Generalizable Robot Learning
Apr 26, 2025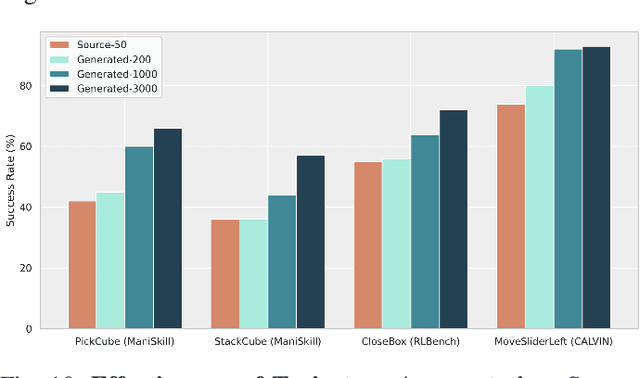



Data scaling and standardized evaluation benchmarks have driven significant advances in natural language processing and computer vision. However, robotics faces unique challenges in scaling data and establishing evaluation protocols. Collecting real-world data is resource-intensive and inefficient, while benchmarking in real-world scenarios remains highly complex. Synthetic data and simulation offer promising alternatives, yet existing efforts often fall short in data quality, diversity, and benchmark standardization. To address these challenges, we introduce RoboVerse, a comprehensive framework comprising a simulation platform, a synthetic dataset, and unified benchmarks. Our simulation platform supports multiple simulators and robotic embodiments, enabling seamless transitions between different environments. The synthetic dataset, featuring high-fidelity physics and photorealistic rendering, is constructed through multiple approaches. Additionally, we propose unified benchmarks for imitation learning and reinforcement learning, enabling evaluation across different levels of generalization. At the core of the simulation platform is MetaSim, an infrastructure that abstracts diverse simulation environments into a universal interface. It restructures existing simulation environments into a simulator-agnostic configuration system, as well as an API aligning different simulator functionalities, such as launching simulation environments, loading assets with initial states, stepping the physics engine, etc. This abstraction ensures interoperability and extensibility. Comprehensive experiments demonstrate that RoboVerse enhances the performance of imitation learning, reinforcement learning, world model learning, and sim-to-real transfer. These results validate the reliability of our dataset and benchmarks, establishing RoboVerse as a robust solution for advancing robot learning.
Frequency-Compensated Network for Daily Arctic Sea Ice Concentration Prediction
Apr 23, 2025Accurately forecasting sea ice concentration (SIC) in the Arctic is critical to global ecosystem health and navigation safety. However, current methods still is confronted with two challenges: 1) these methods rarely explore the long-term feature dependencies in the frequency domain. 2) they can hardly preserve the high-frequency details, and the changes in the marginal area of the sea ice cannot be accurately captured. To this end, we present a Frequency-Compensated Network (FCNet) for Arctic SIC prediction on a daily basis. In particular, we design a dual-branch network, including branches for frequency feature extraction and convolutional feature extraction. For frequency feature extraction, we design an adaptive frequency filter block, which integrates trainable layers with Fourier-based filters. By adding frequency features, the FCNet can achieve refined prediction of edges and details. For convolutional feature extraction, we propose a high-frequency enhancement block to separate high and low-frequency information. Moreover, high-frequency features are enhanced via channel-wise attention, and temporal attention unit is employed for low-frequency feature extraction to capture long-range sea ice changes. Extensive experiments are conducted on a satellite-derived daily SIC dataset, and the results verify the effectiveness of the proposed FCNet. Our codes and data will be made public available at: https://github.com/oucailab/FCNet .
DexGraspNet 2.0: Learning Generative Dexterous Grasping in Large-scale Synthetic Cluttered Scenes
Oct 30, 2024



Grasping in cluttered scenes remains highly challenging for dexterous hands due to the scarcity of data. To address this problem, we present a large-scale synthetic benchmark, encompassing 1319 objects, 8270 scenes, and 427 million grasps. Beyond benchmarking, we also propose a novel two-stage grasping method that learns efficiently from data by using a diffusion model that conditions on local geometry. Our proposed generative method outperforms all baselines in simulation experiments. Furthermore, with the aid of test-time-depth restoration, our method demonstrates zero-shot sim-to-real transfer, attaining 90.7% real-world dexterous grasping success rate in cluttered scenes.
