 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemma 2: Improving Open Language Models at a Practical Size
Aug 02, 2024



In this work, we introduce Gemma 2, a new addition to the Gemma family of lightweight, state-of-the-art open models, ranging in scale from 2 billion to 27 billion parameters. In this new version, we apply several known technical modifications to the Transformer architecture, such as interleaving local-global attentions (Beltagy et al., 2020a) and group-query attention (Ainslie et al., 2023). We also train the 2B and 9B models with knowledge distillation (Hinton et al., 2015) instead of next token prediction. The resulting models deliver the best performance for their size, and even offer competitive alternatives to models that are 2-3 times bigger. We release all our models to the community.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021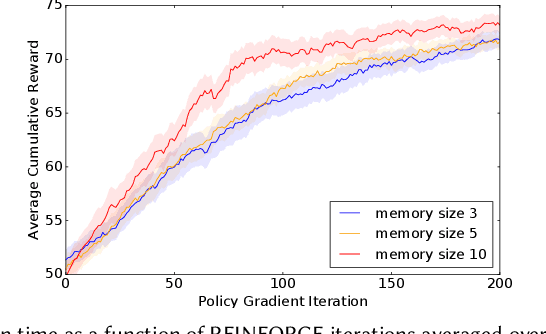
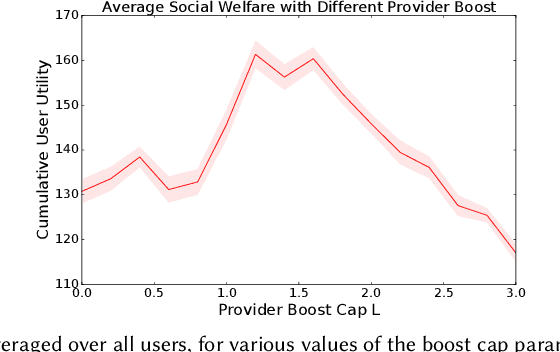
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
On the Evaluation of Vision-and-Language Navigation Instructions
Jan 26, 2021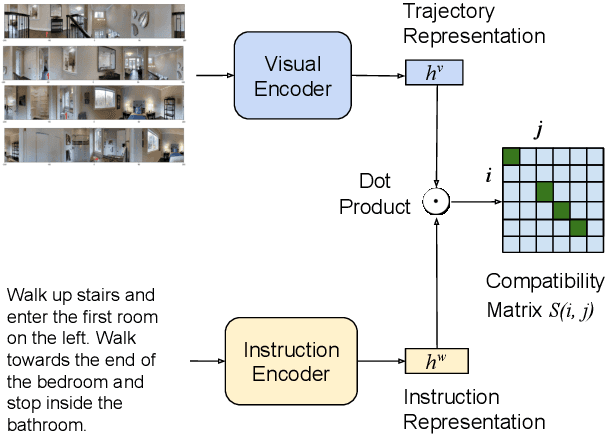
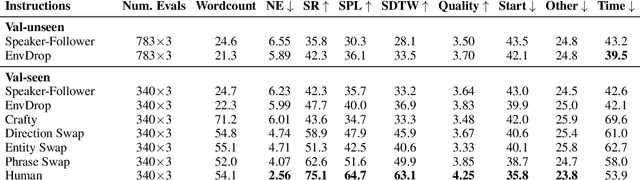
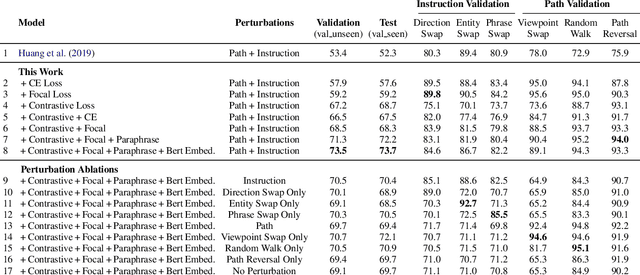
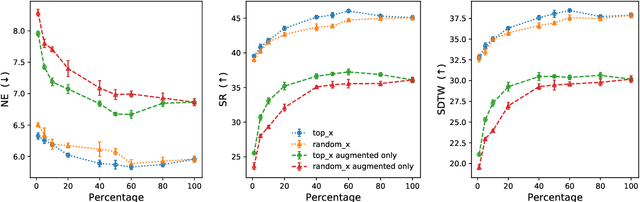
Vision-and-Language Navigation wayfinding agents can be enhanced by exploiting automatically generated navigation instructions. However, existing instruction generators have not been comprehensively evaluated, and the automatic evaluation metrics used to develop them have not been validated. Using human wayfinders, we show that these generators perform on par with or only slightly better than a template-based generator and far worse than human instructors. Furthermore, we discover that BLEU, ROUGE, METEOR and CIDEr are ineffective for evaluating grounded navigation instructions. To improve instruction evaluation, we propose an instruction-trajectory compatibility model that operates without reference instructions. Our model shows the highest correlation with human wayfinding outcomes when scoring individual instructions. For ranking instruction generation systems, if reference instructions are available we recommend using SPICE.
