 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Scalar Rewards by Internalizing Reasoning into Score Distributions
Jun 08, 2026Reward models are central to text-to-image post-training, but visual preference is subjective and better represented as a distribution over rubric scores than as a deterministic scalar. Existing scalar, score-token, and pairwise reward models over-compress uncertainty and fine-grained score differences, while reasoning-based generative rewards provide stronger judgments but are costly to deploy and difficult to use as direct optimization signals. We propose Z-Reward, a teacher-student reward modeling framework that decouples reasoning-heavy judgment from efficient reward deployment. The teacher is a large VLM that uses reasoning to infer rubric-aligned score distributions, and is trained with Group-wise Direct Score Optimization (GDSO), which combines policy-gradient rewards from distribution expectations with direct pointwise and pairwise supervision on score distributions and score gaps. The student is trained with Reasoning-Internalized Score Distillation (RISD), which transfers the teacher's reasoning-conditioned score distribution into a compact VLM without requiring explicit reasoning chains at inference time. On our internally annotated evaluation set, the 27B GDSO teacher reaches 89.6% human preference accuracy, outperforming SFT, RewardDance, and GRPO, while the 9B RISD student reaches 88.6%, outperforming the OPD baseline and closely matching the larger teacher. We further show that Z-Reward can serve as a differentiable reward signal for text-to-image optimization, yielding a 41.3% net human-preference improvement over the SFT baseline.
Forging Spatial Intelligence: A Roadmap of Multi-Modal Data Pre-Training for Autonomous Systems
Dec 30, 2025The rapid advancement of autonomous systems, including self-driving vehicles and drones, has intensified the need to forge true Spatial Intelligence from multi-modal onboard sensor data. While foundation models excel in single-modal contexts, integrating their capabilities across diverse sensors like cameras and LiDAR to create a unified understanding remains a formidable challenge. This paper presents a comprehensive framework for multi-modal pre-training, identifying the core set of techniques driving progress toward this goal. We dissect the interplay between foundational sensor characteristics and learning strategies, evaluating the role of platform-specific datasets in enabling these advancements. Our central contribution is the formulation of a unified taxonomy for pre-training paradigms: ranging from single-modality baselines to sophisticated unified frameworks that learn holistic representations for advanced tasks like 3D object detection and semantic occupancy prediction. Furthermore, we investigate the integration of textual inputs and occupancy representations to facilitate open-world perception and planning. Finally, we identify critical bottlenecks, such as computational efficiency and model scalability, and propose a roadmap toward general-purpose multi-modal foundation models capable of achieving robust Spatial Intelligence for real-world deployment.
What Are We Measuring When We Evaluate Large Vision-Language Models? An Analysis of Latent Factors and Biases
Apr 03, 2024Vision-language (VL) models, pretrained on colossal image-text datasets, have attained broad VL competence that is difficult to evaluate. A common belief is that a small number of VL skills underlie the variety of VL tests. In this paper, we perform a large-scale transfer learning experiment aimed at discovering latent VL skills from data. We reveal interesting characteristics that have important implications for test suite design. First, generation tasks suffer from a length bias, suggesting benchmarks should balance tasks with varying output lengths. Second, we demonstrate that factor analysis successfully identifies reasonable yet surprising VL skill factors, suggesting benchmarks could leverage similar analyses for task selection. Finally, we present a new dataset, OLIVE (https://github.com/jq-zh/olive-dataset), which simulates user instructions in the wild and presents challenges dissimilar to all datasets we tested. Our findings contribute to the design of balanced and broad-coverage vision-language evaluation methods.
