 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining with Contrastive Sentence Objectives Improves Discourse Performance of Language Models
May 20, 2020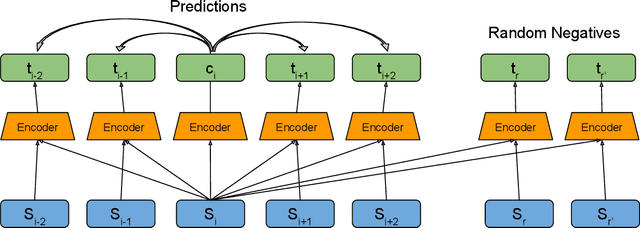
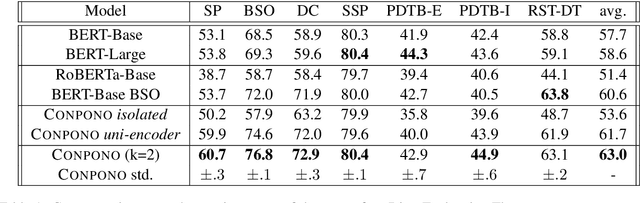
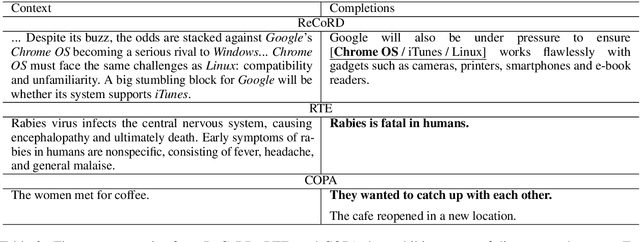
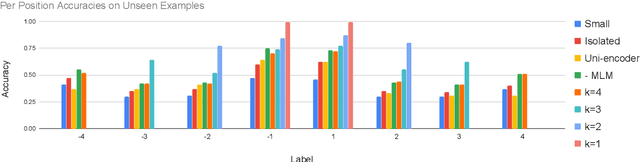
Recent models for unsupervised representation learning of text have employed a number of techniques to improve contextual word representations but have put little focus on discourse-level representations. We propose CONPONO, an inter-sentence objective for pretraining language models that models discourse coherence and the distance between sentences. Given an anchor sentence, our model is trained to predict the text k sentences away using a sampled-softmax objective where the candidates consist of neighboring sentences and sentences randomly sampled from the corpus. On the discourse representation benchmark DiscoEval, our model improves over the previous state-of-the-art by up to 13% and on average 4% absolute across 7 tasks. Our model is the same size as BERT-Base, but outperforms the much larger BERT- Large model and other more recent approaches that incorporate discourse. We also show that CONPONO yields gains of 2%-6% absolute even for tasks that do not explicitly evaluate discourse: textual entailment (RTE), common sense reasoning (COPA) and reading comprehension (ReCoRD).
VALAN: Vision and Language Agent Navigation
Dec 06, 2019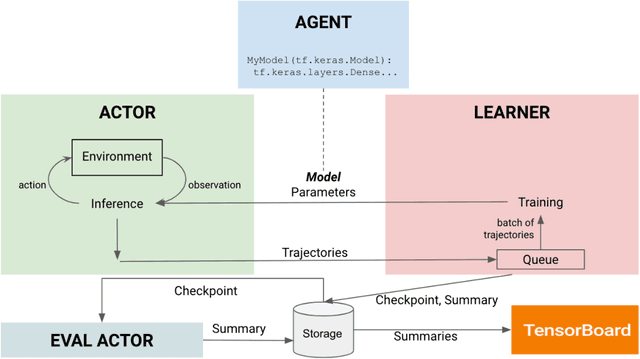
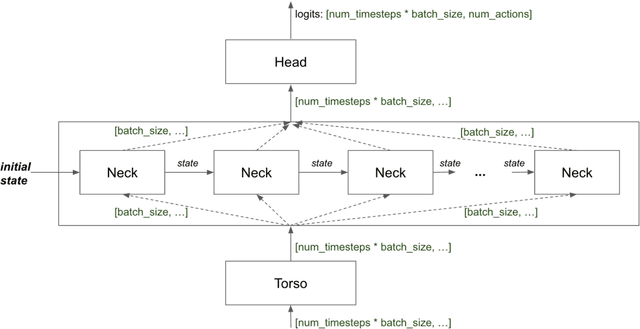
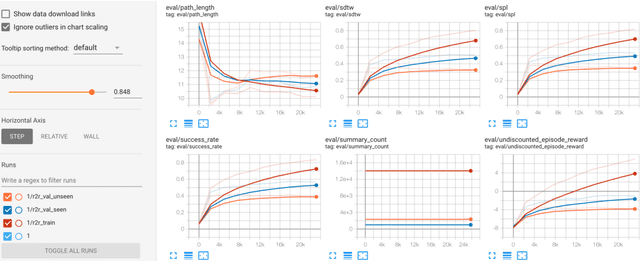
VALAN is a lightweight and scalable software framework for deep reinforcement learning based on the SEED RL architecture. The framework facilitates the development and evaluation of embodied agents for solving grounded language understanding tasks, such as Vision-and-Language Navigation and Vision-and-Dialog Navigation, in photo-realistic environments, such as Matterport3D and Google StreetView. We have added a minimal set of abstractions on top of SEED RL allowing us to generalize the architecture to solve a variety of other RL problems. In this article, we will describe VALAN's software abstraction and architecture, and also present an example of using VALAN to design agents for instruction-conditioned indoor navigation.