A Hierarchical Multi-Modal Encoder for Moment Localization in Video Corpus
Nov 24, 2020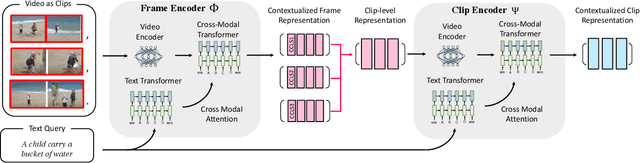
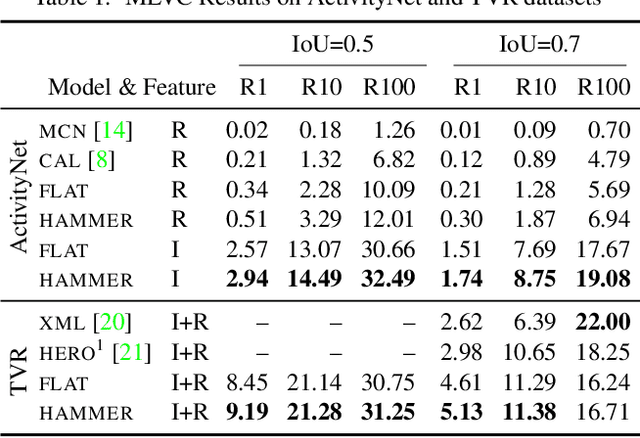
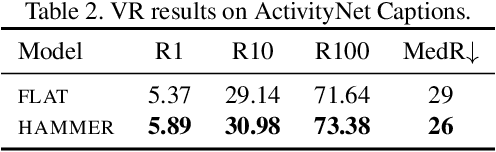
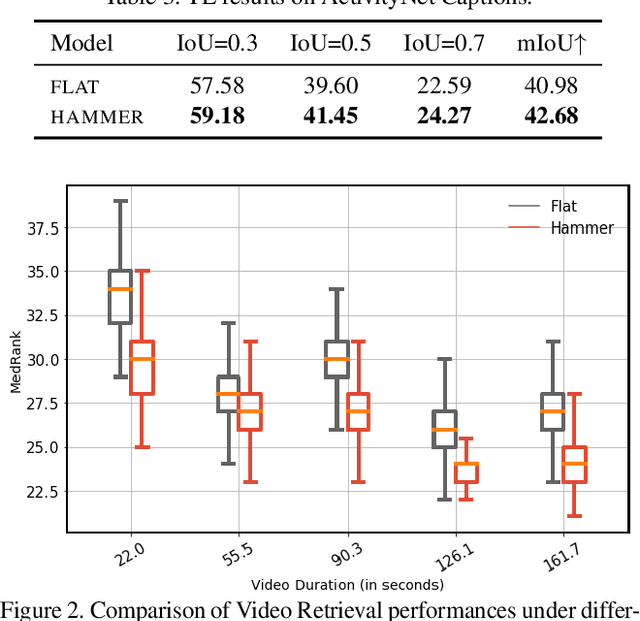
Identifying a short segment in a long video that semantically matches a text query is a challenging task that has important application potentials in language-based video search, browsing, and navigation. Typical retrieval systems respond to a query with either a whole video or a pre-defined video segment, but it is challenging to localize undefined segments in untrimmed and unsegmented videos where exhaustively searching over all possible segments is intractable. The outstanding challenge is that the representation of a video must account for different levels of granularity in the temporal domain. To tackle this problem, we propose the HierArchical Multi-Modal EncodeR (HAMMER) that encodes a video at both the coarse-grained clip level and the fine-grained frame level to extract information at different scales based on multiple subtasks, namely, video retrieval, segment temporal localization, and masked language modeling. We conduct extensive experiments to evaluate our model on moment localization in video corpus on ActivityNet Captions and TVR datasets. Our approach outperforms the previous methods as well as strong baselines, establishing new state-of-the-art for this task.