Few-Shot Learning on Graphs: from Meta-learning to Pre-training and Prompting
Feb 02, 2024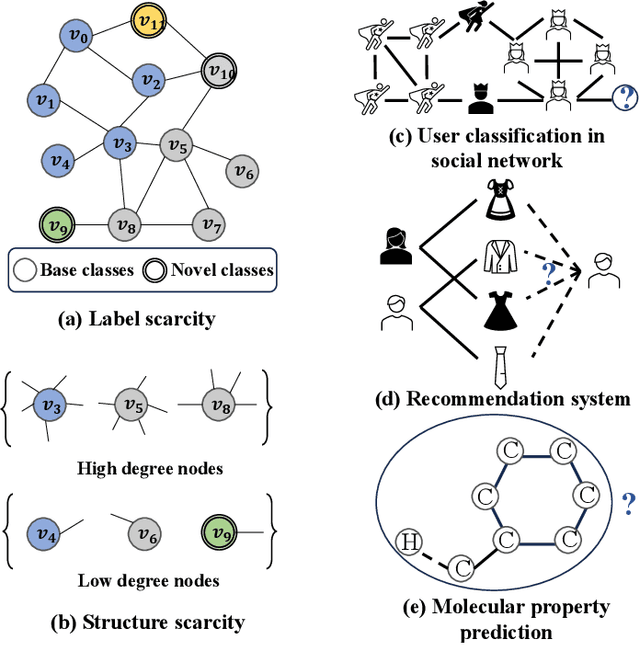
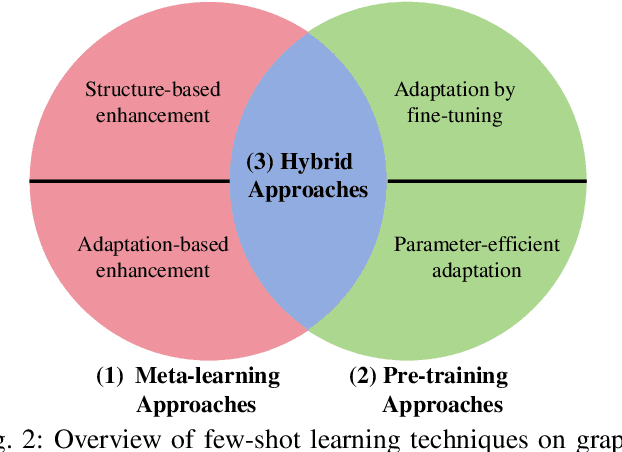
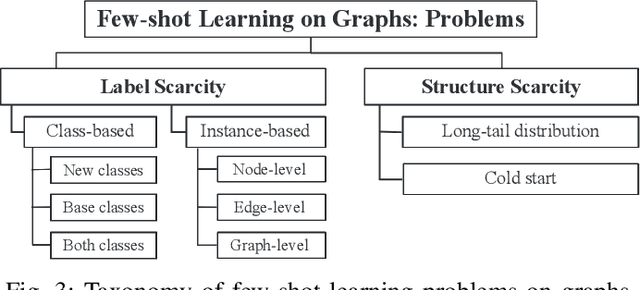
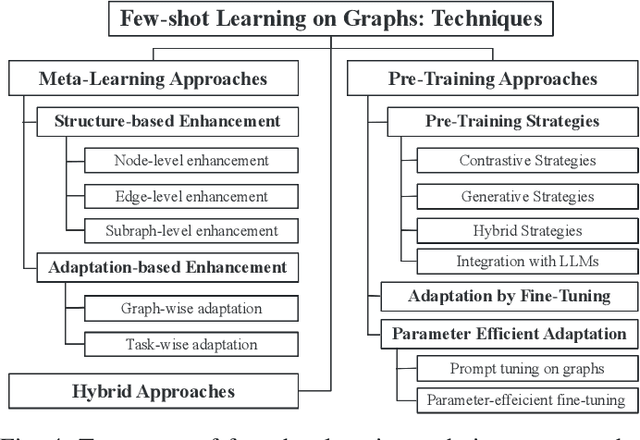
Graph representation learning, a critical step in graph-centric tasks, has seen significant advancements. Earlier techniques often operate in an end-to-end setting, where performance heavily relies on the availability of ample labeled data. This constraint has spurred the emergence of few-shot learning on graphs, where only a few task-specific labels are available for each task. Given the extensive literature in this field, this survey endeavors to synthesize recent developments, provide comparative insights, and identify future directions. We systematically categorize existing studies into three major families: meta-learning approaches, pre-training approaches, and hybrid approaches, with a finer-grained classification in each family to aid readers in their method selection process. Within each category, we analyze the relationships among these methods and compare their strengths and limitations. Finally, we outline prospective future directions for few-shot learning on graphs to catalyze continued innovation in this field.
