 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Competition to Collaboration: Designing Sustainable Mechanisms Between LLMs and Online Forums
Feb 04, 2026While Generative AI (GenAI) systems draw users away from (Q&A) forums, they also depend on the very data those forums produce to improve their performance. Addressing this paradox, we propose a framework of sequential interaction, in which a GenAI system proposes questions to a forum that can publish some of them. Our framework captures several intricacies of such a collaboration, including non-monetary exchanges, asymmetric information, and incentive misalignment. We bring the framework to life through comprehensive, data-driven simulations using real Stack Exchange data and commonly used LLMs. We demonstrate the incentive misalignment empirically, yet show that players can achieve roughly half of the utility in an ideal full-information scenario. Our results highlight the potential for sustainable collaboration that preserves effective knowledge sharing between AI systems and human knowledge platforms.
LLM Performance Predictors: Learning When to Escalate in Hybrid Human-AI Moderation Systems
Jan 11, 2026As LLMs are increasingly integrated into human-in-the-loop content moderation systems, a central challenge is deciding when their outputs can be trusted versus when escalation for human review is preferable. We propose a novel framework for supervised LLM uncertainty quantification, learning a dedicated meta-model based on LLM Performance Predictors (LPPs) derived from LLM outputs: log-probabilities, entropy, and novel uncertainty attribution indicators. We demonstrate that our method enables cost-aware selective classification in real-world human-AI workflows: escalating high-risk cases while automating the rest. Experiments across state-of-the-art LLMs, including both off-the-shelf (Gemini, GPT) and open-source (Llama, Qwen), on multimodal and multilingual moderation tasks, show significant improvements over existing uncertainty estimators in accuracy-cost trade-offs. Beyond uncertainty estimation, the LPPs enhance explainability by providing new insights into failure conditions (e.g., ambiguous content vs. under-specified policy). This work establishes a principled framework for uncertainty-aware, scalable, and responsible human-AI moderation workflows.
Effective Game-Theoretic Motion Planning via Nested Search
Nov 11, 2025To facilitate effective, safe deployment in the real world, individual robots must reason about interactions with other agents, which often occur without explicit communication. Recent work has identified game theory, particularly the concept of Nash Equilibrium (NE), as a key enabler for behavior-aware decision-making. Yet, existing work falls short of fully unleashing the power of game-theoretic reasoning. Specifically, popular optimization-based methods require simplified robot dynamics and tend to get trapped in local minima due to convexification. Other works that rely on payoff matrices suffer from poor scalability due to the explicit enumeration of all possible trajectories. To bridge this gap, we introduce Game-Theoretic Nested Search (GTNS), a novel, scalable, and provably correct approach for computing NEs in general dynamical systems. GTNS efficiently searches the action space of all agents involved, while discarding trajectories that violate the NE constraint (no unilateral deviation) through an inner search over a lower-dimensional space. Our algorithm enables explicit selection among equilibria by utilizing a user-specified global objective, thereby capturing a rich set of realistic interactions. We demonstrate the approach on a variety of autonomous driving and racing scenarios where we achieve solutions in mere seconds on commodity hardware.
Bandits with Single-Peaked Preferences and Limited Resources
Oct 10, 2025We study an online stochastic matching problem in which an algorithm sequentially matches $U$ users to $K$ arms, aiming to maximize cumulative reward over $T$ rounds under budget constraints. Without structural assumptions, computing the optimal matching is NP-hard, making online learning computationally infeasible. To overcome this barrier, we focus on \emph{single-peaked preferences} -- a well-established structure in social choice theory, where users' preferences are unimodal with respect to a common order over arms. We devise an efficient algorithm for the offline budgeted matching problem, and leverage it into an efficient online algorithm with a regret of $\tilde O(UKT^{2/3})$. Our approach relies on a novel PQ tree-based order approximation method. If the single-peaked structure is known, we develop an efficient UCB-like algorithm that achieves a regret bound of $\tilde O(U\sqrt{TK})$.
