 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Preserved Point-based Human Avatar
Nov 20, 2023To enable realistic experience in AR/VR and digital entertainment, we present the first point-based human avatar model that embodies the entirety expressive range of digital humans. We employ two MLPs to model pose-dependent deformation and linear skinning (LBS) weights. The representation of appearance relies on a decoder and the features that attached to each point. In contrast to alternative implicit approaches, the oriented points representation not only provides a more intuitive way to model human avatar animation but also significantly reduces both training and inference time. Moreover, we propose a novel method to transfer semantic information from the SMPL-X model to the points, which enables to better understand human body movements. By leveraging the semantic information of points, we can facilitate virtual try-on and human avatar composition through exchanging the points of same category across different subjects. Experimental results demonstrate the efficacy of our presented method.
FastMESH: Fast Surface Reconstruction by Hexagonal Mesh-based Neural Rendering
May 29, 2023Despite the promising results of multi-view reconstruction, the recent neural rendering-based methods, such as implicit surface rendering (IDR) and volume rendering (NeuS), not only incur a heavy computational burden on training but also have the difficulties in disentangling the geometric and appearance. Although having achieved faster training speed than implicit representation and hash coding, the explicit voxel-based method obtains the inferior results on recovering surface. To address these challenges, we propose an effective mesh-based neural rendering approach, named FastMESH, which only samples at the intersection of ray and mesh. A coarse-to-fine scheme is introduced to efficiently extract the initial mesh by space carving. More importantly, we suggest a hexagonal mesh model to preserve surface regularity by constraining the second-order derivatives of vertices, where only low level of positional encoding is engaged for neural rendering. The experiments demonstrate that our approach achieves the state-of-the-art results on both reconstruction and novel view synthesis. Besides, we obtain 10-fold acceleration on training comparing to the implicit representation-based methods.
Multi-View Stereo Representation Revisit: Region-Aware MVSNet
Apr 27, 2023



Deep learning-based multi-view stereo has emerged as a powerful paradigm for reconstructing the complete geometrically-detailed objects from multi-views. Most of the existing approaches only estimate the pixel-wise depth value by minimizing the gap between the predicted point and the intersection of ray and surface, which usually ignore the surface topology. It is essential to the textureless regions and surface boundary that cannot be properly reconstructed. To address this issue, we suggest to take advantage of point-to-surface distance so that the model is able to perceive a wider range of surfaces. To this end, we predict the distance volume from cost volume to estimate the signed distance of points around the surface. Our proposed RA-MVSNet is patch-awared, since the perception range is enhanced by associating hypothetical planes with a patch of surface. Therefore, it could increase the completion of textureless regions and reduce the outliers at the boundary. Moreover, the mesh topologies with fine details can be generated by the introduced distance volume. Comparing to the conventional deep learning-based multi-view stereo methods, our proposed RA-MVSNet approach obtains more complete reconstruction results by taking advantage of signed distance supervision. The experiments on both the DTU and Tanks \& Temples datasets demonstrate that our proposed approach achieves the state-of-the-art results.
PatchShading: High-Quality Human Reconstruction by Patch Warping and Shading Refinement
Nov 26, 2022Human reconstruction from multi-view images plays an important role in many applications. Although neural rendering methods have achieved promising results on synthesising realistic images, it is still difficult to handle the ambiguity between the geometry and appearance using only rendering loss. Moreover, it is very computationally intensive to render a whole image as each pixel requires a forward network inference. To tackle these challenges, we propose a novel approach called \emph{PatchShading} to reconstruct high-quality mesh of human body from multi-view posed images. We first present a patch warping strategy to constrain multi-view photometric consistency explicitly. Second, we adopt sphere harmonics (SH) illumination and shape from shading image formation to further refine the geometric details. By taking advantage of the oriented point clouds shape representation and SH shading, our proposed method significantly reduce the optimization and rendering time compared to those implicit methods. The encouraging results on both synthetic and real-world datasets demonstrate the efficacy of our proposed approach.
Efficient Textured Mesh Recovery from Multiple Views with Differentiable Rendering
May 25, 2022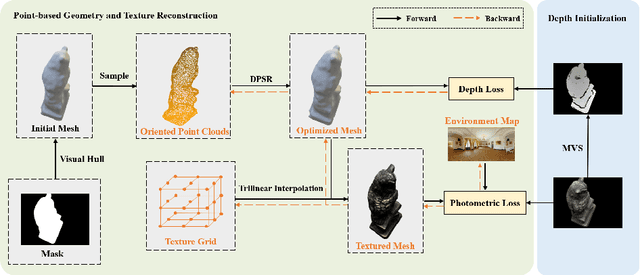
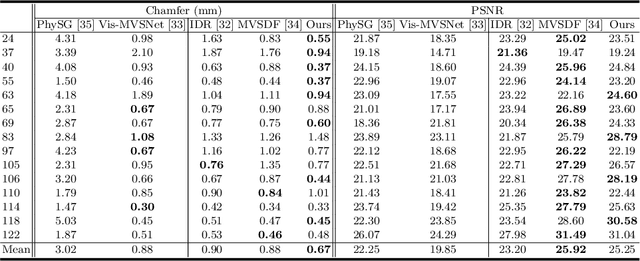


