 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Learning (BL): Learning Hierarchical Optimization Structures from Data
Feb 23, 2026Inspired by behavioral science, we propose Behavior Learning (BL), a novel general-purpose machine learning framework that learns interpretable and identifiable optimization structures from data, ranging from single optimization problems to hierarchical compositions. It unifies predictive performance, intrinsic interpretability, and identifiability, with broad applicability to scientific domains involving optimization. BL parameterizes a compositional utility function built from intrinsically interpretable modular blocks, which induces a data distribution for prediction and generation. Each block represents and can be written in symbolic form as a utility maximization problem (UMP), a foundational paradigm in behavioral science and a universal framework of optimization. BL supports architectures ranging from a single UMP to hierarchical compositions, the latter modeling hierarchical optimization structures. Its smooth and monotone variant (IBL) guarantees identifiability. Theoretically, we establish the universal approximation property of BL, and analyze the M-estimation properties of IBL. Empirically, BL demonstrates strong predictive performance, intrinsic interpretability and scalability to high-dimensional data. Code: https://github.com/MoonYLiang/Behavior-Learning ; install via pip install blnetwork.
MANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
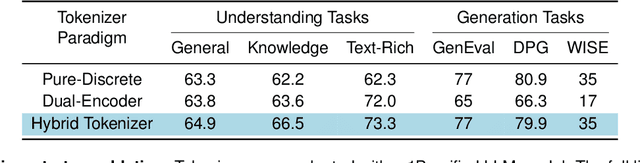
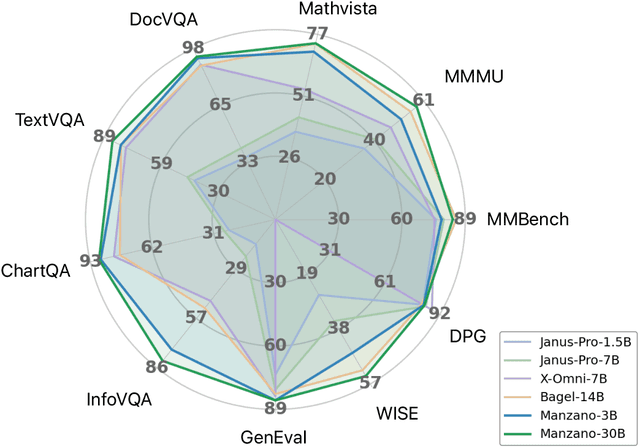
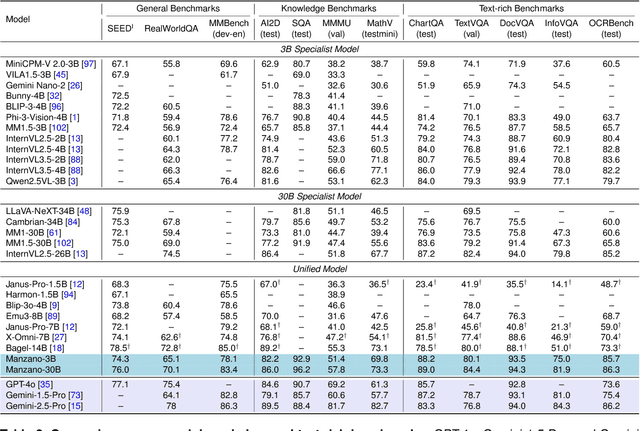
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
Adaptive Source-Channel Coding for Semantic Communications
Aug 11, 2025Semantic communications (SemComs) have emerged as a promising paradigm for joint data and task-oriented transmissions, combining the demands for both the bit-accurate delivery and end-to-end (E2E) distortion minimization. However, current joint source-channel coding (JSCC) in SemComs is not compatible with the existing communication systems and cannot adapt to the variations of the sources or the channels, while separate source-channel coding (SSCC) is suboptimal in the finite blocklength regime. To address these issues, we propose an adaptive source-channel coding (ASCC) scheme for SemComs over parallel Gaussian channels, where the deep neural network (DNN)-based semantic source coding and conventional digital channel coding are separately deployed and adaptively designed. To enable efficient adaptation between the source and channel coding, we first approximate the E2E data and semantic distortions as functions of source coding rate and bit error ratio (BER) via logistic regression, where BER is further modeled as functions of signal-to-noise ratio (SNR) and channel coding rate. Then, we formulate the weighted sum E2E distortion minimization problem for joint source-channel coding rate and power allocation over parallel channels, which is solved by the successive convex approximation. Finally, simulation results demonstrate that the proposed ASCC scheme outperforms typical deep JSCC and SSCC schemes for both the single- and parallel-channel scenarios while maintaining full compatibility with practical digital systems.