Learning Dense Representations for Entity Retrieval
Sep 23, 2019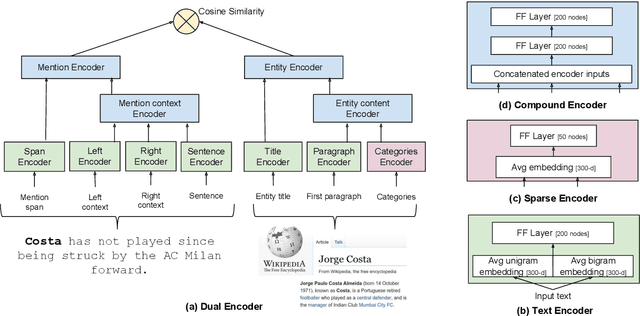
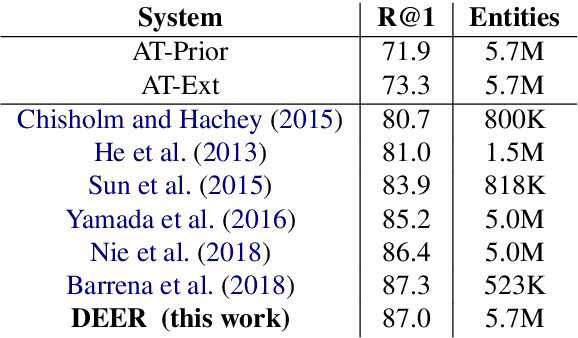
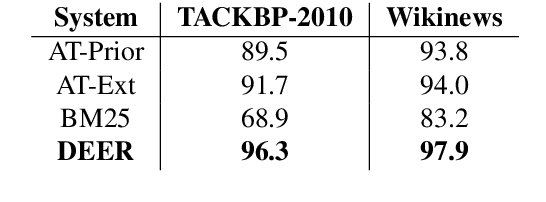
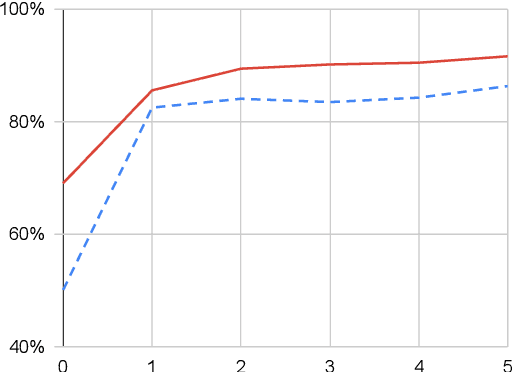
We show that it is feasible to perform entity linking by training a dual encoder (two-tower) model that encodes mentions and entities in the same dense vector space, where candidate entities are retrieved by approximate nearest neighbor search. Unlike prior work, this setup does not rely on an alias table followed by a re-ranker, and is thus the first fully learned entity retrieval model. We show that our dual encoder, trained using only anchor-text links in Wikipedia, outperforms discrete alias table and BM25 baselines, and is competitive with the best comparable results on the standard TACKBP-2010 dataset. In addition, it can retrieve candidates extremely fast, and generalizes well to a new dataset derived from Wikinews. On the modeling side, we demonstrate the dramatic value of an unsupervised negative mining algorithm for this task.