 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMANZANO: A Simple and Scalable Unified Multimodal Model with a Hybrid Vision Tokenizer
Sep 19, 2025
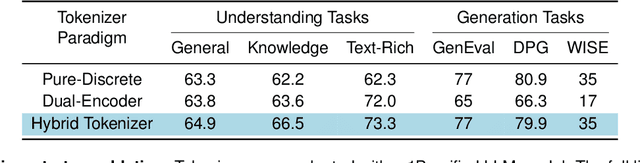
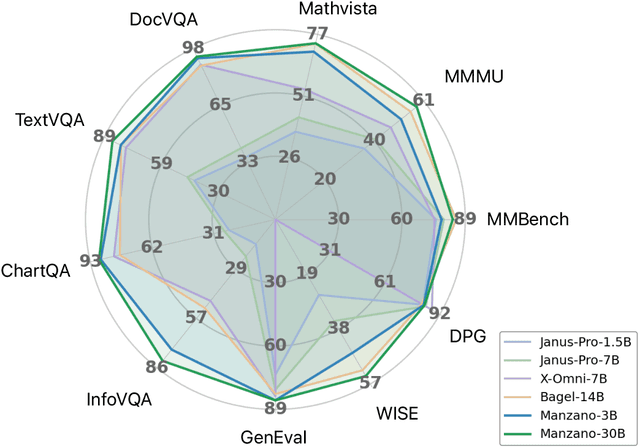
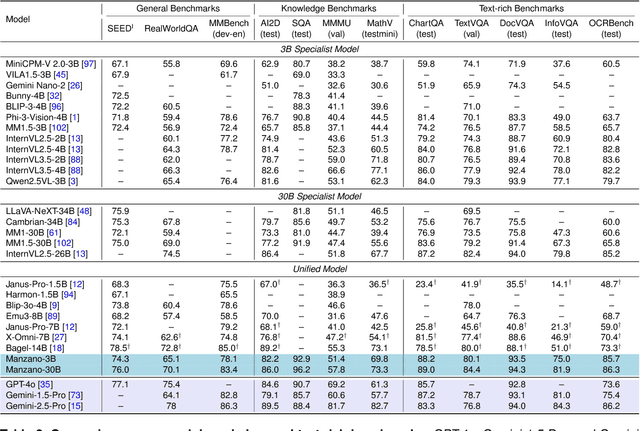
Unified multimodal Large Language Models (LLMs) that can both understand and generate visual content hold immense potential. However, existing open-source models often suffer from a performance trade-off between these capabilities. We present Manzano, a simple and scalable unified framework that substantially reduces this tension by coupling a hybrid image tokenizer with a well-curated training recipe. A single shared vision encoder feeds two lightweight adapters that produce continuous embeddings for image-to-text understanding and discrete tokens for text-to-image generation within a common semantic space. A unified autoregressive LLM predicts high-level semantics in the form of text and image tokens, with an auxiliary diffusion decoder subsequently translating the image tokens into pixels. The architecture, together with a unified training recipe over understanding and generation data, enables scalable joint learning of both capabilities. Manzano achieves state-of-the-art results among unified models, and is competitive with specialist models, particularly on text-rich evaluation. Our studies show minimal task conflicts and consistent gains from scaling model size, validating our design choice of a hybrid tokenizer.
EC-DIT: Scaling Diffusion Transformers with Adaptive Expert-Choice Routing
Oct 02, 2024



Diffusion transformers have been widely adopted for text-to-image synthesis. While scaling these models up to billions of parameters shows promise, the effectiveness of scaling beyond current sizes remains underexplored and challenging. By explicitly exploiting the computational heterogeneity of image generations, we develop a new family of Mixture-of-Experts (MoE) models (EC-DIT) for diffusion transformers with expert-choice routing. EC-DIT learns to adaptively optimize the compute allocated to understand the input texts and generate the respective image patches, enabling heterogeneous computation aligned with varying text-image complexities. This heterogeneity provides an efficient way of scaling EC-DIT up to 97 billion parameters and achieving significant improvements in training convergence, text-to-image alignment, and overall generation quality over dense models and conventional MoE models. Through extensive ablations, we show that EC-DIT demonstrates superior scalability and adaptive compute allocation by recognizing varying textual importance through end-to-end training. Notably, in text-to-image alignment evaluation, our largest models achieve a state-of-the-art GenEval score of 71.68% and still maintain competitive inference speed with intuitive interpretability.
Apple Intelligence Foundation Language Models
Jul 29, 2024



We present foundation language models developed to power Apple Intelligence features, including a ~3 billion parameter model designed to run efficiently on devices and a large server-based language model designed for Private Cloud Compute. These models are designed to perform a wide range of tasks efficiently, accurately, and responsibly. This report describes the model architecture, the data used to train the model, the training process, how the models are optimized for inference, and the evaluation results. We highlight our focus on Responsible AI and how the principles are applied throughout the model development.