Towards Reliable Forgetting: A Survey on Machine Unlearning Verification, Challenges, and Future Directions
Jun 18, 2025With growing demands for privacy protection, security, and legal compliance (e.g., GDPR), machine unlearning has emerged as a critical technique for ensuring the controllability and regulatory alignment of machine learning models. However, a fundamental challenge in this field lies in effectively verifying whether unlearning operations have been successfully and thoroughly executed. Despite a growing body of work on unlearning techniques, verification methodologies remain comparatively underexplored and often fragmented. Existing approaches lack a unified taxonomy and a systematic framework for evaluation. To bridge this gap, this paper presents the first structured survey of machine unlearning verification methods. We propose a taxonomy that organizes current techniques into two principal categories -- behavioral verification and parametric verification -- based on the type of evidence used to assess unlearning fidelity. We examine representative methods within each category, analyze their underlying assumptions, strengths, and limitations, and identify potential vulnerabilities in practical deployment. In closing, we articulate a set of open problems in current verification research, aiming to provide a foundation for developing more robust, efficient, and theoretically grounded unlearning verification mechanisms.
ProBench: Judging Multimodal Foundation Models on Open-ended Multi-domain Expert Tasks
Mar 10, 2025Solving expert-level multimodal tasks is a key milestone towards general intelligence. As the capabilities of multimodal large language models (MLLMs) continue to improve, evaluation of such advanced multimodal intelligence becomes necessary yet challenging. In this work, we introduce ProBench, a benchmark of open-ended user queries that require professional expertise and advanced reasoning. ProBench consists of 4,000 high-quality samples independently submitted by professionals based on their daily productivity demands. It spans across 10 fields and 56 sub-fields, including science, arts, humanities, coding, mathematics, and creative writing. Experimentally, we evaluate and compare 24 latest models using MLLM-as-a-Judge. Our results reveal that although the best open-source models rival the proprietary ones, ProBench presents significant challenges in visual perception, textual understanding, domain knowledge and advanced reasoning, thus providing valuable directions for future multimodal AI research efforts.
Aria-UI: Visual Grounding for GUI Instructions
Dec 20, 2024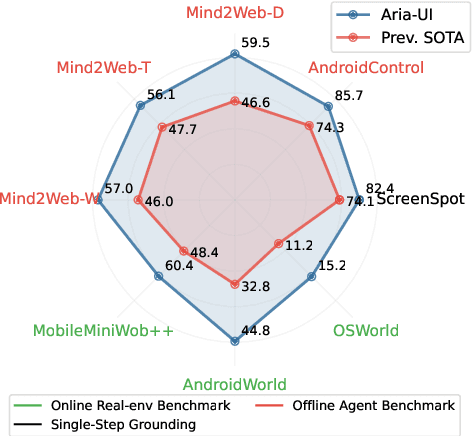


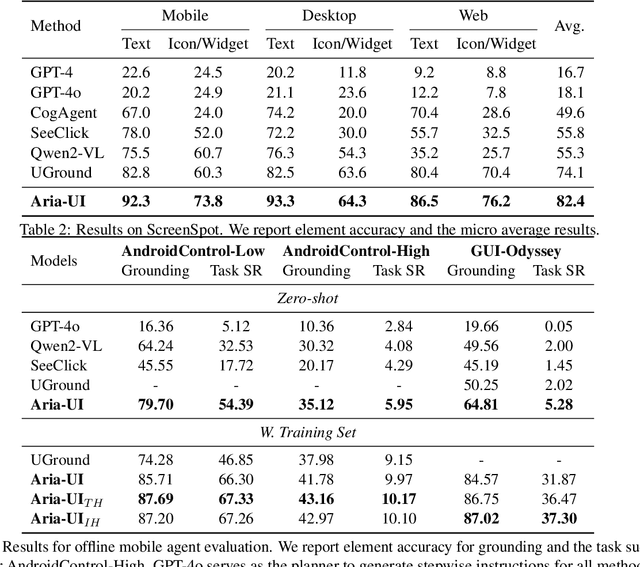
Digital agents for automating tasks across different platforms by directly manipulating the GUIs are increasingly important. For these agents, grounding from language instructions to target elements remains a significant challenge due to reliance on HTML or AXTree inputs. In this paper, we introduce Aria-UI, a large multimodal model specifically designed for GUI grounding. Aria-UI adopts a pure-vision approach, eschewing reliance on auxiliary inputs. To adapt to heterogeneous planning instructions, we propose a scalable data pipeline that synthesizes diverse and high-quality instruction samples for grounding. To handle dynamic contexts in task performing, Aria-UI incorporates textual and text-image interleaved action histories, enabling robust context-aware reasoning for grounding. Aria-UI sets new state-of-the-art results across offline and online agent benchmarks, outperforming both vision-only and AXTree-reliant baselines. We release all training data and model checkpoints to foster further research at https://ariaui.github.io.
