 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficacy of Synthetic Data as a Benchmark
Sep 18, 2024Large language models (LLMs) have enabled a range of applications in zero-shot and few-shot learning settings, including the generation of synthetic datasets for training and testing. However, to reliably use these synthetic datasets, it is essential to understand how representative they are of real-world data. We investigate this by assessing the effectiveness of generating synthetic data through LLM and using it as a benchmark for various NLP tasks. Our experiments across six datasets, and three different tasks, show that while synthetic data can effectively capture performance of various methods for simpler tasks, such as intent classification, it falls short for more complex tasks like named entity recognition. Additionally, we propose a new metric called the bias factor, which evaluates the biases introduced when the same LLM is used to both generate benchmarking data and to perform the tasks. We find that smaller LLMs exhibit biases towards their own generated data, whereas larger models do not. Overall, our findings suggest that the effectiveness of synthetic data as a benchmark varies depending on the task, and that practitioners should rely on data generated from multiple larger models whenever possible.
ASR Benchmarking: Need for a More Representative Conversational Dataset
Sep 18, 2024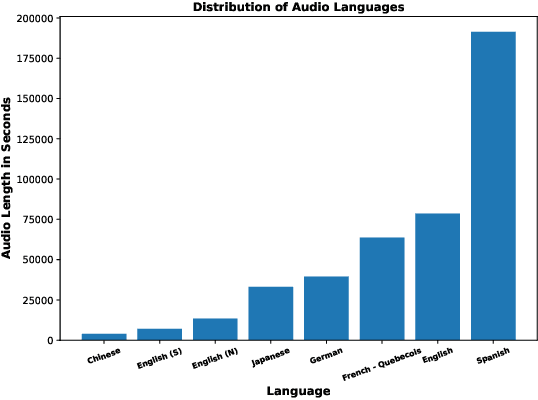

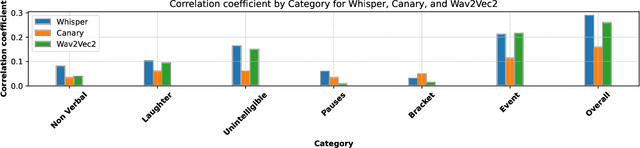
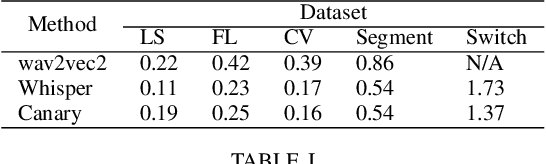
Automatic Speech Recognition (ASR) systems have achieved remarkable performance on widely used benchmarks such as LibriSpeech and Fleurs. However, these benchmarks do not adequately reflect the complexities of real-world conversational environments, where speech is often unstructured and contains disfluencies such as pauses, interruptions, and diverse accents. In this study, we introduce a multilingual conversational dataset, derived from TalkBank, consisting of unstructured phone conversation between adults. Our results show a significant performance drop across various state-of-the-art ASR models when tested in conversational settings. Furthermore, we observe a correlation between Word Error Rate and the presence of speech disfluencies, highlighting the critical need for more realistic, conversational ASR benchmarks.
Personalized Reinforcement Learning with a Budget of Policies
Jan 12, 2024Personalization in machine learning (ML) tailors models' decisions to the individual characteristics of users. While this approach has seen success in areas like recommender systems, its expansion into high-stakes fields such as healthcare and autonomous driving is hindered by the extensive regulatory approval processes involved. To address this challenge, we propose a novel framework termed represented Markov Decision Processes (r-MDPs) that is designed to balance the need for personalization with the regulatory constraints. In an r-MDP, we cater to a diverse user population, each with unique preferences, through interaction with a small set of representative policies. Our objective is twofold: efficiently match each user to an appropriate representative policy and simultaneously optimize these policies to maximize overall social welfare. We develop two deep reinforcement learning algorithms that efficiently solve r-MDPs. These algorithms draw inspiration from the principles of classic K-means clustering and are underpinned by robust theoretical foundations. Our empirical investigations, conducted across a variety of simulated environments, showcase the algorithms' ability to facilitate meaningful personalization even under constrained policy budgets. Furthermore, they demonstrate scalability, efficiently adapting to larger policy budgets.
