 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimizing Live Experiments in Recommender Systems: User Simulation to Evaluate Preference Elicitation Policies
Sep 26, 2024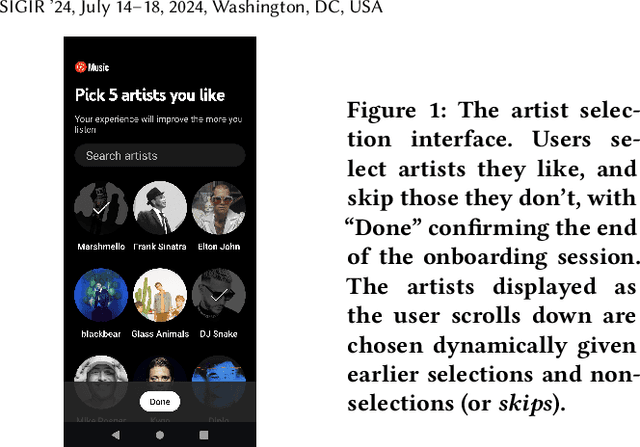
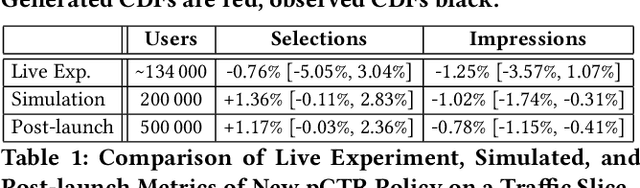
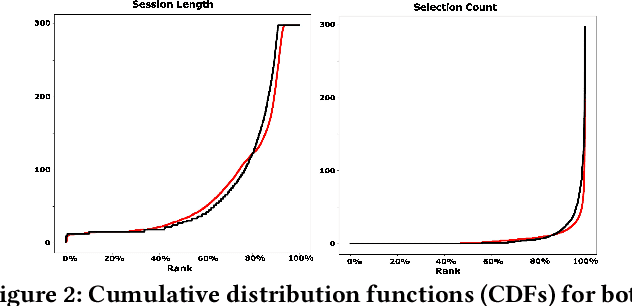
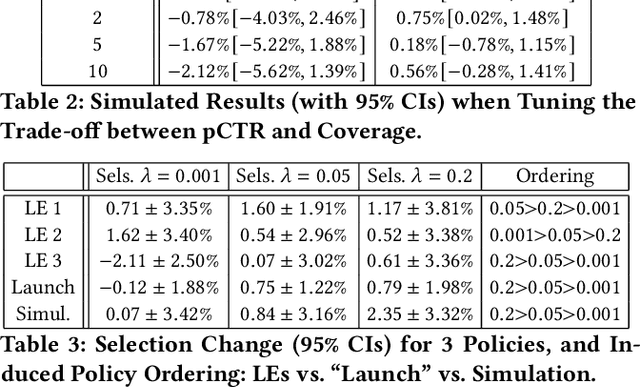
Evaluation of policies in recommender systems typically involves A/B testing using live experiments on real users to assess a new policy's impact on relevant metrics. This ``gold standard'' comes at a high cost, however, in terms of cycle time, user cost, and potential user retention. In developing policies for ``onboarding'' new users, these costs can be especially problematic, since on-boarding occurs only once. In this work, we describe a simulation methodology used to augment (and reduce) the use of live experiments. We illustrate its deployment for the evaluation of ``preference elicitation'' algorithms used to onboard new users of the YouTube Music platform. By developing counterfactually robust user behavior models, and a simulation service that couples such models with production infrastructure, we are able to test new algorithms in a way that reliably predicts their performance on key metrics when deployed live. We describe our domain, our simulation models and platform, results of experiments and deployment, and suggest future steps needed to further realistic simulation as a powerful complement to live experiments.