VALAN: Vision and Language Agent Navigation
Dec 06, 2019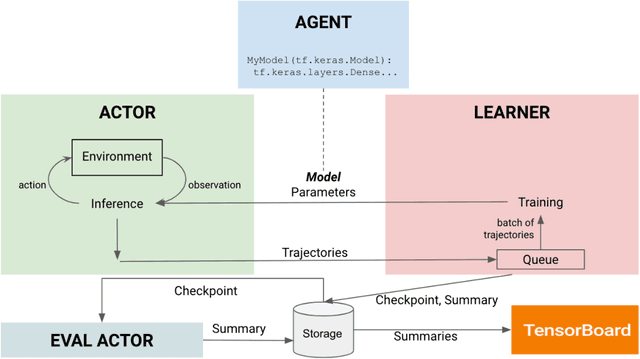
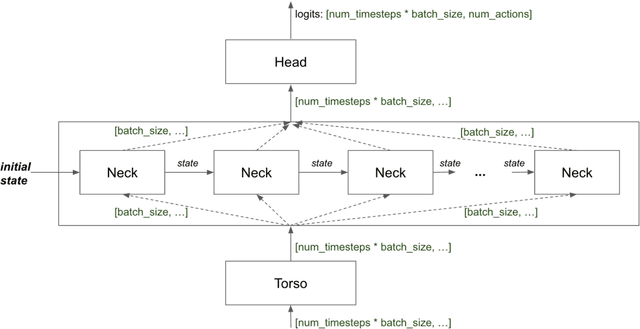
VALAN is a lightweight and scalable software framework for deep reinforcement learning based on the SEED RL architecture. The framework facilitates the development and evaluation of embodied agents for solving grounded language understanding tasks, such as Vision-and-Language Navigation and Vision-and-Dialog Navigation, in photo-realistic environments, such as Matterport3D and Google StreetView. We have added a minimal set of abstractions on top of SEED RL allowing us to generalize the architecture to solve a variety of other RL problems. In this article, we will describe VALAN's software abstraction and architecture, and also present an example of using VALAN to design agents for instruction-conditioned indoor navigation.
Transferable Representation Learning in Vision-and-Language Navigation
Aug 12, 2019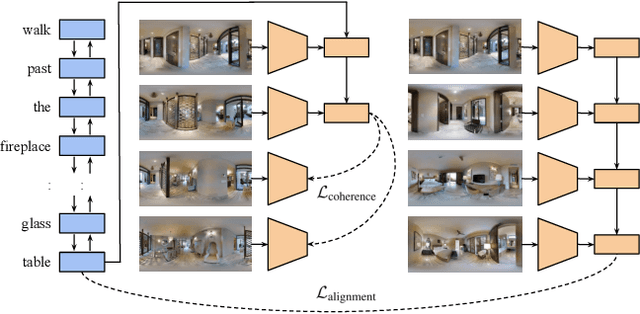


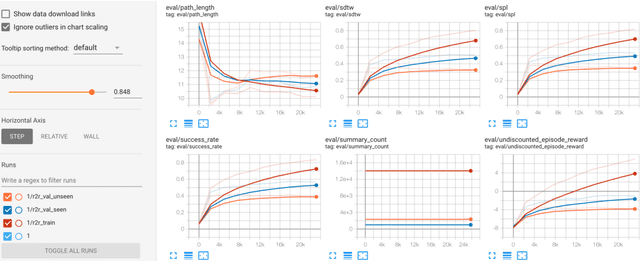
Vision-and-Language Navigation (VLN) tasks such as Room-to-Room (R2R) require machine agents to interpret natural language instructions and learn to act in visually realistic environments to achieve navigation goals. The overall task requires competence in several perception problems: successful agents combine spatio-temporal, vision and language understanding to produce appropriate action sequences. Our approach adapts pre-trained vision and language representations to relevant in-domain tasks making them more effective for VLN. Specifically, the representations are adapted to solve both a cross-modal sequence alignment and sequence coherence task. In the sequence alignment task, the model determines whether an instruction corresponds to a sequence of visual frames. In the sequence coherence task, the model determines whether the perceptual sequences are predictive sequentially in the instruction-conditioned latent space. By transferring the domain-adapted representations, we improve competitive agents in R2R as measured by the success rate weighted by path length (SPL) metric.