Despite of the promising results on shape and color recovery using self-supervision, the multi-layer perceptrons-based methods usually costs hours to train the deep neural network due to the implicit surface representation. Moreover, it is quite computational intensive to render a single image, since a forward network inference is required for each pixel. To tackle these challenges, in this paper, we propose an efficient coarse-to-fine approach to recover the textured mesh from multi-view images. Specifically, we take advantage of a differentiable Poisson Solver to represent the shape, which is able to produce topology-agnostic and watertight surfaces. To account for the depth information, we optimize the shape geometry by minimizing the difference between the rendered mesh with the depth predicted by the learning-based multi-view stereo algorithm. In contrast to the implicit neural representation on shape and color, we introduce a physically based inverse rendering scheme to jointly estimate the lighting and reflectance of the objects, which is able to render the high resolution image at real-time. Additionally, we fine-tune the extracted mesh by inverse rendering to obtain the mesh with fine details and high fidelity image. We have conducted the extensive experiments on several multi-view stereo datasets, whose promising results demonstrate the efficacy of our proposed approach. We will make our full implementation publicly available.
Bridge the Gap Between Model-based and Model-free Human Reconstruction
Jun 11, 2021

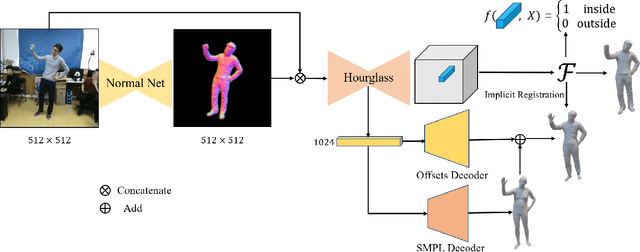

It is challenging to directly estimate the geometry of human from a single image due to the high diversity and complexity of body shapes with the various clothing styles. Most of model-based approaches are limited to predict the shape and pose of a minimally clothed body with over-smoothing surface. Although capturing the fine detailed geometries, the model-free methods are lack of the fixed mesh topology. To address these issues, we propose a novel topology-preserved human reconstruction approach by bridging the gap between model-based and model-free human reconstruction. We present an end-to-end neural network that simultaneously predicts the pixel-aligned implicit surface and the explicit mesh model built by graph convolutional neural network. Moreover, an extra graph convolutional neural network is employed to estimate the vertex offsets between the implicit surface and parametric mesh model. Finally, we suggest an efficient implicit registration method to refine the neural network output in implicit space. Experiments on DeepHuman dataset showed that our approach is effective.
Weakly-Supervised Multi-Face 3D Reconstruction
Jan 06, 2021