RAP-Gen: Retrieval-Augmented Patch Generation with CodeT5 for Automatic Program Repair
Sep 12, 2023



Automatic program repair (APR) is crucial to reduce manual debugging efforts for developers and improve software reliability. While conventional search-based techniques typically rely on heuristic rules or a redundancy assumption to mine fix patterns, recent years have witnessed the surge of deep learning (DL) based approaches to automate the program repair process in a data-driven manner. However, their performance is often limited by a fixed set of parameters to model the highly complex search space of APR. To ease such burden on the parametric models, in this work, we propose a novel Retrieval-Augmented Patch Generation framework (RAP-Gen) by explicitly leveraging relevant fix patterns retrieved from a codebase of previous bug-fix pairs. Specifically, we build a hybrid patch retriever to account for both lexical and semantic matching based on the raw source code in a language-agnostic manner, which does not rely on any code-specific features. In addition, we adapt a code-aware language model CodeT5 as our foundation model to facilitate both patch retrieval and generation tasks in a unified manner. We adopt a stage-wise approach where the patch retriever first retrieves a relevant external bug-fix pair to augment the buggy input for the CodeT5 patch generator, which synthesizes a ranked list of repair patch candidates. Notably, RAP-Gen is a generic APR framework that can flexibly integrate different patch retrievers and generators to repair various types of bugs. We thoroughly evaluate RAP-Gen on three benchmarks in two programming languages, including the TFix benchmark in JavaScript, and Code Refinement and Defects4J benchmarks in Java, where the bug localization information may or may not be provided. Experimental results show that RAP-Gen significantly outperforms previous state-of-the-art approaches on all benchmarks, e.g., repairing 15 more bugs on 818 Defects4J bugs.
PyRCA: A Library for Metric-based Root Cause Analysis
Jun 20, 2023We introduce PyRCA, an open-source Python machine learning library of Root Cause Analysis (RCA) for Artificial Intelligence for IT Operations (AIOps). It provides a holistic framework to uncover the complicated metric causal dependencies and automatically locate root causes of incidents. It offers a unified interface for multiple commonly used RCA models, encompassing both graph construction and scoring tasks. This library aims to provide IT operations staff, data scientists, and researchers a one-step solution to rapid model development, model evaluation and deployment to online applications. In particular, our library includes various causal discovery methods to support causal graph construction, and multiple types of root cause scoring methods inspired by Bayesian analysis, graph analysis and causal analysis, etc. Our GUI dashboard offers practitioners an intuitive point-and-click interface, empowering them to easily inject expert knowledge through human interaction. With the ability to visualize causal graphs and the root cause of incidents, practitioners can quickly gain insights and improve their workflow efficiency. This technical report introduces PyRCA's architecture and major functionalities, while also presenting benchmark performance numbers in comparison to various baseline models. Additionally, we demonstrate PyRCA's capabilities through several example use cases.