TVCondNet: A Conditional Denoising Neural Network for NMR Spectroscopy
May 17, 2024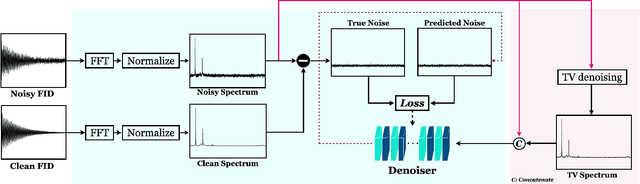
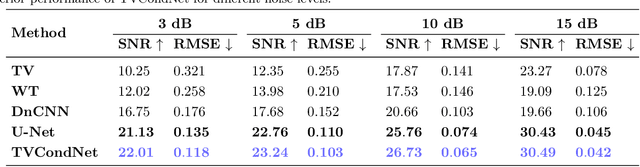
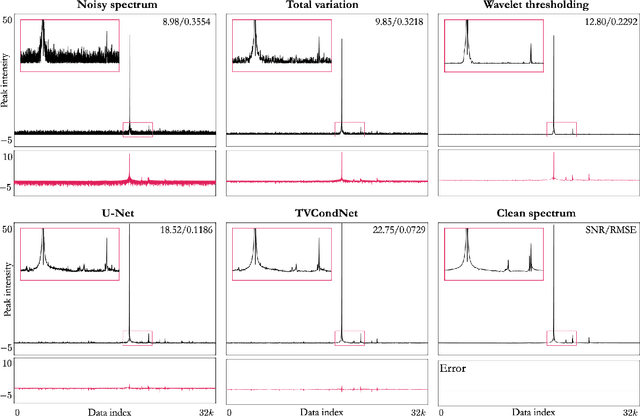
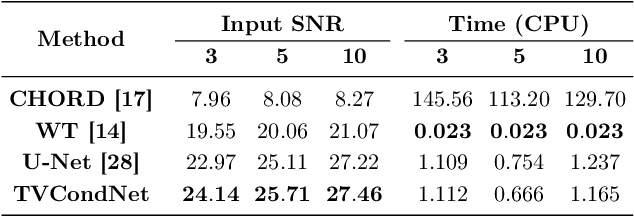
Nuclear Magnetic Resonance (NMR) spectroscopy is a widely-used technique in the fields of bio-medicine, chemistry, and biology for the analysis of chemicals and proteins. The signals from NMR spectroscopy often have low signal-to-noise ratio (SNR) due to acquisition noise, which poses significant challenges for subsequent analysis. Recent work has explored the potential of deep learning (DL) for NMR denoising, showing significant performance gains over traditional methods such as total variation (TV) denoising. This paper shows that the performance of DL denoising for NMR can be further improved by combining data-driven training with traditional TV denoising. The proposed TVCondNet method outperforms both traditional TV and DL methods by including the TV solution as a condition during DL training. Our validation on experimentally collected NMR data shows the superior denoising performance and faster inference speed of TVCondNet compared to existing methods.
PnP Restoration with Domain Adaptation for SANS
Mar 15, 2024Small Angle Neutron Scattering (SANS) is a non-destructive technique utilized to probe the nano- to mesoscale structure of materials by analyzing the scattering pattern of neutrons. Accelerating SANS acquisition for in-situ analysis is essential, but it often reduces the signal-to-noise ratio (SNR), highlighting the need for methods to enhance SNR even with short acquisition times. While deep learning (DL) can be used for enhancing SNR of low quality SANS, the amount of experimental data available for training is usually severely limited. We address this issue by proposing a Plug-and-play Restoration for SANS (PR-SANS) that uses domain-adapted priors. The prior in PR-SANS is initially trained on a set of generic images and subsequently fine-tuned using a limited amount of experimental SANS data. We present a theoretical convergence analysis of PR-SANS by focusing on the error resulting from using inexact domain-adapted priors instead of the ideal ones. We demonstrate with experimentally collected SANS data that PR-SANS can recover high-SNR 2D SANS detector images from low-SNR detector images, effectively increasing the SNR. This advancement enables a reduction in acquisition times by a factor of 12 while maintaining the original signal quality.