Deep Contract Design via Discontinuous Piecewise Affine Neural Networks
Jul 05, 2023Contract design involves a principal who establishes contractual agreements about payments for outcomes that arise from the actions of an agent. In this paper, we initiate the study of deep learning for the automated design of optimal contracts. We formulate this as an offline learning problem, where a deep network is used to represent the principal's expected utility as a function of the design of a contract. We introduce a novel representation: the Discontinuous ReLU (DeLU) network, which models the principal's utility as a discontinuous piecewise affine function where each piece corresponds to the agent taking a particular action. DeLU networks implicitly learn closed-form expressions for the incentive compatibility constraints of the agent and the utility maximization objective of the principal, and support parallel inference on each piece through linear programming or interior-point methods that solve for optimal contracts. We provide empirical results that demonstrate success in approximating the principal's utility function with a small number of training samples and scaling to find approximately optimal contracts on problems with a large number of actions and outcomes.
Mediated Multi-Agent Reinforcement Learning
Jun 14, 2023The majority of Multi-Agent Reinforcement Learning (MARL) literature equates the cooperation of self-interested agents in mixed environments to the problem of social welfare maximization, allowing agents to arbitrarily share rewards and private information. This results in agents that forgo their individual goals in favour of social good, which can potentially be exploited by selfish defectors. We argue that cooperation also requires agents' identities and boundaries to be respected by making sure that the emergent behaviour is an equilibrium, i.e., a convention that no agent can deviate from and receive higher individual payoffs. Inspired by advances in mechanism design, we propose to solve the problem of cooperation, defined as finding socially beneficial equilibrium, by using mediators. A mediator is a benevolent entity that may act on behalf of agents, but only for the agents that agree to it. We show how a mediator can be trained alongside agents with policy gradient to maximize social welfare subject to constraints that encourage agents to cooperate through the mediator. Our experiments in matrix and iterative games highlight the potential power of applying mediators in MARL.
Neuromorphic Artificial Intelligence Systems
May 25, 2022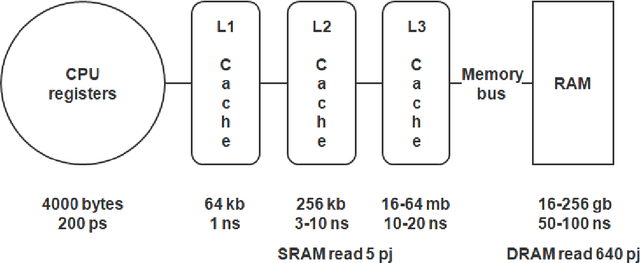
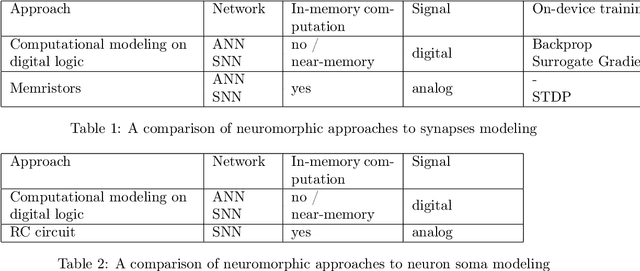
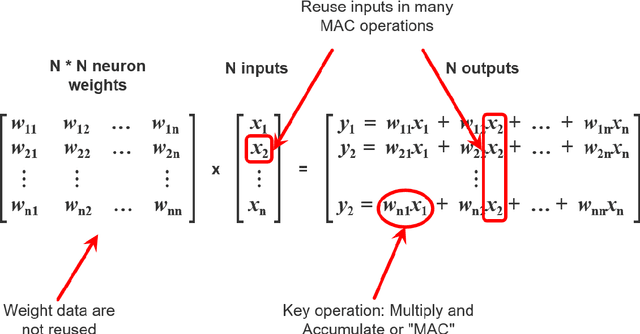
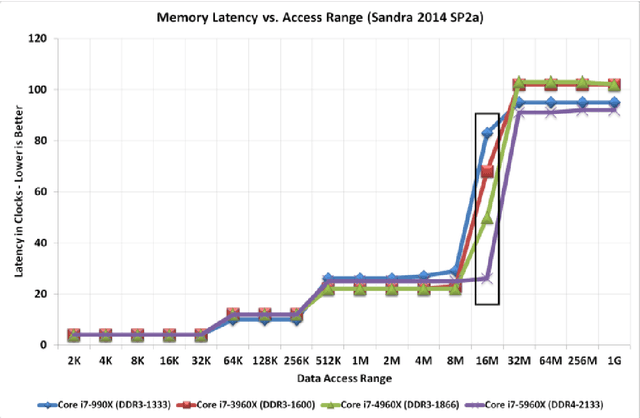
Modern AI systems, based on von Neumann architecture and classical neural networks, have a number of fundamental limitations in comparison with the brain. This article discusses such limitations and the ways they can be mitigated. Next, it presents an overview of currently available neuromorphic AI projects in which these limitations are overcame by bringing some brain features into the functioning and organization of computing systems (TrueNorth, Loihi, Tianjic, SpiNNaker, BrainScaleS, NeuronFlow, DYNAP, Akida). Also, the article presents the principle of classifying neuromorphic AI systems by the brain features they use (neural networks, parallelism and asynchrony, impulse nature of information transfer, local learning, sparsity, analog and in-memory computing). In addition to new architectural approaches used in neuromorphic devices based on existing silicon microelectronics technologies, the article also discusses the prospects of using new memristor element base. Examples of recent advances in the use of memristors in euromorphic applications are also given.