OTW: Optimal Transport Warping for Time Series
Jun 01, 2023
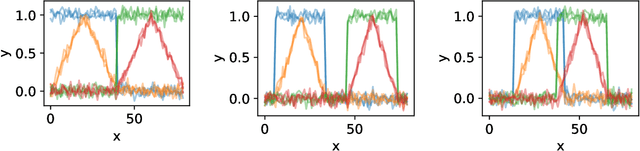
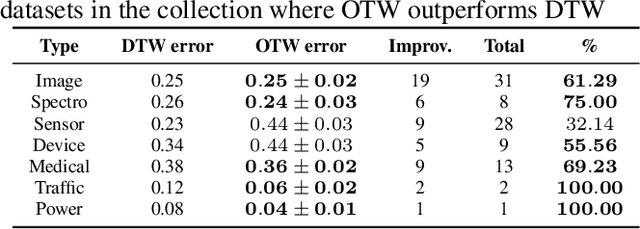
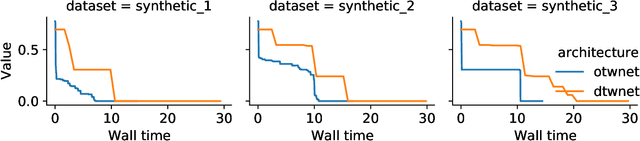
Dynamic Time Warping (DTW) has become the pragmatic choice for measuring distance between time series. However, it suffers from unavoidable quadratic time complexity when the optimal alignment matrix needs to be computed exactly. This hinders its use in deep learning architectures, where layers involving DTW computations cause severe bottlenecks. To alleviate these issues, we introduce a new metric for time series data based on the Optimal Transport (OT) framework, called Optimal Transport Warping (OTW). OTW enjoys linear time/space complexity, is differentiable and can be parallelized. OTW enjoys a moderate sensitivity to time and shape distortions, making it ideal for time series. We show the efficacy and efficiency of OTW on 1-Nearest Neighbor Classification and Hierarchical Clustering, as well as in the case of using OTW instead of DTW in Deep Learning architectures.
CodeTF: One-stop Transformer Library for State-of-the-art Code LLM
May 31, 2023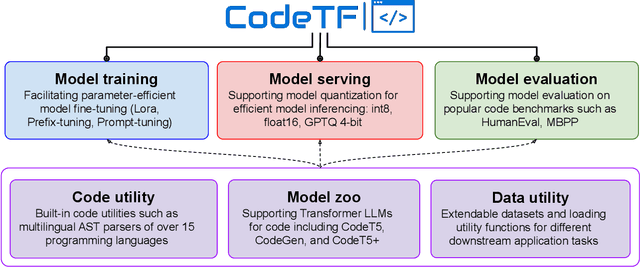

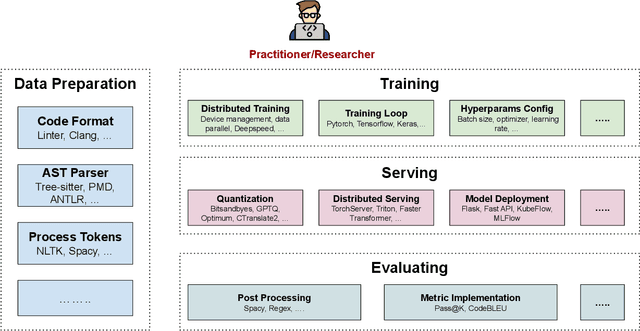
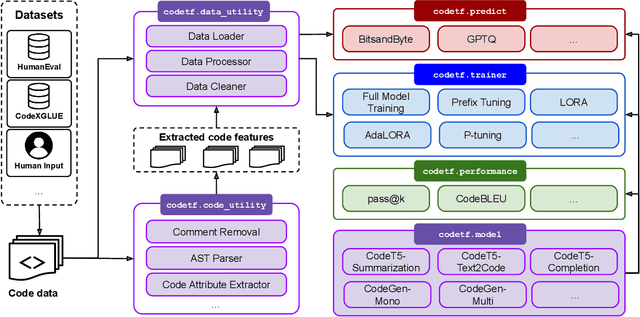
Code intelligence plays a key role in transforming modern software engineering. Recently, deep learning-based models, especially Transformer-based large language models (LLMs), have demonstrated remarkable potential in tackling these tasks by leveraging massive open-source code data and programming language features. However, the development and deployment of such models often require expertise in both machine learning and software engineering, creating a barrier for the model adoption. In this paper, we present CodeTF, an open-source Transformer-based library for state-of-the-art Code LLMs and code intelligence. Following the principles of modular design and extensible framework, we design CodeTF with a unified interface to enable rapid access and development across different types of models, datasets and tasks. Our library supports a collection of pretrained Code LLM models and popular code benchmarks, including a standardized interface to train and serve code LLMs efficiently, and data features such as language-specific parsers and utility functions for extracting code attributes. In this paper, we describe the design principles, the architecture, key modules and components, and compare with other related library tools. Finally, we hope CodeTF is able to bridge the gap between machine learning/generative AI and software engineering, providing a comprehensive open-source solution for developers, researchers, and practitioners.