Report on the Workshop on Simulations for Information Access (Sim4IA 2024) at SIGIR 2024
Sep 26, 2024



This paper is a report of the Workshop on Simulations for Information Access (Sim4IA) workshop at SIGIR 2024. The workshop had two keynotes, a panel discussion, nine lightning talks, and two breakout sessions. Key takeaways were user simulation's importance in academia and industry, the possible bridging of online and offline evaluation, and the issues of organizing a companion shared task around user simulations for information access. We report on how we organized the workshop, provide a brief overview of what happened at the workshop, and summarize the main topics and findings of the workshop and future work.
Demystifying Embedding Spaces using Large Language Models
Oct 06, 2023Embeddings have become a pivotal means to represent complex, multi-faceted information about entities, concepts, and relationships in a condensed and useful format. Nevertheless, they often preclude direct interpretation. While downstream tasks make use of these compressed representations, meaningful interpretation usually requires visualization using dimensionality reduction or specialized machine learning interpretability methods. This paper addresses the challenge of making such embeddings more interpretable and broadly useful, by employing Large Language Models (LLMs) to directly interact with embeddings -- transforming abstract vectors into understandable narratives. By injecting embeddings into LLMs, we enable querying and exploration of complex embedding data. We demonstrate our approach on a variety of diverse tasks, including: enhancing concept activation vectors (CAVs), communicating novel embedded entities, and decoding user preferences in recommender systems. Our work couples the immense information potential of embeddings with the interpretative power of LLMs.
Modeling Recommender Ecosystems: Research Challenges at the Intersection of Mechanism Design, Reinforcement Learning and Generative Models
Sep 22, 2023
Modern recommender systems lie at the heart of complex ecosystems that couple the behavior of users, content providers, advertisers, and other actors. Despite this, the focus of the majority of recommender research -- and most practical recommenders of any import -- is on the local, myopic optimization of the recommendations made to individual users. This comes at a significant cost to the long-term utility that recommenders could generate for its users. We argue that explicitly modeling the incentives and behaviors of all actors in the system -- and the interactions among them induced by the recommender's policy -- is strictly necessary if one is to maximize the value the system brings to these actors and improve overall ecosystem "health". Doing so requires: optimization over long horizons using techniques such as reinforcement learning; making inevitable tradeoffs in the utility that can be generated for different actors using the methods of social choice; reducing information asymmetry, while accounting for incentives and strategic behavior, using the tools of mechanism design; better modeling of both user and item-provider behaviors by incorporating notions from behavioral economics and psychology; and exploiting recent advances in generative and foundation models to make these mechanisms interpretable and actionable. We propose a conceptual framework that encompasses these elements, and articulate a number of research challenges that emerge at the intersection of these different disciplines.
Content Prompting: Modeling Content Provider Dynamics to Improve User Welfare in Recommender Ecosystems
Sep 02, 2023



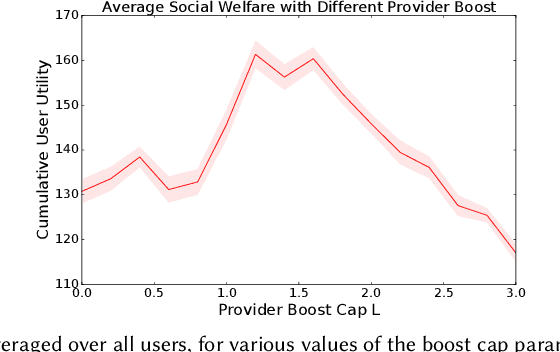
Users derive value from a recommender system (RS) only to the extent that it is able to surface content (or items) that meet their needs/preferences. While RSs often have a comprehensive view of user preferences across the entire user base, content providers, by contrast, generally have only a local view of the preferences of users that have interacted with their content. This limits a provider's ability to offer new content to best serve the broader population. In this work, we tackle this information asymmetry with content prompting policies. A content prompt is a hint or suggestion to a provider to make available novel content for which the RS predicts unmet user demand. A prompting policy is a sequence of such prompts that is responsive to the dynamics of a provider's beliefs, skills and incentives. We aim to determine a joint prompting policy that induces a set of providers to make content available that optimizes user social welfare in equilibrium, while respecting the incentives of the providers themselves. Our contributions include: (i) an abstract model of the RS ecosystem, including content provider behaviors, that supports such prompting; (ii) the design and theoretical analysis of sequential prompting policies for individual providers; (iii) a mixed integer programming formulation for optimal joint prompting using path planning in content space; and (iv) simple, proof-of-concept experiments illustrating how such policies improve ecosystem health and user welfare.
