 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Are We Measuring When We Evaluate Large Vision-Language Models? An Analysis of Latent Factors and Biases
Apr 03, 2024Vision-language (VL) models, pretrained on colossal image-text datasets, have attained broad VL competence that is difficult to evaluate. A common belief is that a small number of VL skills underlie the variety of VL tests. In this paper, we perform a large-scale transfer learning experiment aimed at discovering latent VL skills from data. We reveal interesting characteristics that have important implications for test suite design. First, generation tasks suffer from a length bias, suggesting benchmarks should balance tasks with varying output lengths. Second, we demonstrate that factor analysis successfully identifies reasonable yet surprising VL skill factors, suggesting benchmarks could leverage similar analyses for task selection. Finally, we present a new dataset, OLIVE (https://github.com/jq-zh/olive-dataset), which simulates user instructions in the wild and presents challenges dissimilar to all datasets we tested. Our findings contribute to the design of balanced and broad-coverage vision-language evaluation methods.
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning
May 11, 2023



General-purpose language models that can solve various language-domain tasks have emerged driven by the pre-training and instruction-tuning pipeline. However, building general-purpose vision-language models is challenging due to the increased task discrepancy introduced by the additional visual input. Although vision-language pre-training has been widely studied, vision-language instruction tuning remains relatively less explored. In this paper, we conduct a systematic and comprehensive study on vision-language instruction tuning based on the pre-trained BLIP-2 models. We gather a wide variety of 26 publicly available datasets, transform them into instruction tuning format and categorize them into two clusters for held-in instruction tuning and held-out zero-shot evaluation. Additionally, we introduce instruction-aware visual feature extraction, a crucial method that enables the model to extract informative features tailored to the given instruction. The resulting InstructBLIP models achieve state-of-the-art zero-shot performance across all 13 held-out datasets, substantially outperforming BLIP-2 and the larger Flamingo. Our models also lead to state-of-the-art performance when finetuned on individual downstream tasks (e.g., 90.7% accuracy on ScienceQA IMG). Furthermore, we qualitatively demonstrate the advantages of InstructBLIP over concurrent multimodal models. All InstructBLIP models have been open-sourced at https://github.com/salesforce/LAVIS/tree/main/projects/instructblip.
From Images to Textual Prompts: Zero-shot VQA with Frozen Large Language Models
Dec 21, 2022Large language models (LLMs) have demonstrated excellent zero-shot generalization to new language tasks. However, effective utilization of LLMs for zero-shot visual question-answering (VQA) remains challenging, primarily due to the modality disconnection and task disconnection between LLM and VQA task. End-to-end training on vision and language data may bridge the disconnections, but is inflexible and computationally expensive. To address this issue, we propose \emph{Img2Prompt}, a plug-and-play module that provides the prompts that can bridge the aforementioned modality and task disconnections, so that LLMs can perform zero-shot VQA tasks without end-to-end training. In order to provide such prompts, we further employ LLM-agnostic models to provide prompts that can describe image content and self-constructed question-answer pairs, which can effectively guide LLM to perform zero-shot VQA tasks. Img2Prompt offers the following benefits: 1) It can flexibly work with various LLMs to perform VQA. 2)~Without the needing of end-to-end training, it significantly reduces the cost of deploying LLM for zero-shot VQA tasks. 3) It achieves comparable or better performance than methods relying on end-to-end training. For example, we outperform Flamingo~\cite{Deepmind:Flamingo2022} by 5.6\% on VQAv2. On the challenging A-OKVQA dataset, our method even outperforms few-shot methods by as much as 20\%.