Task-Oriented Dexterous Grasp Synthesis via Differentiable Grasp Wrench Boundary Estimator
Sep 24, 2023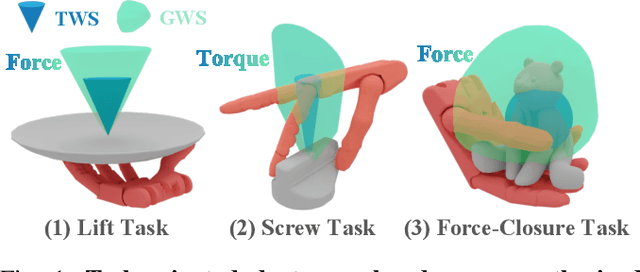
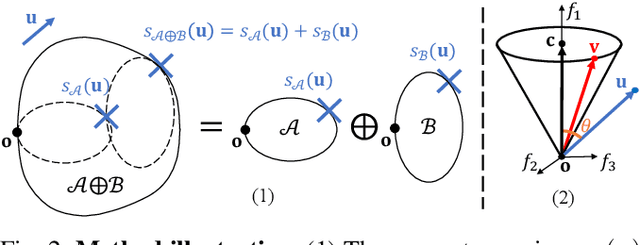
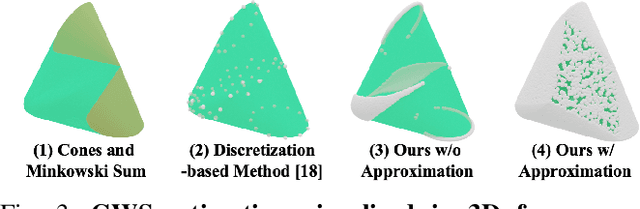
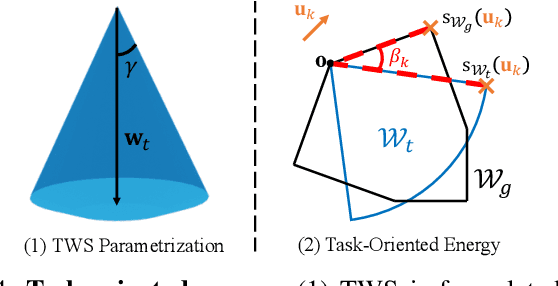
Analytical dexterous grasping synthesis is often driven by grasp quality metrics. However, existing metrics possess many problems, such as being computationally expensive, physically inaccurate, and non-differentiable. Moreover, none of them can facilitate the synthesis of non-force-closure grasps, which account for a significant portion of task-oriented grasping such as lid screwing and button pushing. The main challenge behind all the above drawbacks is the difficulty in modeling the complex Grasp Wrench Space (GWS). In this work, we overcome this challenge by proposing a novel GWS estimator, thus enabling gradient-based task-oriented dexterous grasp synthesis for the first time. Our key contribution is a fast, accurate, and differentiable technique to estimate the GWS boundary with good physical interpretability by parallel sampling and mapping, which does not require iterative optimization. Second, based on our differentiable GWS estimator, we derive a task-oriented energy function to enable gradient-based grasp synthesis and a metric to evaluate non-force-closure grasps. Finally, we improve the previous dexterous grasp synthesis pipeline mainly by a novel technique to make nearest-point calculation differentiable, even on mesh edges and vertices. Extensive experiments are performed to verify the efficiency and effectiveness of our methods. Our GWS estimator can run in several milliseconds on GPUs with minimal memory cost, more than three orders of magnitude faster than the classic discretization-based method. Using this GWS estimator, we synthesize 0.1 million dexterous grasps to show that our pipeline can significantly outperform the SOTA method, even in task-unaware force-closure-grasp synthesis. For task-oriented grasp synthesis, we provide some qualitative results.