Reinforcement Learning with History-Dependent Dynamic Contexts
Feb 04, 2023

We introduce Dynamic Contextual Markov Decision Processes (DCMDPs), a novel reinforcement learning framework for history-dependent environments that generalizes the contextual MDP framework to handle non-Markov environments, where contexts change over time. We consider special cases of the model, with a focus on logistic DCMDPs, which break the exponential dependence on history length by leveraging aggregation functions to determine context transitions. This special structure allows us to derive an upper-confidence-bound style algorithm for which we establish regret bounds. Motivated by our theoretical results, we introduce a practical model-based algorithm for logistic DCMDPs that plans in a latent space and uses optimism over history-dependent features. We demonstrate the efficacy of our approach on a recommendation task (using MovieLens data) where user behavior dynamics evolve in response to recommendations.
Towards Content Provider Aware Recommender Systems: A Simulation Study on the Interplay between User and Provider Utilities
May 06, 2021
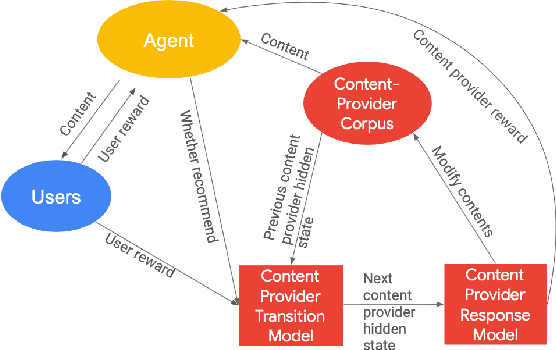
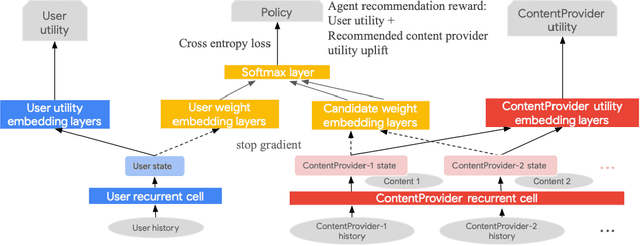
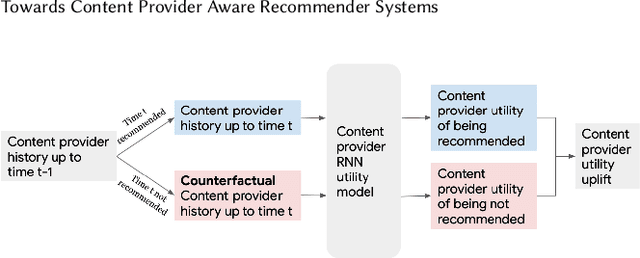
Most existing recommender systems focus primarily on matching users to content which maximizes user satisfaction on the platform. It is increasingly obvious, however, that content providers have a critical influence on user satisfaction through content creation, largely determining the content pool available for recommendation. A natural question thus arises: can we design recommenders taking into account the long-term utility of both users and content providers? By doing so, we hope to sustain more providers and a more diverse content pool for long-term user satisfaction. Understanding the full impact of recommendations on both user and provider groups is challenging. This paper aims to serve as a research investigation of one approach toward building a provider-aware recommender, and evaluating its impact in a simulated setup. To characterize the user-recommender-provider interdependence, we complement user modeling by formalizing provider dynamics as well. The resulting joint dynamical system gives rise to a weakly-coupled partially observable Markov decision process driven by recommender actions and user feedback to providers. We then build a REINFORCE recommender agent, coined EcoAgent, to optimize a joint objective of user utility and the counterfactual utility lift of the provider associated with the recommended content, which we show to be equivalent to maximizing overall user utility and the utilities of all providers on the platform under some mild assumptions. To evaluate our approach, we introduce a simulation environment capturing the key interactions among users, providers, and the recommender. We offer a number of simulated experiments that shed light on both the benefits and the limitations of our approach. These results help understand how and when a provider-aware recommender agent is of benefit in building multi-stakeholder recommender systems.