Plug-and-Play VQA: Zero-shot VQA by Conjoining Large Pretrained Models with Zero Training
Oct 17, 2022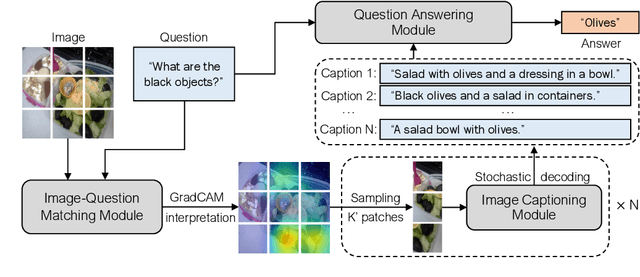
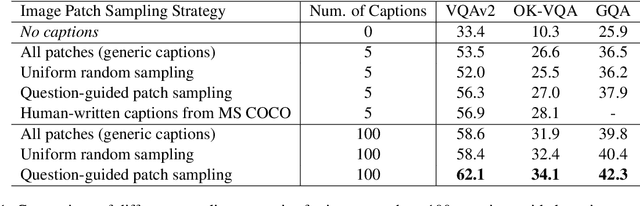

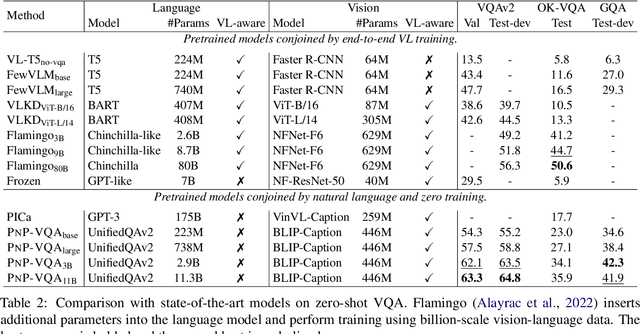
Visual question answering (VQA) is a hallmark of vision and language reasoning and a challenging task under the zero-shot setting. We propose Plug-and-Play VQA (PNP-VQA), a modular framework for zero-shot VQA. In contrast to most existing works, which require substantial adaptation of pretrained language models (PLMs) for the vision modality, PNP-VQA requires no additional training of the PLMs. Instead, we propose to use natural language and network interpretation as an intermediate representation that glues pretrained models together. We first generate question-guided informative image captions, and pass the captions to a PLM as context for question answering. Surpassing end-to-end trained baselines, PNP-VQA achieves state-of-the-art results on zero-shot VQAv2 and GQA. With 11B parameters, it outperforms the 80B-parameter Flamingo model by 8.5% on VQAv2. With 738M PLM parameters, PNP-VQA achieves an improvement of 9.1% on GQA over FewVLM with 740M PLM parameters. Code is released at https://github.com/salesforce/LAVIS/tree/main/projects/pnp-vqa
Improving Tail-Class Representation with Centroid Contrastive Learning
Oct 19, 2021

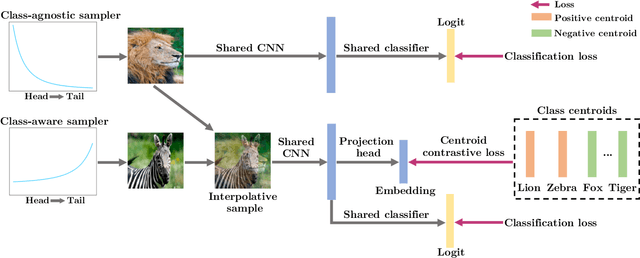
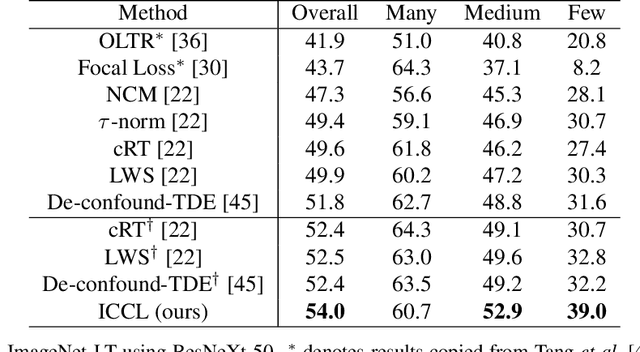
In vision domain, large-scale natural datasets typically exhibit long-tailed distribution which has large class imbalance between head and tail classes. This distribution poses difficulty in learning good representations for tail classes. Recent developments have shown good long-tailed model can be learnt by decoupling the training into representation learning and classifier balancing. However, these works pay insufficient consideration on the long-tailed effect on representation learning. In this work, we propose interpolative centroid contrastive learning (ICCL) to improve long-tailed representation learning. ICCL interpolates two images from a class-agnostic sampler and a class-aware sampler, and trains the model such that the representation of the interpolative image can be used to retrieve the centroids for both source classes. We demonstrate the effectiveness of our approach on multiple long-tailed image classification benchmarks. Our result shows a significant accuracy gain of 2.8% on the iNaturalist 2018 dataset with a real-world long-tailed distribution.