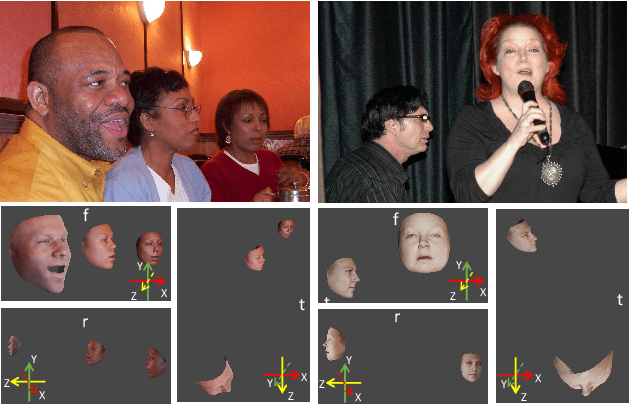
3D face reconstruction plays a very important role in many real-world multimedia applications, including digital entertainment, social media, affection analysis, and person identification. The de-facto pipeline for estimating the parametric face model from an image requires to firstly detect the facial regions with landmarks, and then crop each face to feed the deep learning-based regressor. Comparing to the conventional methods performing forward inference for each detected instance independently, we suggest an effective end-to-end framework for multi-face 3D reconstruction, which is able to predict the model parameters of multiple instances simultaneously using single network inference. Our proposed approach not only greatly reduces the computational redundancy in feature extraction but also makes the deployment procedure much easier using the single network model. More importantly, we employ the same global camera model for the reconstructed faces in each image, which makes it possible to recover the relative head positions and orientations in the 3D scene. We have conducted extensive experiments to evaluate our proposed approach on the sparse and dense face alignment tasks. The experimental results indicate that our proposed approach is very promising on face alignment tasks without fully-supervision and pre-processing like detection and crop. Our implementation is publicly available at \url{https://github.com/kalyo-zjl/WM3DR}.
CSID: Center, Scale, Identity and Density-aware Pedestrian Detection in a Crowd
Oct 21, 2019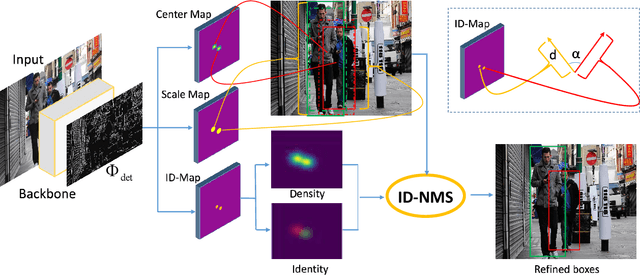


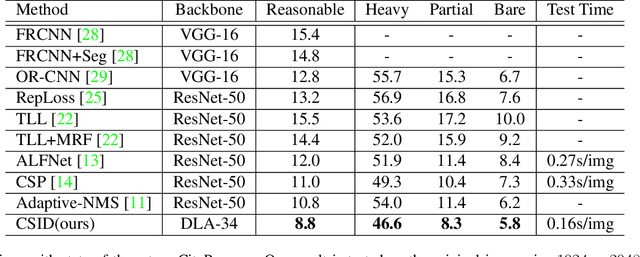
Pedestrian detection in a crowd is very challenging due to vastly different scales and poor conditions. Pedestrian detectors are generally designed by extending generic object detectors, where Non-maximum suppression (NMS) is a standard but critical post-processing step for refining detection results. In this paper, we propose CSID: a Center, Scale, Identity-and-Density-aware pedestrian detector with a novel Identity-and-Density-aware NMS (ID-NMS) algorithm to refine the results of anchor-free pedestrian detection. Our main contributions in this work include (i) a novel Identity and Density Map (ID-Map) which converts each positive instance into a feature vector to encode both identity and density information simultaneously, (ii) a modified optimization target in defining ID-loss and addressing the extremely class imbalance issue during training, and (iii) a novel ID-NMS algorithm by considering both identity and density information of each predicted box provided by ID-Map to effectively refine the detection results. We evaluate the proposed CSID pedestrian detector using the novel ID-NMS technique and achieve new state-of-the-art results on two benchmark data sets (CityPersons and CrowdHuman) for pedestrian detection.