RecSim NG: Toward Principled Uncertainty Modeling for Recommender Ecosystems
Mar 14, 2021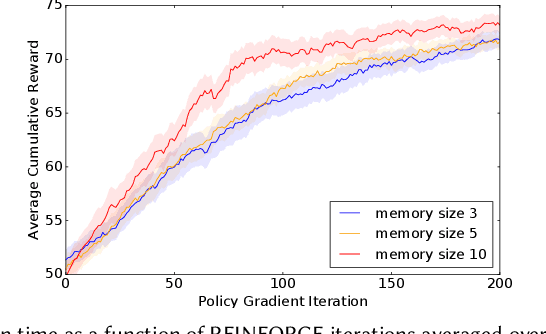
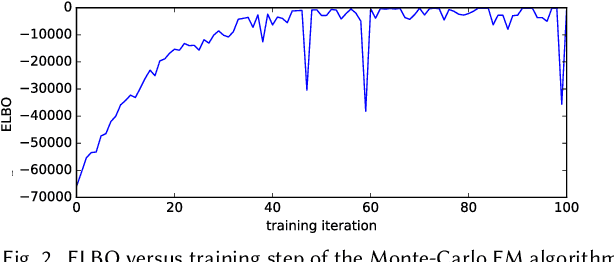
The development of recommender systems that optimize multi-turn interaction with users, and model the interactions of different agents (e.g., users, content providers, vendors) in the recommender ecosystem have drawn increasing attention in recent years. Developing and training models and algorithms for such recommenders can be especially difficult using static datasets, which often fail to offer the types of counterfactual predictions needed to evaluate policies over extended horizons. To address this, we develop RecSim NG, a probabilistic platform for the simulation of multi-agent recommender systems. RecSim NG is a scalable, modular, differentiable simulator implemented in Edward2 and TensorFlow. It offers: a powerful, general probabilistic programming language for agent-behavior specification; tools for probabilistic inference and latent-variable model learning, backed by automatic differentiation and tracing; and a TensorFlow-based runtime for running simulations on accelerated hardware. We describe RecSim NG and illustrate how it can be used to create transparent, configurable, end-to-end models of a recommender ecosystem, complemented by a small set of simple use cases that demonstrate how RecSim NG can help both researchers and practitioners easily develop and train novel algorithms for recommender systems.