Multi-modal Discriminative Model for Vision-and-Language Navigation
May 31, 2019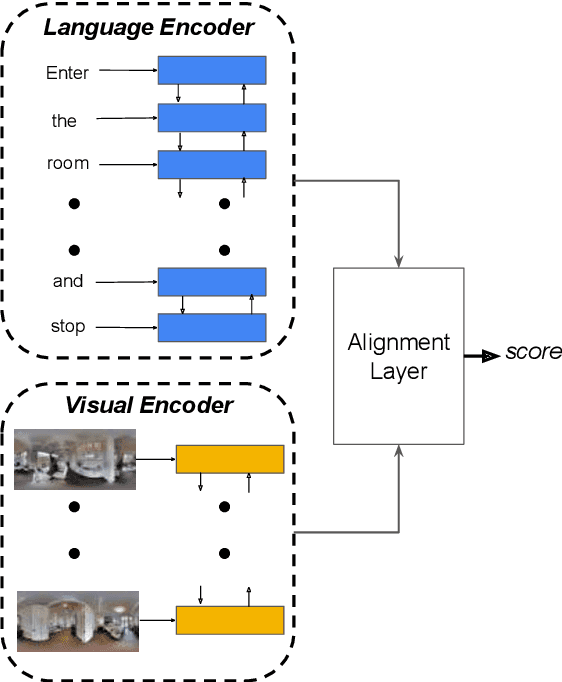
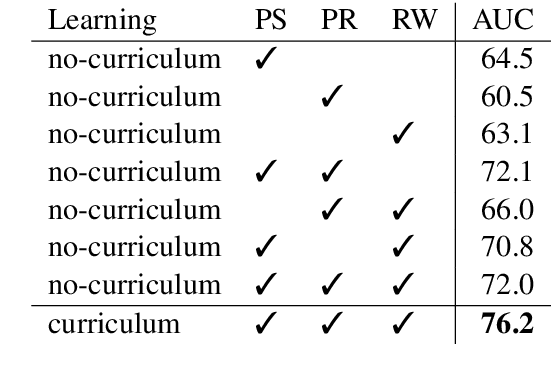
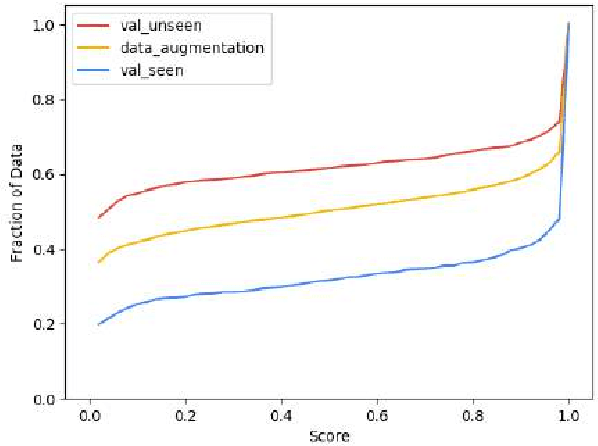
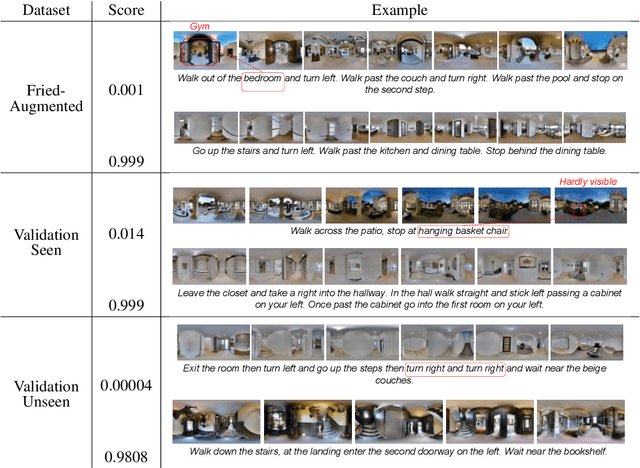
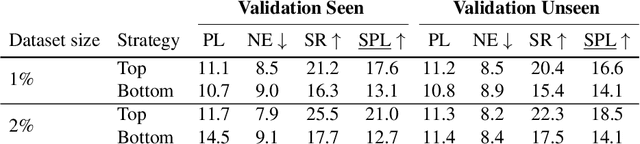
Vision-and-Language Navigation (VLN) is a natural language grounding task where agents have to interpret natural language instructions in the context of visual scenes in a dynamic environment to achieve prescribed navigation goals. Successful agents must have the ability to parse natural language of varying linguistic styles, ground them in potentially unfamiliar scenes, plan and react with ambiguous environmental feedback. Generalization ability is limited by the amount of human annotated data. In particular, \emph{paired} vision-language sequence data is expensive to collect. We develop a discriminator that evaluates how well an instruction explains a given path in VLN task using multi-modal alignment. Our study reveals that only a small fraction of the high-quality augmented data from \citet{Fried:2018:Speaker}, as scored by our discriminator, is useful for training VLN agents with similar performance on previously unseen environments. We also show that a VLN agent warm-started with pre-trained components from the discriminator outperforms the benchmark success rates of 35.5 by 10\% relative measure on previously unseen environments.