Self-Imitation Learning from Demonstrations
Mar 21, 2022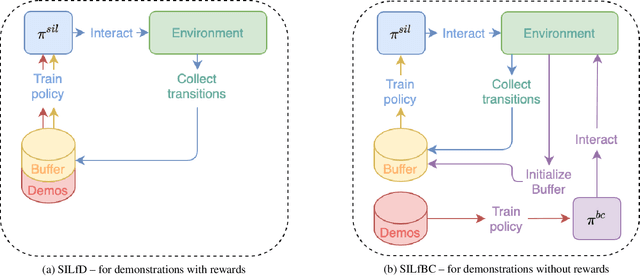
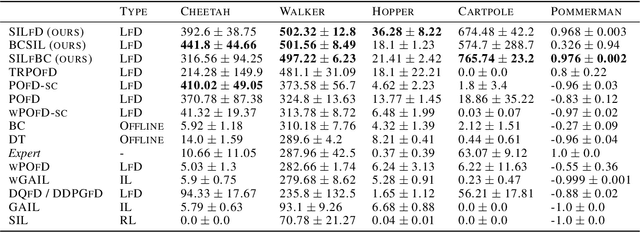
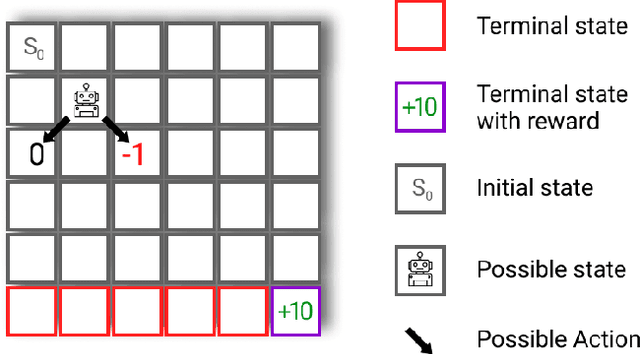
Despite the numerous breakthroughs achieved with Reinforcement Learning (RL), solving environments with sparse rewards remains a challenging task that requires sophisticated exploration. Learning from Demonstrations (LfD) remedies this issue by guiding the agent's exploration towards states experienced by an expert. Naturally, the benefits of this approach hinge on the quality of demonstrations, which are rarely optimal in realistic scenarios. Modern LfD algorithms require meticulous tuning of hyperparameters that control the influence of demonstrations and, as we show in the paper, struggle with learning from suboptimal demonstrations. To address these issues, we extend Self-Imitation Learning (SIL), a recent RL algorithm that exploits the agent's past good experience, to the LfD setup by initializing its replay buffer with demonstrations. We denote our algorithm as SIL from Demonstrations (SILfD). We empirically show that SILfD can learn from demonstrations that are noisy or far from optimal and can automatically adjust the influence of demonstrations throughout the training without additional hyperparameters or handcrafted schedules. We also find SILfD superior to the existing state-of-the-art LfD algorithms in sparse environments, especially when demonstrations are highly suboptimal.