Meta-Thompson Sampling
Feb 11, 2021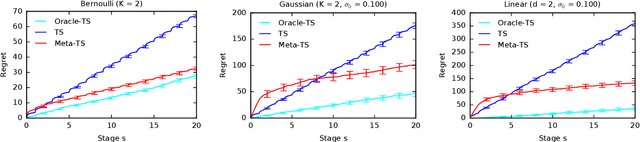
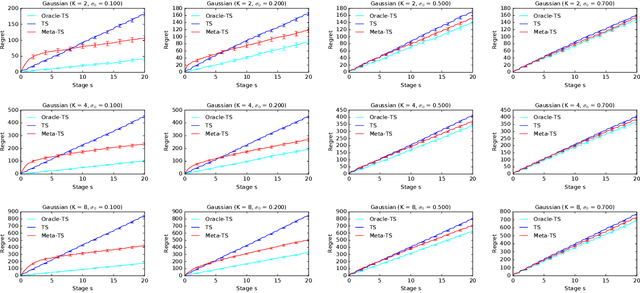
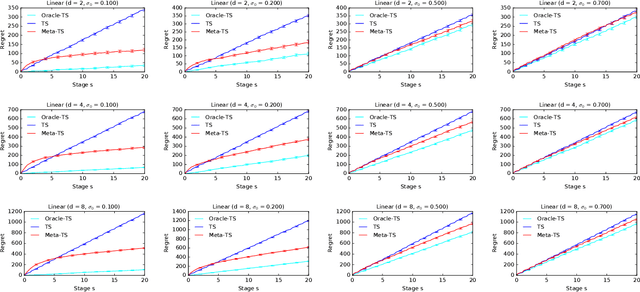
Efficient exploration in multi-armed bandits is a fundamental online learning problem. In this work, we propose a variant of Thompson sampling that learns to explore better as it interacts with problem instances drawn from an unknown prior distribution. Our algorithm meta-learns the prior and thus we call it Meta-TS. We propose efficient implementations of Meta-TS and analyze it in Gaussian bandits. Our analysis shows the benefit of meta-learning the prior and is of a broader interest, because we derive the first prior-dependent upper bound on the Bayes regret of Thompson sampling. This result is complemented by empirical evaluation, which shows that Meta-TS quickly adapts to the unknown prior.
Optimizing Long-term Social Welfare in Recommender Systems: A Constrained Matching Approach
Aug 18, 2020
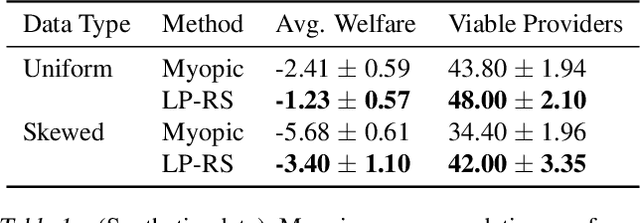
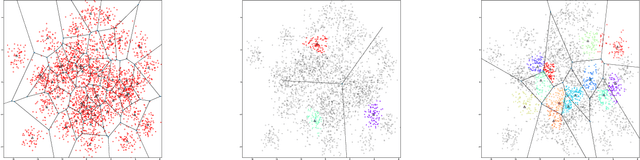
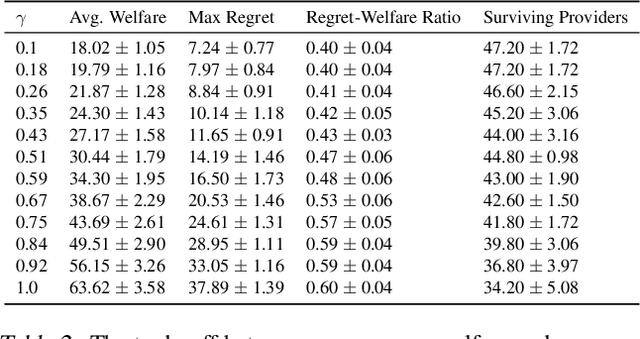
Most recommender systems (RS) research assumes that a user's utility can be maximized independently of the utility of the other agents (e.g., other users, content providers). In realistic settings, this is often not true---the dynamics of an RS ecosystem couple the long-term utility of all agents. In this work, we explore settings in which content providers cannot remain viable unless they receive a certain level of user engagement. We formulate the recommendation problem in this setting as one of equilibrium selection in the induced dynamical system, and show that it can be solved as an optimal constrained matching problem. Our model ensures the system reaches an equilibrium with maximal social welfare supported by a sufficiently diverse set of viable providers. We demonstrate that even in a simple, stylized dynamical RS model, the standard myopic approach to recommendation---always matching a user to the best provider---performs poorly. We develop several scalable techniques to solve the matching problem, and also draw connections to various notions of user regret and fairness, arguing that these outcomes are fairer in a utilitarian sense.