Learning to Represent Image and Text with Denotation Graph
Oct 06, 2020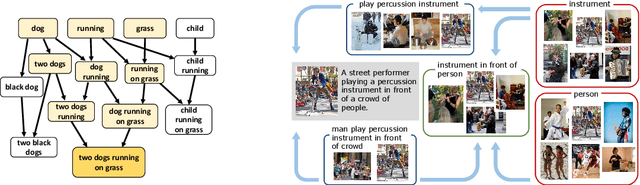

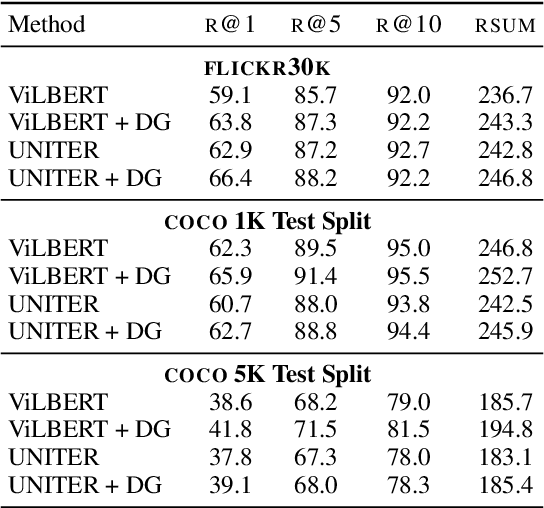
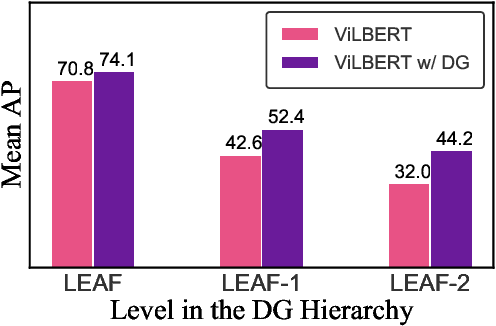
Learning to fuse vision and language information and representing them is an important research problem with many applications. Recent progresses have leveraged the ideas of pre-training (from language modeling) and attention layers in Transformers to learn representation from datasets containing images aligned with linguistic expressions that describe the images. In this paper, we propose learning representations from a set of implied, visually grounded expressions between image and text, automatically mined from those datasets. In particular, we use denotation graphs to represent how specific concepts (such as sentences describing images) can be linked to abstract and generic concepts (such as short phrases) that are also visually grounded. This type of generic-to-specific relations can be discovered using linguistic analysis tools. We propose methods to incorporate such relations into learning representation. We show that state-of-the-art multimodal learning models can be further improved by leveraging automatically harvested structural relations. The representations lead to stronger empirical results on downstream tasks of cross-modal image retrieval, referring expression, and compositional attribute-object recognition. Both our codes and the extracted denotation graphs on the Flickr30K and the COCO datasets are publically available on https://sha-lab.github.io/DG.