Data Sharing with a Generative AI Competitor
May 18, 2025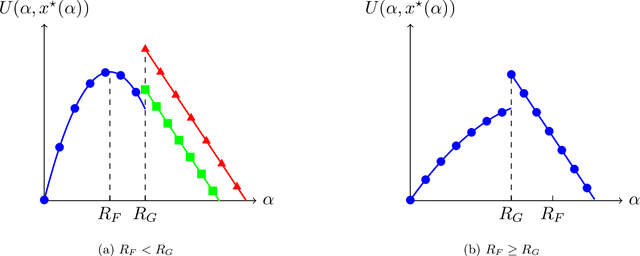
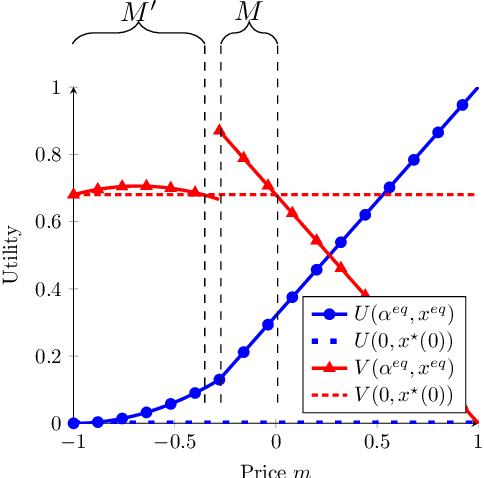
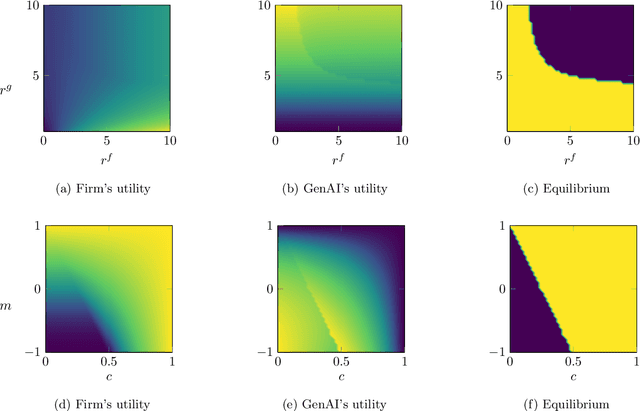
As GenAI platforms grow, their dependence on content from competing providers, combined with access to alternative data sources, creates new challenges for data-sharing decisions. In this paper, we provide a model of data sharing between a content creation firm and a GenAI platform that can also acquire content from third-party experts. The interaction is modeled as a Stackelberg game: the firm first decides how much of its proprietary dataset to share with GenAI, and GenAI subsequently determines how much additional data to acquire from external experts. Their utilities depend on user traffic, monetary transfers, and the cost of acquiring additional data from external experts. We characterize the unique subgame perfect equilibrium of the game and uncover a surprising phenomenon: The firm may be willing to pay GenAI to share the firm's own data, leading to a costly data-sharing equilibrium. We further characterize the set of Pareto improving data prices, and show that such improvements occur only when the firm pays to share data. Finally, we study how the price can be set to optimize different design objectives, such as promoting firm data sharing, expert data acquisition, or a balance of both. Our results shed light on the economic forces shaping data-sharing partnerships in the age of GenAI, and provide guidance for platforms, regulators and policymakers seeking to design effective data exchange mechanisms.
SySLLM: Generating Synthesized Policy Summaries for Reinforcement Learning Agents Using Large Language Models
Mar 13, 2025



Policies generated by Reinforcement Learning (RL) algorithms can be difficult to describe to users, as they result from the interplay between complex reward structures and neural network-based representations. This combination often leads to unpredictable behaviors, making policies challenging to analyze and posing significant obstacles to fostering human trust in real-world applications. Global policy summarization methods aim to describe agent behavior through a demonstration of actions in a subset of world-states. However, users can only watch a limited number of demonstrations, restricting their understanding of policies. Moreover, those methods overly rely on user interpretation, as they do not synthesize observations into coherent patterns. In this work, we present SySLLM (Synthesized Summary using LLMs), a novel method that employs synthesis summarization, utilizing large language models' (LLMs) extensive world knowledge and ability to capture patterns, to generate textual summaries of policies. Specifically, an expert evaluation demonstrates that the proposed approach generates summaries that capture the main insights generated by experts while not resulting in significant hallucinations. Additionally, a user study shows that SySLLM summaries are preferred over demonstration-based policy summaries and match or surpass their performance in objective agent identification tasks.