VideoAutoArena: An Automated Arena for Evaluating Large Multimodal Models in Video Analysis through User Simulation
Nov 20, 2024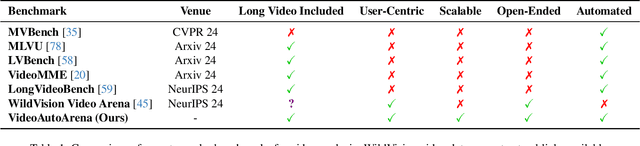

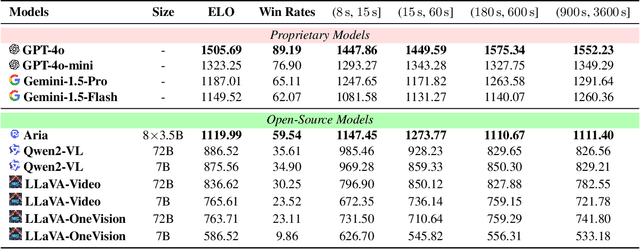
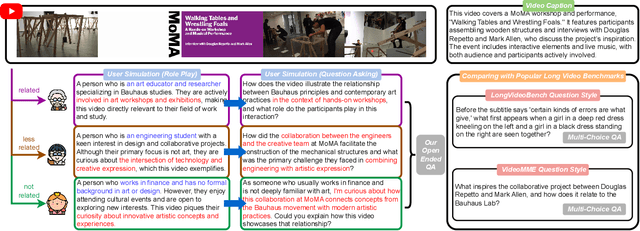
Large multimodal models (LMMs) with advanced video analysis capabilities have recently garnered significant attention. However, most evaluations rely on traditional methods like multiple-choice questions in benchmarks such as VideoMME and LongVideoBench, which are prone to lack the depth needed to capture the complex demands of real-world users. To address this limitation-and due to the prohibitive cost and slow pace of human annotation for video tasks-we introduce VideoAutoArena, an arena-style benchmark inspired by LMSYS Chatbot Arena's framework, designed to automatically assess LMMs' video analysis abilities. VideoAutoArena utilizes user simulation to generate open-ended, adaptive questions that rigorously assess model performance in video understanding. The benchmark features an automated, scalable evaluation framework, incorporating a modified ELO Rating System for fair and continuous comparisons across multiple LMMs. To validate our automated judging system, we construct a 'gold standard' using a carefully curated subset of human annotations, demonstrating that our arena strongly aligns with human judgment while maintaining scalability. Additionally, we introduce a fault-driven evolution strategy, progressively increasing question complexity to push models toward handling more challenging video analysis scenarios. Experimental results demonstrate that VideoAutoArena effectively differentiates among state-of-the-art LMMs, providing insights into model strengths and areas for improvement. To further streamline our evaluation, we introduce VideoAutoBench as an auxiliary benchmark, where human annotators label winners in a subset of VideoAutoArena battles. We use GPT-4o as a judge to compare responses against these human-validated answers. Together, VideoAutoArena and VideoAutoBench offer a cost-effective, and scalable framework for evaluating LMMs in user-centric video analysis.