UniDexGrasp: Universal Robotic Dexterous Grasping via Learning Diverse Proposal Generation and Goal-Conditioned Policy
Mar 02, 2023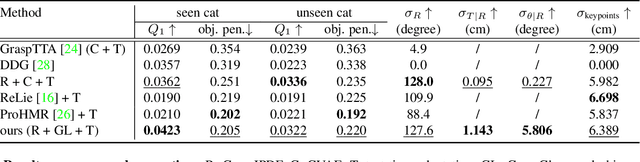
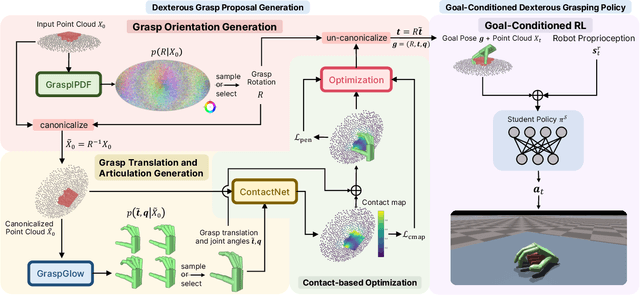
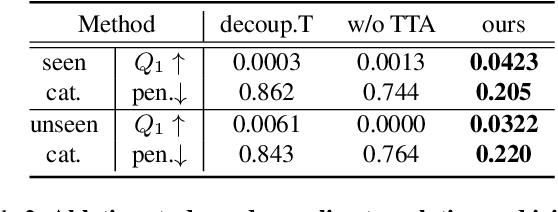
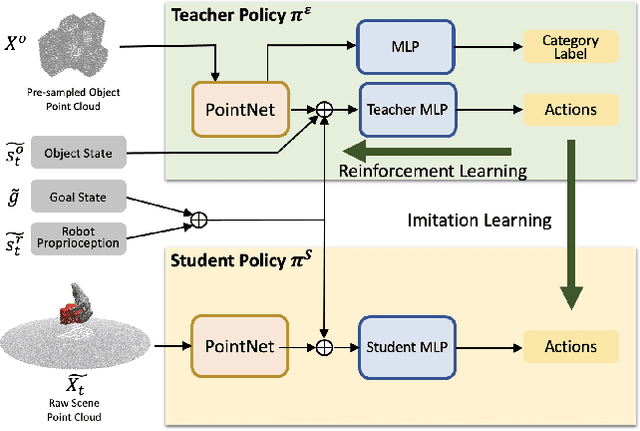
In this work, we tackle the problem of learning universal robotic dexterous grasping from a point cloud observation under a table-top setting. The goal is to grasp and lift up objects in high-quality and diverse ways and generalize across hundreds of categories and even the unseen. Inspired by successful pipelines used in parallel gripper grasping, we split the task into two stages: 1) grasp proposal (pose) generation and 2) goal-conditioned grasp execution. For the first stage, we propose a novel probabilistic model of grasp pose conditioned on the point cloud observation that factorizes rotation from translation and articulation. Trained on our synthesized large-scale dexterous grasp dataset, this model enables us to sample diverse and high-quality dexterous grasp poses for the object in the point cloud. For the second stage, we propose to replace the motion planning used in parallel gripper grasping with a goal-conditioned grasp policy, due to the complexity involved in dexterous grasping execution. Note that it is very challenging to learn this highly generalizable grasp policy that only takes realistic inputs without oracle states. We thus propose several important innovations, including state canonicalization, object curriculum, and teacher-student distillation. Integrating the two stages, our final pipeline becomes the first to achieve universal generalization for dexterous grasping, demonstrating an average success rate of more than 60% on thousands of object instances, which significantly out performs all baselines, meanwhile showing only a minimal generalization gap.
DexGraspNet: A Large-Scale Robotic Dexterous Grasp Dataset for General Objects Based on Simulation
Oct 06, 2022
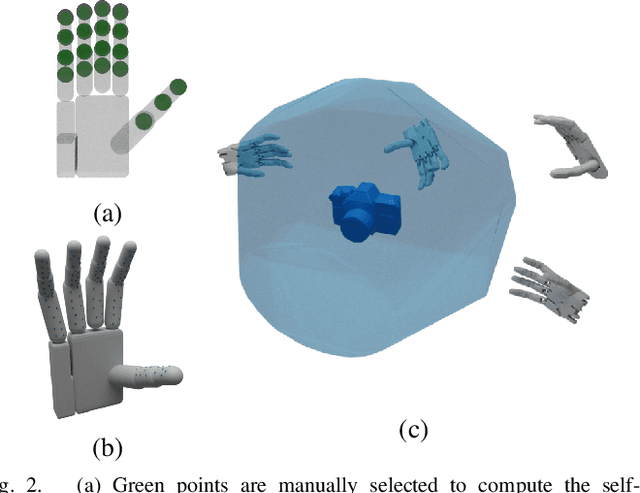
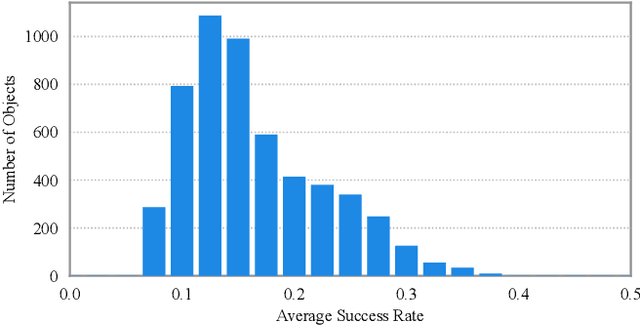

Object grasping using dexterous hands is a crucial yet challenging task for robotic dexterous manipulation. Compared with the field of object grasping with parallel grippers, dexterous grasping is very under-explored, partially owing to the lack of a large-scale dataset. In this work, we present a large-scale simulated dataset, DexGraspNet, for robotic dexterous grasping, along with a highly efficient synthesis method for diverse dexterous grasping synthesis. Leveraging a highly accelerated differentiable