BabyWalk: Going Farther in Vision-and-Language Navigation by Taking Baby Steps
Jun 14, 2020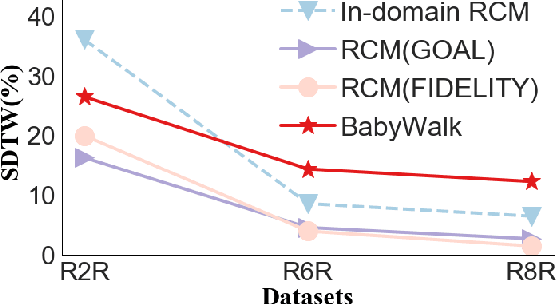
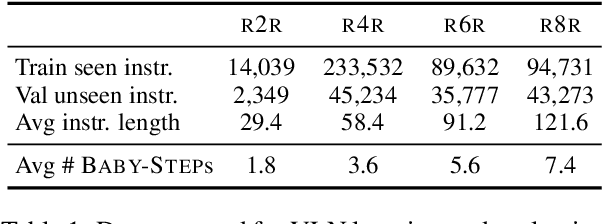
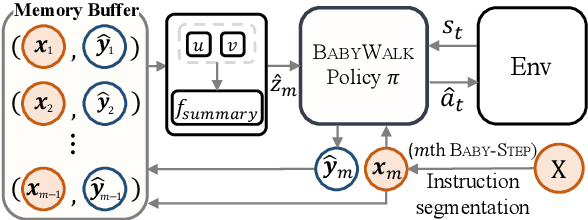
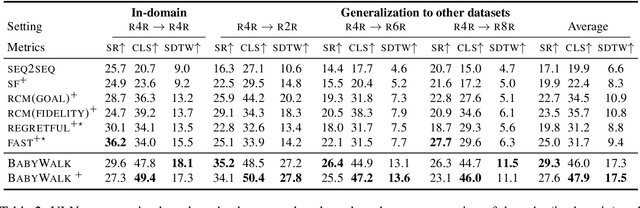
Learning to follow instructions is of fundamental importance to autonomous agents for vision-and-language navigation (VLN). In this paper, we study how an agent can navigate long paths when learning from a corpus that consists of shorter ones. We show that existing state-of-the-art agents do not generalize well. To this end, we propose BabyWalk, a new VLN agent that is learned to navigate by decomposing long instructions into shorter ones (BabySteps) and completing them sequentially. A special design memory buffer is used by the agent to turn its past experiences into contexts for future steps. The learning process is composed of two phases. In the first phase, the agent uses imitation learning from demonstration to accomplish BabySteps. In the second phase, the agent uses curriculum-based reinforcement learning to maximize rewards on navigation tasks with increasingly longer instructions. We create two new benchmark datasets (of long navigation tasks) and use them in conjunction with existing ones to examine BabyWalk's generalization ability. Empirical results show that BabyWalk achieves state-of-the-art results on several metrics, in particular, is able to follow long instructions better. The codes and the datasets are released on our project page https://github.com/Sha-Lab/babywalk.