BLIP-Diffusion: Pre-trained Subject Representation for Controllable Text-to-Image Generation and Editing
May 24, 2023Subject-driven text-to-image generation models create novel renditions of an input subject based on text prompts. Existing models suffer from lengthy fine-tuning and difficulties preserving the subject fidelity. To overcome these limitations, we introduce BLIP-Diffusion, a new subject-driven image generation model that supports multimodal control which consumes inputs of subject images and text prompts. Unlike other subject-driven generation models, BLIP-Diffusion introduces a new multimodal encoder which is pre-trained to provide subject representation. We first pre-train the multimodal encoder following BLIP-2 to produce visual representation aligned with the text. Then we design a subject representation learning task which enables a diffusion model to leverage such visual representation and generates new subject renditions. Compared with previous methods such as DreamBooth, our model enables zero-shot subject-driven generation, and efficient fine-tuning for customized subject with up to 20x speedup. We also demonstrate that BLIP-Diffusion can be flexibly combined with existing techniques such as ControlNet and prompt-to-prompt to enable novel subject-driven generation and editing applications. Code and models will be released at https://github.com/salesforce/LAVIS/tree/main/projects/blip-diffusion. Project page at https://dxli94.github.io/BLIP-Diffusion-website/.
CodeT5+: Open Code Large Language Models for Code Understanding and Generation
May 20, 2023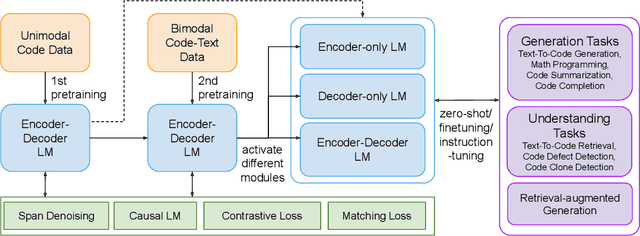
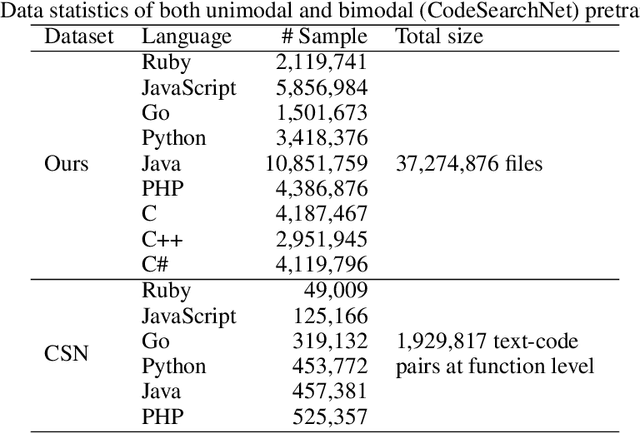
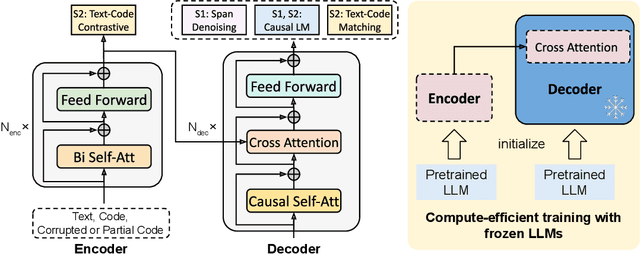
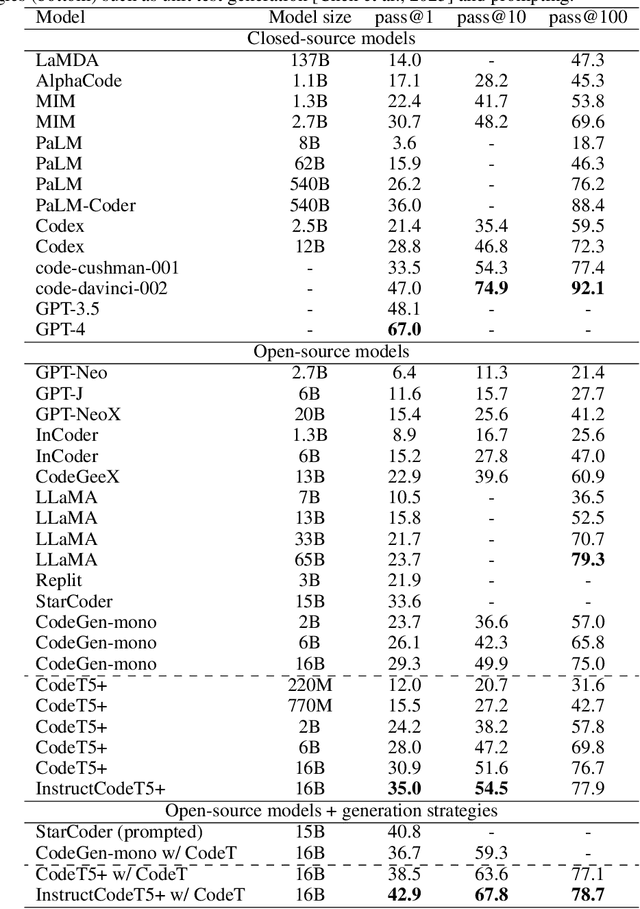