force closure estimator, we, for the first time, are able to synthesize stable and diverse grasps efficiently and robustly. We choose ShadowHand, a dexterous gripper commonly seen in robotics, and generated 1.32 million grasps for 5355 objects, covering more than 133 object categories and containing more than 200 diverse grasps for each object instance, with all grasps having been validated by the physics simulator. Compared to the previous dataset generated by GraspIt!, our dataset has not only more objects and grasps, but also higher diversity and quality. Via performing cross-dataset experiments, we show that training several algorithms of dexterous grasp synthesis on our datasets significantly outperforms training on the previous one, demonstrating the large scale and diversity of DexGraspNet. We will release the data and tools upon acceptance.
End-to-end Weakly-supervised Multiple 3D Hand Mesh Reconstruction from Single Image
Apr 18, 2022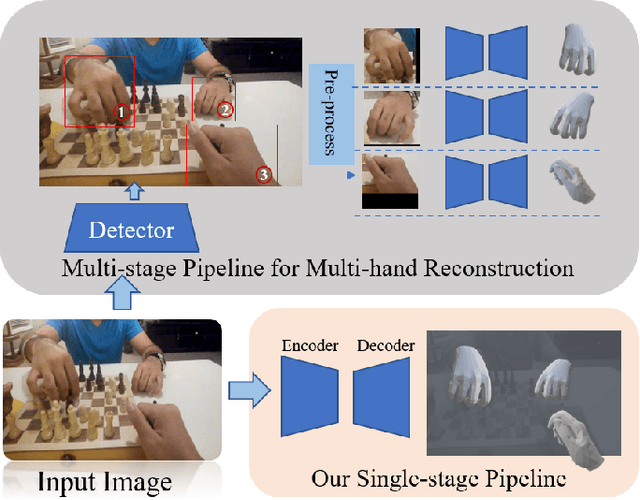


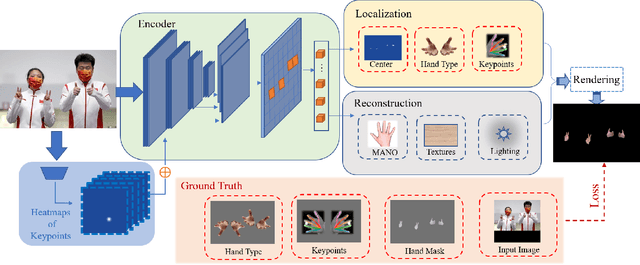
In this paper, we consider the challenging task of simultaneously locating and recovering multiple hands from single 2D image. Previous studies either focus on single hand reconstruction or solve this problem in a multi-stage way. Moreover, the conventional two-stage pipeline firstly detects hand areas, and then estimates 3D hand pose from each cropped patch. To reduce the computational redundancy in preprocessing and feature extraction, we propose a concise but efficient single-stage pipeline. Specifically, we design a multi-head auto-encoder structure for multi-hand reconstruction, where each head network shares the same feature map and outputs the hand center, pose and texture, respectively. Besides, we adopt a weakly-supervised scheme to alleviate the burden of expensive 3D real-world data annotations. To this end, we propose a series of losses optimized by a stage-wise training scheme, where a multi-hand dataset with 2D annotations is generated based on the publicly available single hand datasets. In order to further improve the accuracy of the weakly supervised model, we adopt several feature consistency constraints in both single and multiple hand settings. Specifically, the keypoints of each hand estimated from local features should be consistent with the re-projected points predicted from global features. Extensive experiments on public benchmarks including FreiHAND, HO3D, InterHand2.6M and RHD demonstrate that our method outperforms the state-of-the-art model-based methods in both weakly-supervised and fully-supervised manners.