Aria: An Open Multimodal Native Mixture-of-Experts Model
Oct 08, 2024
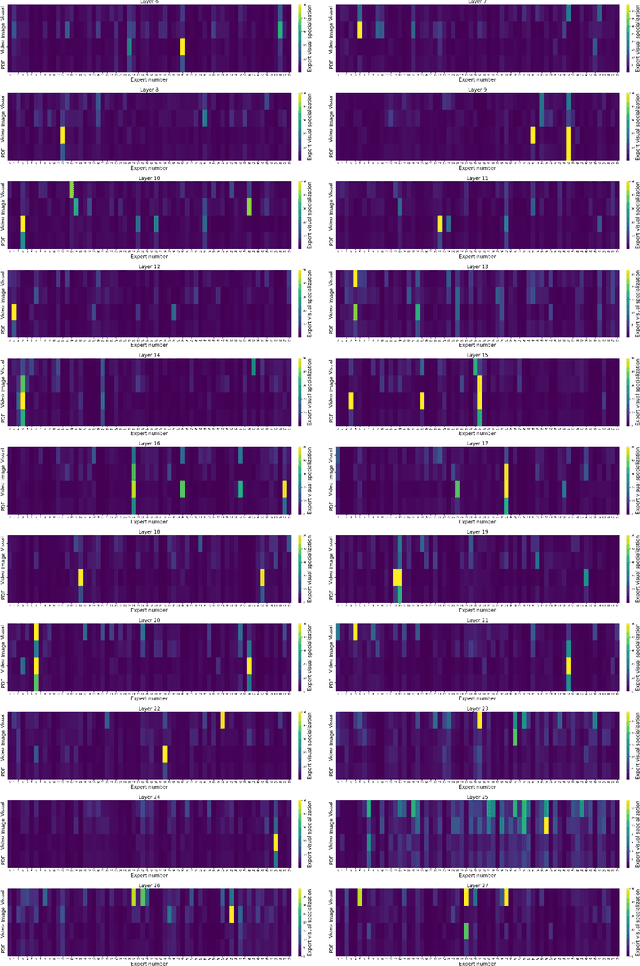


Information comes in diverse modalities. Multimodal native AI models are essential to integrate real-world information and deliver comprehensive understanding. While proprietary multimodal native models exist, their lack of openness imposes obstacles for adoptions, let alone adaptations. To fill this gap, we introduce Aria, an open multimodal native model with best-in-class performance across a wide range of multimodal, language, and coding tasks. Aria is a mixture-of-expert model with 3.9B and 3.5B activated parameters per visual token and text token, respectively. It outperforms Pixtral-12B and Llama3.2-11B, and is competitive against the best proprietary models on various multimodal tasks. We pre-train Aria from scratch following a 4-stage pipeline, which progressively equips the model with strong capabilities in language understanding, multimodal understanding, long context window, and instruction following. We open-source the model weights along with a codebase that facilitates easy adoptions and adaptations of Aria in real-world applications.
EZSR: Event-based Zero-Shot Recognition
Jul 31, 2024



This paper studies zero-shot object recognition using event camera data. Guided by CLIP, which is pre-trained on RGB images, existing approaches achieve zero-shot object recognition by maximizing embedding similarities between event data encoded by an event encoder and RGB images encoded by the CLIP image encoder. Alternatively, several methods learn RGB frame reconstructions from event data for the CLIP image encoder. However, these approaches often result in suboptimal zero-shot performance. This study develops an event encoder without relying on additional reconstruction networks. We theoretically analyze the performance bottlenecks of previous approaches: global similarity-based objective (i.e., maximizing the embedding similarities) cause semantic misalignments between the learned event embedding space and the CLIP text embedding space due to the degree of freedom. To mitigate the issue, we explore a scalar-wise regularization strategy. Furthermore, to scale up the number of events and RGB data pairs for training, we also propose a pipeline for synthesizing event data from static RGB images. Experimentally, our data synthesis strategy exhibits an attractive scaling property, and our method achieves superior zero-shot object recognition performance on extensive standard benchmark datasets, even compared with past supervised learning approaches. For example, we achieve 47.84% zero-shot accuracy on the N-ImageNet dataset.
LongVideoBench: A Benchmark for Long-context Interleaved Video-Language Understanding
Jul 22, 2024



Large multimodal models (LMMs) are processing increasingly longer and richer inputs. Albeit the progress, few public benchmark is available to measure such development. To mitigate this gap, we introduce LongVideoBench, a question-answering benchmark that features video-language interleaved inputs up to an hour long. Our benchmark includes 3,763 varying-length web-collected videos with their subtitles across diverse themes, designed to comprehensively evaluate LMMs on long-term multimodal understanding. To achieve this, we interpret the primary challenge as to accurately retrieve and reason over detailed multimodal information from long inputs. As such, we formulate a novel video question-answering task termed referring reasoning. Specifically, as part of the question, it contains a referring query that references related video contexts, called referred context. The model is then required to reason over relevant video details from the referred context. Following the paradigm of referring reasoning, we curate 6,678 human-annotated multiple-choice questions in 17 fine-grained categories, establishing one of the most comprehensive benchmarks for long-form video understanding. Evaluations suggest that the LongVideoBench presents significant challenges even for the most advanced proprietary models (e.g. GPT-4o, Gemini-1.5-Pro, GPT-4-Turbo), while their open-source counterparts show an even larger performance gap. In addition, our results indicate that model performance on the benchmark improves only when they are capable of processing more frames, positioning LongVideoBench as a valuable benchmark for evaluating future-generation long-context LMMs.