Large language models (LLMs) pretrained on vast source code have achieved prominent progress in code intelligence. However, existing code LLMs have two main limitations in terms of architecture and pretraining tasks. First, they often adopt a specific architecture (encoder-only or decoder-only) or rely on a unified encoder-decoder network for different downstream tasks. The former paradigm is limited by inflexibility in applications while in the latter, the model is treated as a single system for all tasks, leading to suboptimal performance on a subset of tasks. Secondly, they often employ a limited set of pretraining objectives which might not be relevant to some downstream tasks and hence result in substantial performance degrade. To address these limitations, we propose ``CodeT5+'', a family of encoder-decoder LLMs for code in which component modules can be flexibly combined to suit a wide range of downstream code tasks. Such flexibility is enabled by our proposed mixture of pretraining objectives to mitigate the pretrain-finetune discrepancy. These objectives cover span denoising, contrastive learning, text-code matching, and causal LM pretraining tasks, on both unimodal and bimodal multilingual code corpora. Furthermore, we propose to initialize CodeT5+ with frozen off-the-shelf LLMs without training from scratch to efficiently scale up our models, and explore instruction-tuning to align with natural language instructions. We extensively evaluate CodeT5+ on over 20 code-related benchmarks in different settings, including zero-shot, finetuning, and instruction-tuning. We observe state-of-the-art (SoTA) model performance on various code-related tasks, such as code generation and completion, math programming, and text-to-code retrieval tasks. Particularly, our instruction-tuned CodeT5+ 16B achieves new SoTA results on HumanEval code generation task against other open code LLMs.