Improving State-of-the-Art in One-Class Classification by Leveraging Unlabeled Data
Mar 14, 2022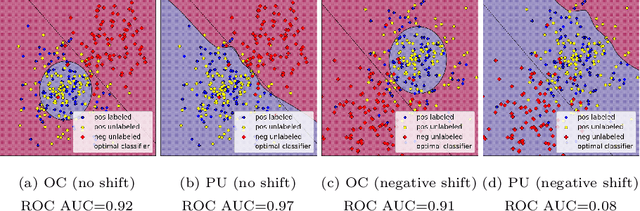
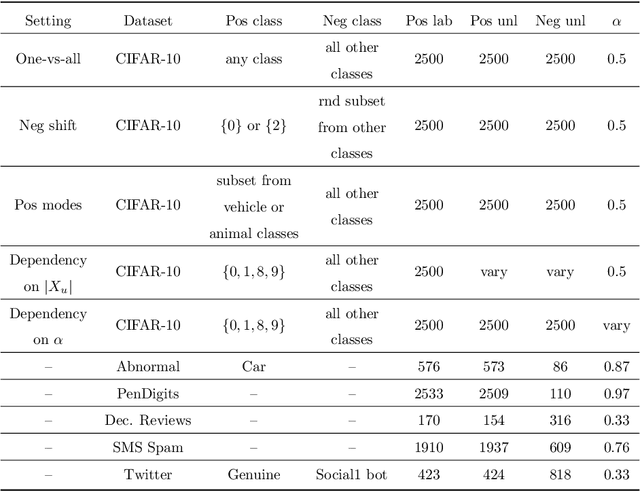
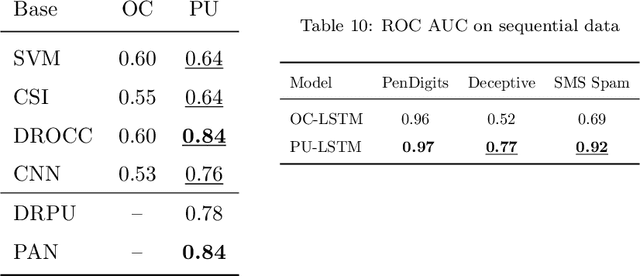
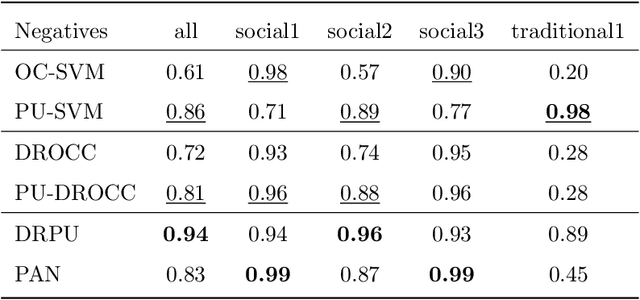
When dealing with binary classification of data with only one labeled class data scientists employ two main approaches, namely One-Class (OC) classification and Positive Unlabeled (PU) learning. The former only learns from labeled positive data, whereas the latter also utilizes unlabeled data to improve the overall performance. Since PU learning utilizes more data, we might be prone to think that when unlabeled data is available, the go-to algorithms should always come from the PU group. However, we find that this is not always the case if unlabeled data is unreliable, i.e. contains limited or biased latent negative data. We perform an extensive experimental study of a wide list of state-of-the-art OC and PU algorithms in various scenarios as far as unlabeled data reliability is concerned. Furthermore, we propose PU modifications of state-of-the-art OC algorithms that are robust to unreliable unlabeled data, as well as a guideline to similarly modify other OC algorithms. Our main practical recommendation is to use state-of-the-art PU algorithms when unlabeled data is reliable and to use the proposed modifications of state-of-the-art OC algorithms otherwise. Additionally, we outline procedures to distinguish the cases of reliable and unreliable unlabeled data using statistical tests.
Optimal-er Auctions through Attention
Feb 26, 2022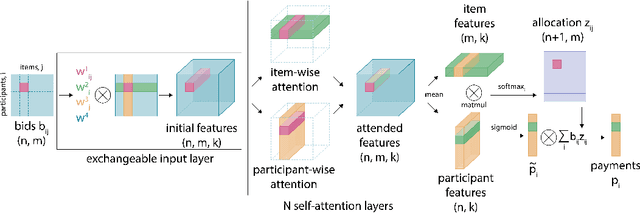
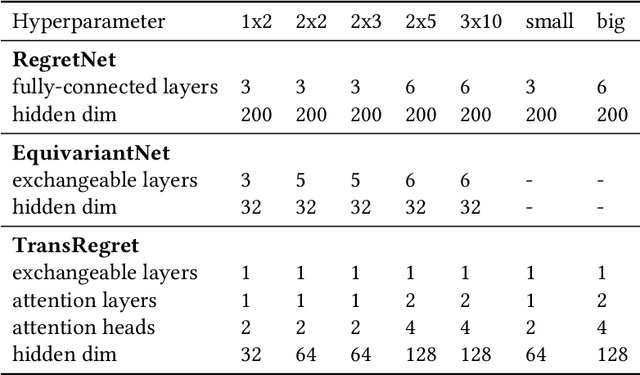
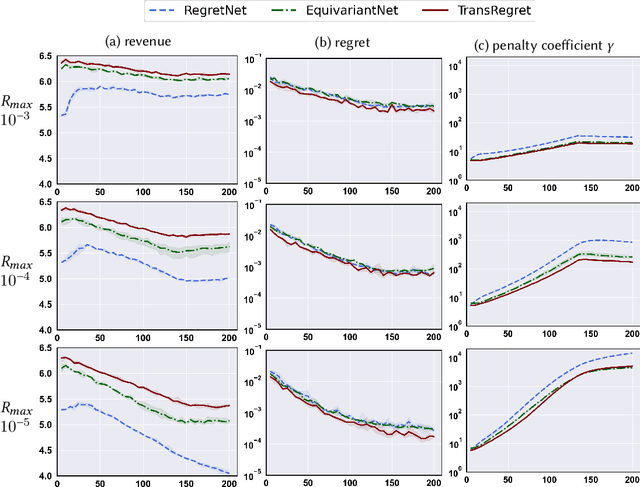
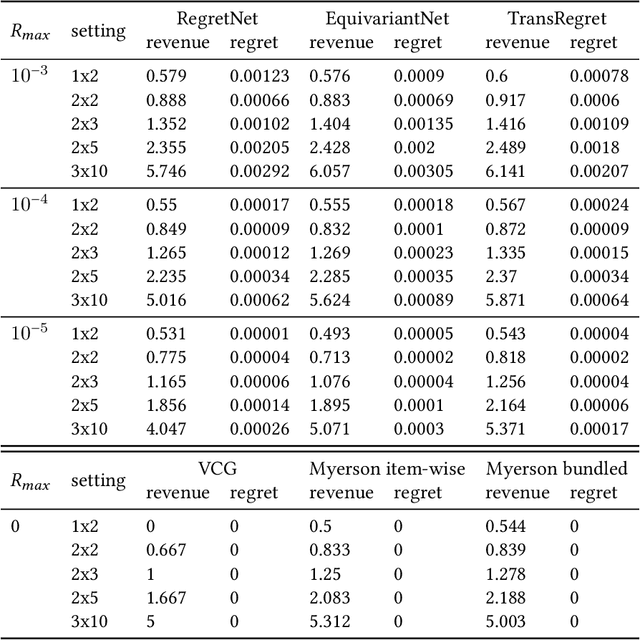