Environment-agnostic Multitask Learning for Natural Language Grounded Navigation
Mar 12, 2020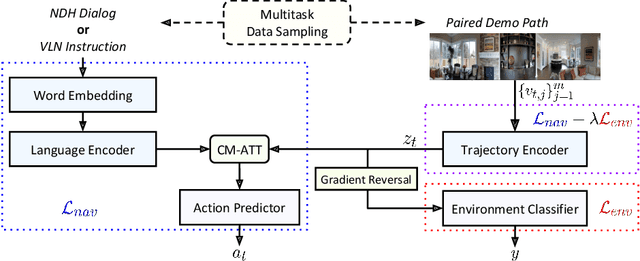
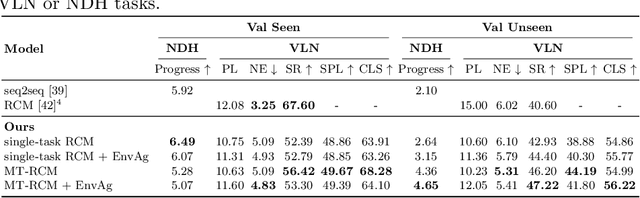
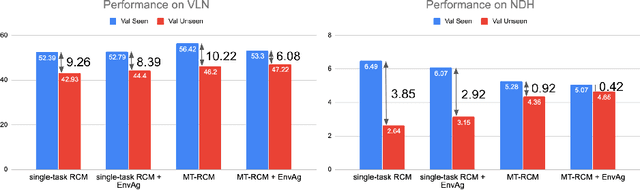
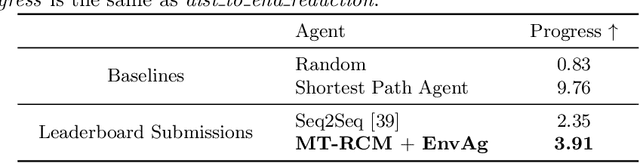
Recent research efforts enable study for natural language grounded navigation in photo-realistic environments, e.g., following natural language instructions or dialog. However, existing methods tend to overfit training data in seen environments and fail to generalize well in previously unseen environments. In order to close the gap between seen and unseen environments, we aim at learning a generalized navigation model from two novel perspectives: (1) we introduce a multitask navigation model that can be seamlessly trained on both Vision-Language Navigation (VLN) and Navigation from Dialog History (NDH) tasks, which benefits from richer natural language guidance and effectively transfers knowledge across tasks; (2) we propose to learn environment-agnostic representations for the navigation policy that are invariant among the environments seen during training, thus generalizing better on unseen environments. Extensive experiments show that training with environment-agnostic multitask learning objective significantly reduces the performance gap between seen and unseen environments and the navigation agent so trained outperforms the baselines on unseen environments by 16% (relative measure on success rate) on VLN and 120% (goal progress) on NDH. Our submission to the CVDN leaderboard establishes a new state-of-the-art for the NDH task outperforming the existing best model by more than 66% (goal progress) on the holdout test set. The code for training the navigation model using environment-agnostic multitask learning is available at https://github.com/google-research/valan.
VALAN: Vision and Language Agent Navigation
Dec 06, 2019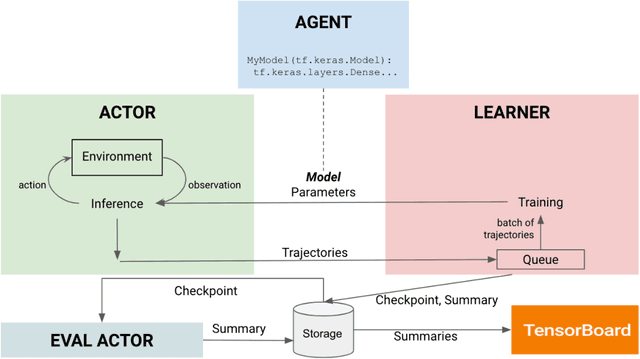
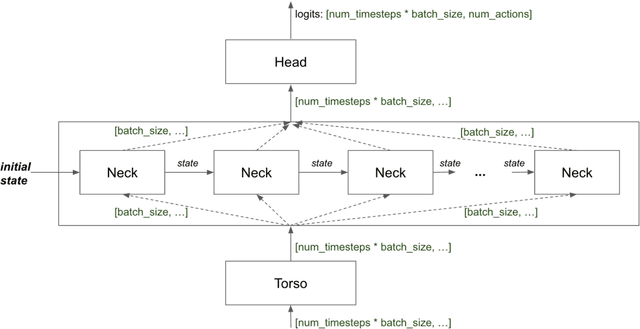
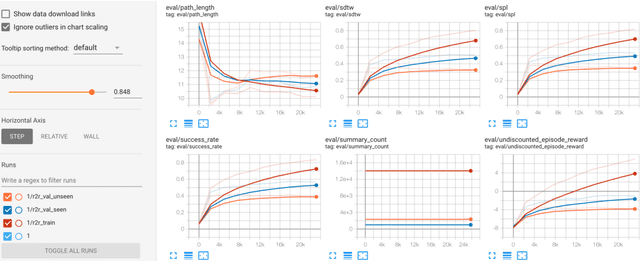
VALAN is a lightweight and scalable software framework for deep reinforcement learning based on the SEED RL architecture. The framework facilitates the development and evaluation of embodied agents for solving grounded language understanding tasks, such as Vision-and-Language Navigation and Vision-and-Dialog Navigation, in photo-realistic environments, such as Matterport3D and Google StreetView. We have added a minimal set of abstractions on top of SEED RL allowing us to generalize the architecture to solve a variety of other RL problems. In this article, we will describe VALAN's software abstraction and architecture, and also present an example of using VALAN to design agents for instruction-conditioned indoor navigation.