Performance evaluation of a foot-controlled human-robot interface
Mar 08, 2019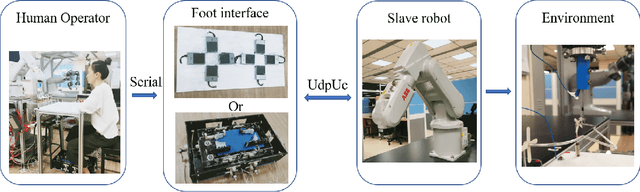
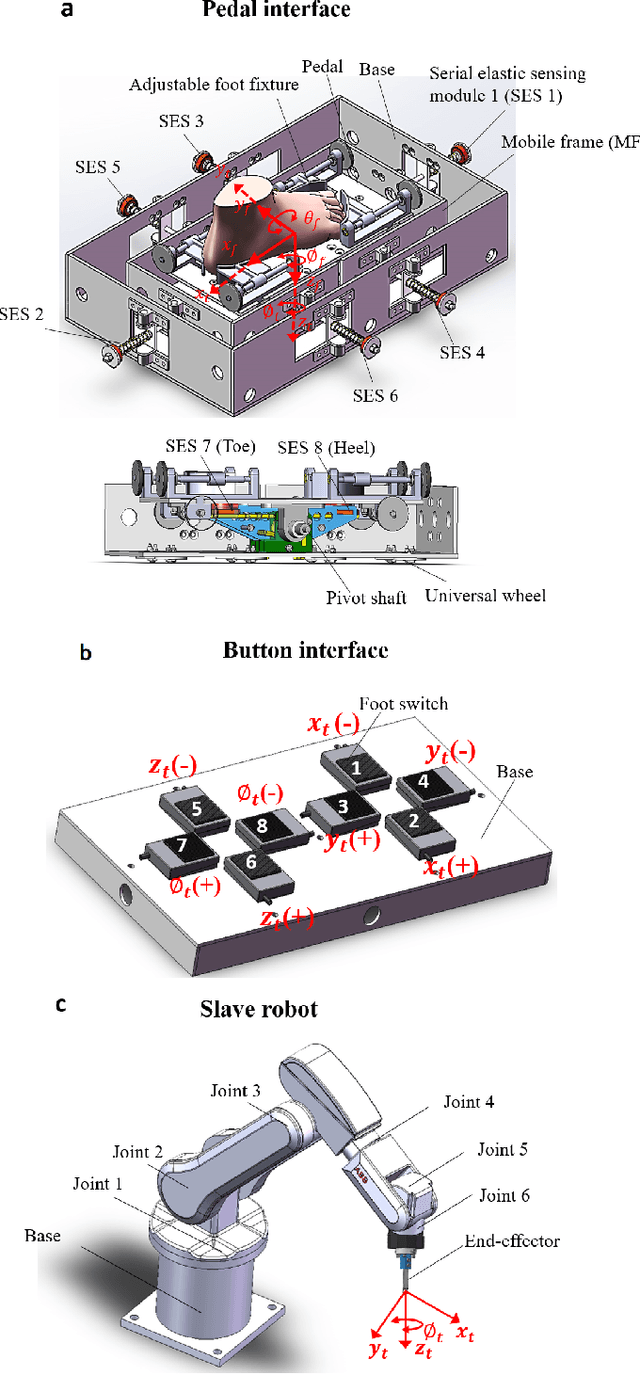
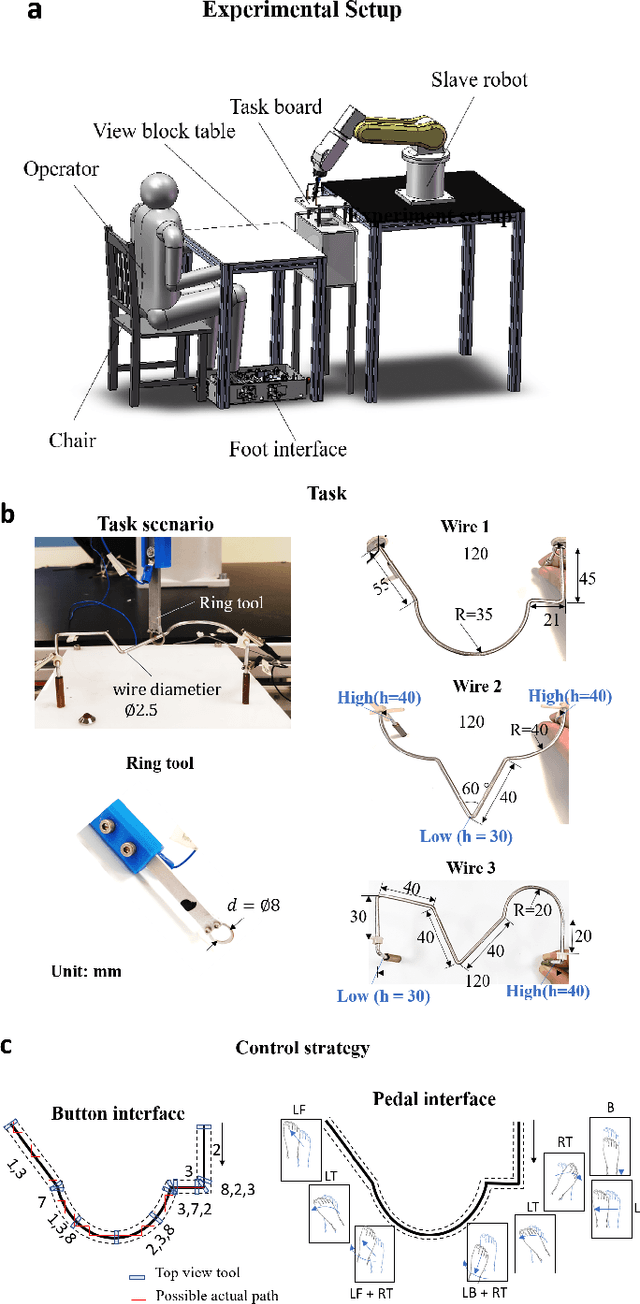
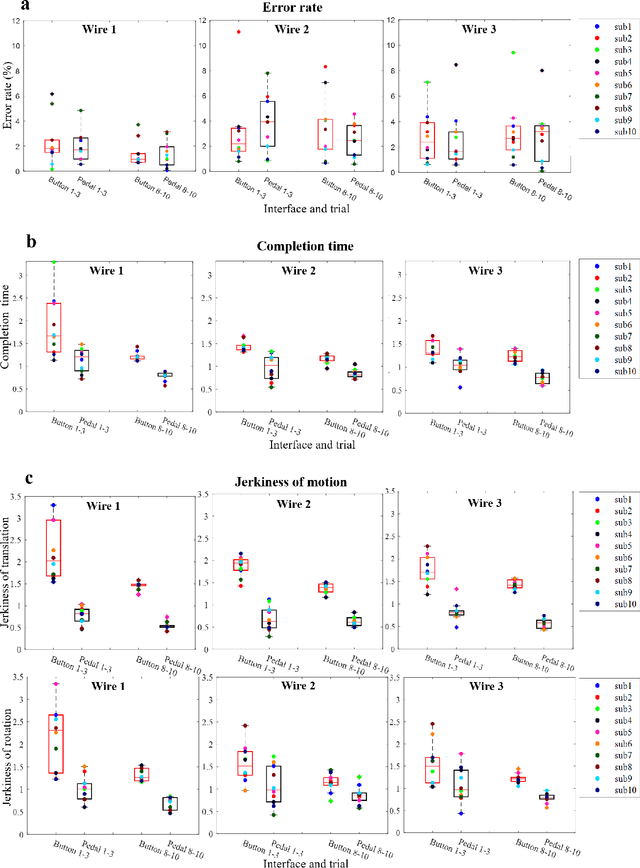
Robotic minimally invasive interventions typically require using more than two instruments. We thus developed a foot pedal interface which allows the user to control a robotic arm (simultaneously to working with the hands) with four degrees of freedom in continuous directions and speeds. This paper evaluates and compares the performances of ten naive operators in using this new pedal interface and a traditional button interface in completing tasks. These tasks are geometrically complex path-following tasks similar to those in laparoscopic training, and the traditional button interface allows axis-by-axis control with constant speeds. Precision, time, and smoothness of the subjects' control movements for these tasks are analysed. The results demonstrate that the pedal interface can be used to control a robot for complex motion tasks. The subjects kept the average error rate at a low level of around 2.6% with both interfaces, but the pedal interface resulted in about 30% faster operation speed and 60% smoother movement, which indicates improved efficiency and user experience as compared with the button interface. The results of a questionnaire show that the operators found that controlling the robot with the pedal interface was more intuitive, comfortable, and less tiring than using the button interface.
