Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVALAN: Vision and Language Agent Navigation
Paper and Code
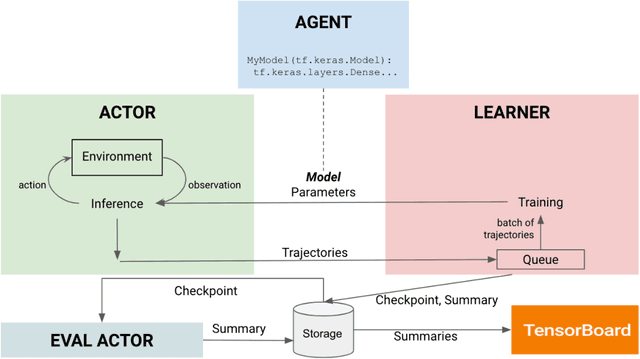
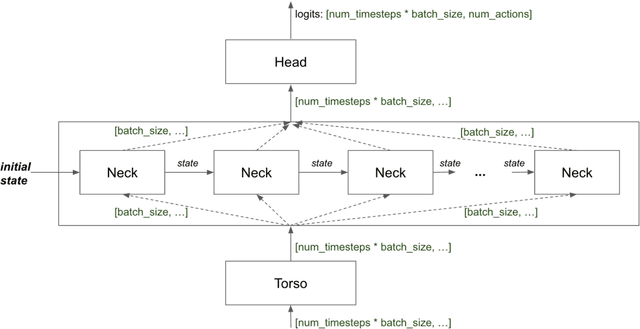
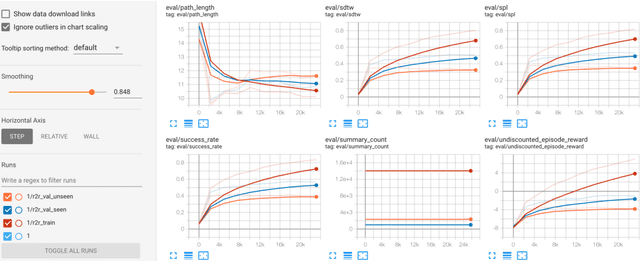
VALAN is a lightweight and scalable software framework for deep reinforcement learning based on the SEED RL architecture. The framework facilitates the development and evaluation of embodied agents for solving grounded language understanding tasks, such as Vision-and-Language Navigation and Vision-and-Dialog Navigation, in photo-realistic environments, such as Matterport3D and Google StreetView. We have added a minimal set of abstractions on top of SEED RL allowing us to generalize the architecture to solve a variety of other RL problems. In this article, we will describe VALAN's software abstraction and architecture, and also present an example of using VALAN to design agents for instruction-conditioned indoor navigation.
View paper on