Envious Explore and Exploit
Feb 18, 2025Explore-and-exploit tradeoffs play a key role in recommendation systems (RSs), aiming at serving users better by learning from previous interactions. Despite their commercial success, the societal effects of explore-and-exploit mechanisms are not well understood, especially regarding the utility discrepancy they generate between different users. In this work, we measure such discrepancy using the economic notion of envy. We present a multi-armed bandit-like model in which every round consists of several sessions, and rewards are realized once per round. We call the latter property reward consistency, and show that the RS can leverage this property for better societal outcomes. On the downside, doing so also generates envy, as late-to-arrive users enjoy the information gathered by early-to-arrive users. We examine the generated envy under several arrival order mechanisms and virtually any anonymous algorithm, i.e., any algorithm that treats all similar users similarly without leveraging their identities. We provide tight envy bounds on uniform arrival and upper bound the envy for nudged arrival, in which the RS can affect the order of arrival by nudging its users. Furthermore, we study the efficiency-fairness trade-off by devising an algorithm that allows constant envy and approximates the optimal welfare in restricted settings. Finally, we validate our theoretical results empirically using simulations.
Selective Response Strategies for GenAI
Feb 02, 2025



The rise of Generative AI (GenAI) has significantly impacted human-based forums like Stack Overflow, which are essential for generating high-quality data. This creates a negative feedback loop, hindering the development of GenAI systems, which rely on such data to provide accurate responses. In this paper, we provide a possible remedy: A novel strategy we call selective response. Selective response implies that GenAI could strategically provide inaccurate (or conservative) responses to queries involving emerging topics and novel technologies, thereby driving users to use human-based forums like Stack Overflow. We show that selective response can potentially have a compounding effect on the data generation process, increasing both GenAI's revenue and user welfare in the long term. From an algorithmic perspective, we propose an approximately optimal approach to maximize GenAI's revenue under social welfare constraints. From a regulatory perspective, we derive sufficient and necessary conditions for selective response to improve welfare improvements.
Personalized Reinforcement Learning with a Budget of Policies
Jan 12, 2024Personalization in machine learning (ML) tailors models' decisions to the individual characteristics of users. While this approach has seen success in areas like recommender systems, its expansion into high-stakes fields such as healthcare and autonomous driving is hindered by the extensive regulatory approval processes involved. To address this challenge, we propose a novel framework termed represented Markov Decision Processes (r-MDPs) that is designed to balance the need for personalization with the regulatory constraints. In an r-MDP, we cater to a diverse user population, each with unique preferences, through interaction with a small set of representative policies. Our objective is twofold: efficiently match each user to an appropriate representative policy and simultaneously optimize these policies to maximize overall social welfare. We develop two deep reinforcement learning algorithms that efficiently solve r-MDPs. These algorithms draw inspiration from the principles of classic K-means clustering and are underpinned by robust theoretical foundations. Our empirical investigations, conducted across a variety of simulated environments, showcase the algorithms' ability to facilitate meaningful personalization even under constrained policy budgets. Furthermore, they demonstrate scalability, efficiently adapting to larger policy budgets.
Principal-Agent Reward Shaping in MDPs
Dec 30, 2023Principal-agent problems arise when one party acts on behalf of another, leading to conflicts of interest. The economic literature has extensively studied principal-agent problems, and recent work has extended this to more complex scenarios such as Markov Decision Processes (MDPs). In this paper, we further explore this line of research by investigating how reward shaping under budget constraints can improve the principal's utility. We study a two-player Stackelberg game where the principal and the agent have different reward functions, and the agent chooses an MDP policy for both players. The principal offers an additional reward to the agent, and the agent picks their policy selfishly to maximize their reward, which is the sum of the original and the offered reward. Our results establish the NP-hardness of the problem and offer polynomial approximation algorithms for two classes of instances: Stochastic trees and deterministic decision processes with a finite horizon.