RecSim: A Configurable Simulation Platform for Recommender Systems
Sep 26, 2019
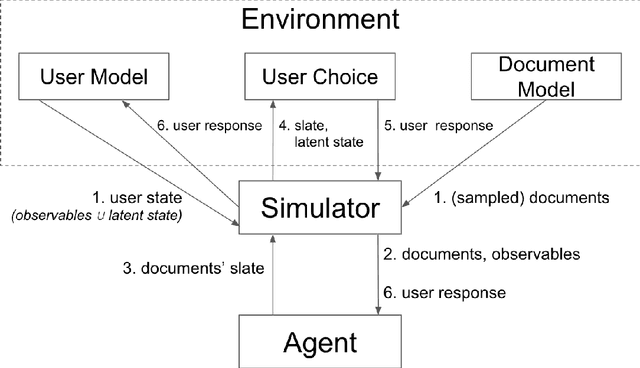
We propose RecSim, a configurable platform for authoring simulation environments for recommender systems (RSs) that naturally supports sequential interaction with users. RecSim allows the creation of new environments that reflect particular aspects of user behavior and item structure at a level of abstraction well-suited to pushing the limits of current reinforcement learning (RL) and RS techniques in sequential interactive recommendation problems. Environments can be easily configured that vary assumptions about: user preferences and item familiarity; user latent state and its dynamics; and choice models and other user response behavior. We outline how RecSim offers value to RL and RS researchers and practitioners, and how it can serve as a vehicle for academic-industrial collaboration.
Transferable Representation Learning in Vision-and-Language Navigation
Aug 12, 2019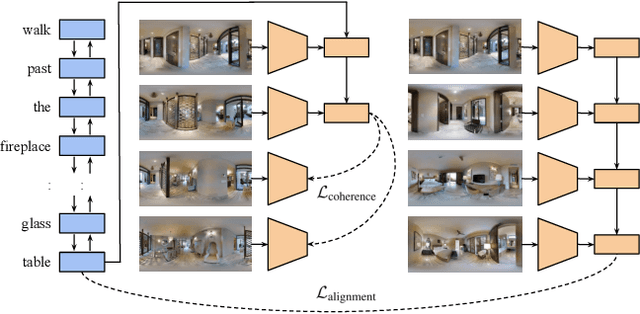

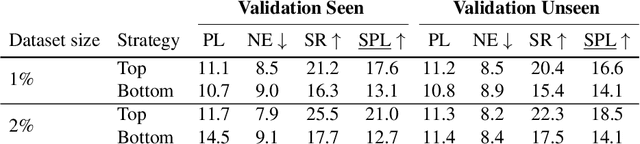

Vision-and-Language Navigation (VLN) tasks such as Room-to-Room (R2R) require machine agents to interpret natural language instructions and learn to act in visually realistic environments to achieve navigation goals. The overall task requires competence in several perception problems: successful agents combine spatio-temporal, vision and language understanding to produce appropriate action sequences. Our approach adapts pre-trained vision and language representations to relevant in-domain tasks making them more effective for VLN. Specifically, the representations are adapted to solve both a cross-modal sequence alignment and sequence coherence task. In the sequence alignment task, the model determines whether an instruction corresponds to a sequence of visual frames. In the sequence coherence task, the model determines whether the perceptual sequences are predictive sequentially in the instruction-conditioned latent space. By transferring the domain-adapted representations, we improve competitive agents in R2R as measured by the success rate weighted by path length (SPL) metric.