RegretNet is a recent breakthrough in the automated design of revenue-maximizing auctions. It combines the expressivity of deep learning with the regret-based approach to relax and quantify the Incentive Compatibility constraint (that participants benefit from bidding truthfully). As a follow-up to its success, we propose two independent modifications of RegretNet, namely a new neural architecture based on the attention mechanism, denoted as TransRegret, and an alternative loss function that is interpretable and significantly less sensitive to hyperparameters. We investigate both proposed modifications in an extensive experimental study in settings with fixed and varied input sizes and additionally test out-of-setting generalization of our network. In all experiments, we find that TransRegret consistently outperforms existing architectures in revenue. Regarding our loss modification, we confirm its effectiveness at controlling the revenue-regret trade-off by varying a single interpretable hyperparameter.
Neural Network Optimization for Reinforcement Learning Tasks Using Sparse Computations
Jan 07, 2022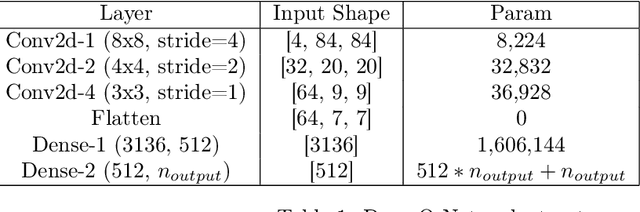
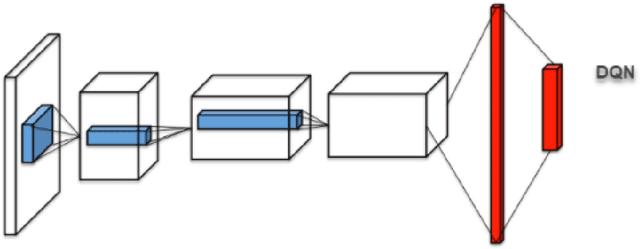


This article proposes a sparse computation-based method for optimizing neural networks for reinforcement learning (RL) tasks. This method combines two ideas: neural network pruning and taking into account input data correlations; it makes it possible to update neuron states only when changes in them exceed a certain threshold. It significantly reduces the number of multiplications when running neural networks. We tested different RL tasks and achieved 20-150x reduction in the number of multiplications. There were no substantial performance losses; sometimes the performance even improved.