A Subject-Specific Four-Degree-of-Freedom Foot Interface to Control a Robot Arm
Feb 13, 2019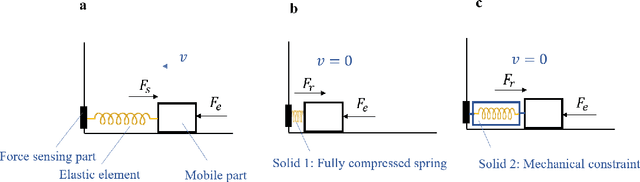
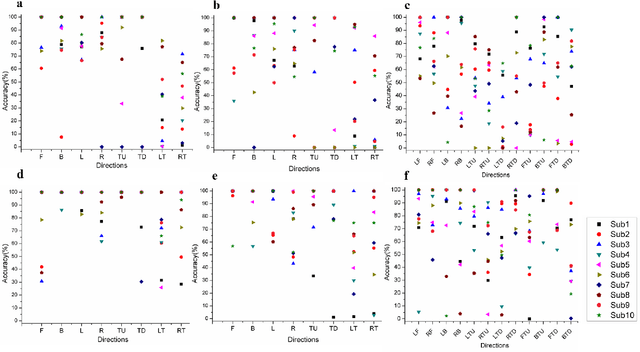
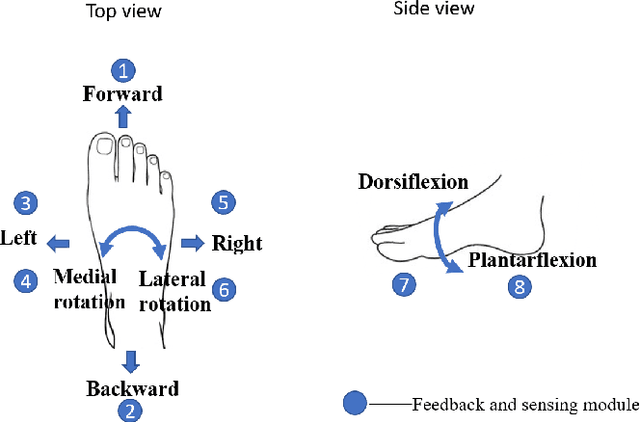
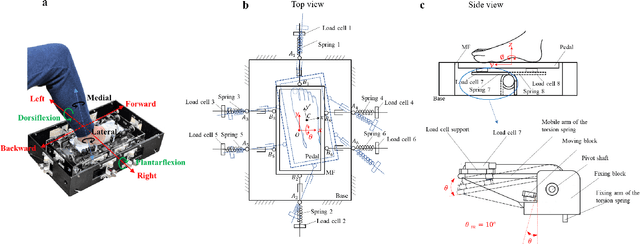
In robotic surgery, the surgeon controls robotic instruments using dedicated interfaces. One critical limitation of current interfaces is that they are designed to be operated by only the hands. This means that the surgeon can only control at most two robotic instruments at one time while many interventions require three instruments. This paper introduces a novel four-degree-of-freedom foot-machine interface which allows the surgeon to control a third robotic instrument using the foot, giving the surgeon a "third hand". This interface is essentially a parallel-serial hybrid mechanism with springs and force sensors. Unlike existing switch-based interfaces that can only un-intuitively generate motion in discrete directions, this interface allows intuitive control of a slave robotic arm in continuous directions and speeds, naturally matching the foot movements with dynamic force & position feedbacks. An experiment with ten naive subjects was conducted to test the system. In view of the significant variance of motion patterns between subjects, a subject-specific mapping from foot movements to command outputs was developed using Independent Component Analysis (ICA). Results showed that the ICA method could accurately identify subjects' foot motion patterns and significantly improve the prediction accuracy of motion directions from 68% to 88% as compared with the forward kinematics-based approach. This foot-machine interface can be applied for the teleoperation of industrial/surgical robots independently or in coordination with hands in the future.