 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Agent Model-Based Reinforcement Learning
May 25, 2022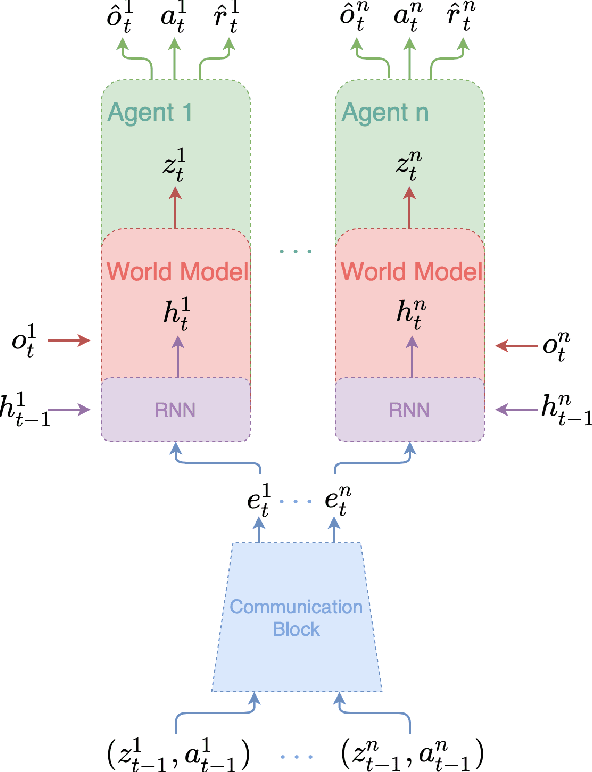
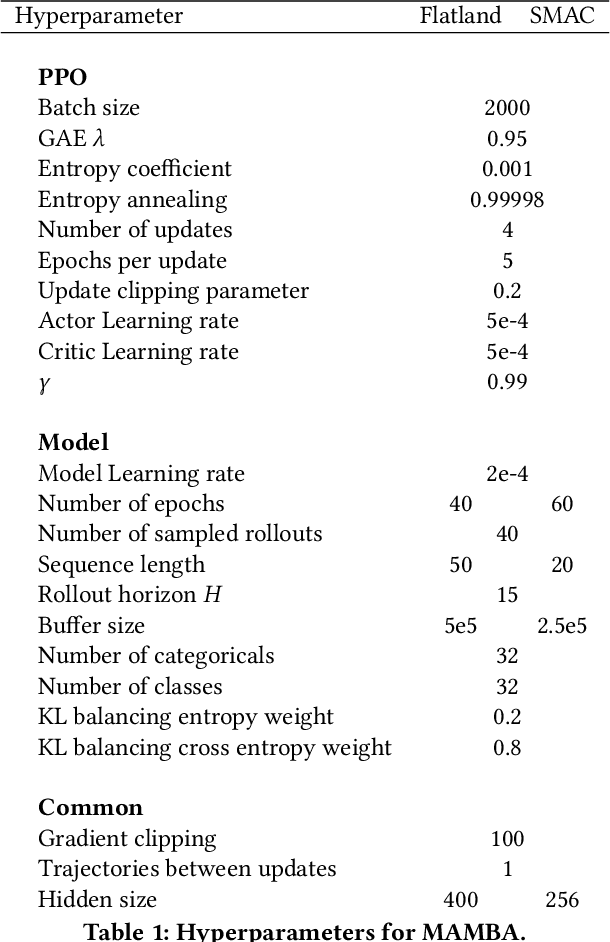
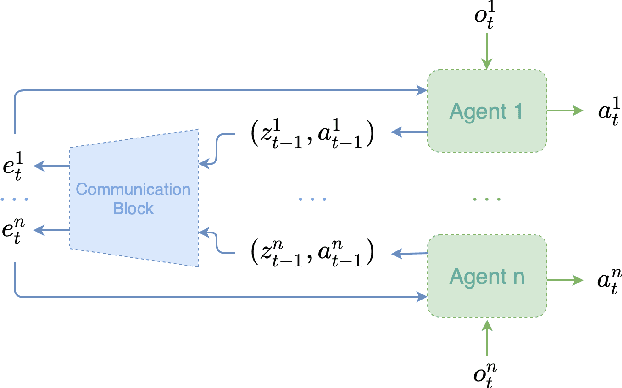
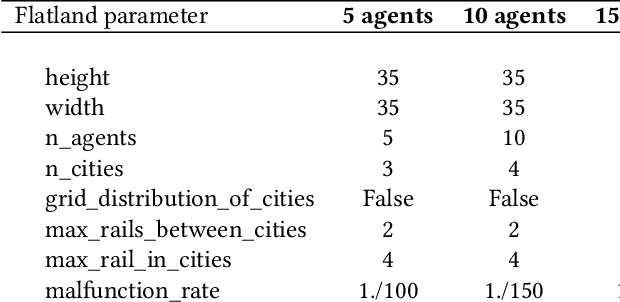
Recent Multi-Agent Reinforcement Learning (MARL) literature has been largely focused on Centralized Training with Decentralized Execution (CTDE) paradigm. CTDE has been a dominant approach for both cooperative and mixed environments due to its capability to efficiently train decentralized policies. While in mixed environments full autonomy of the agents can be a desirable outcome, cooperative environments allow agents to share information to facilitate coordination. Approaches that leverage this technique are usually referred as communication methods, as full autonomy of agents is compromised for better performance. Although communication approaches have shown impressive results, they do not fully leverage this additional information during training phase. In this paper, we propose a new method called MAMBA which utilizes Model-Based Reinforcement Learning (MBRL) to further leverage centralized training in cooperative environments. We argue that communication between agents is enough to sustain a world model for each agent during execution phase while imaginary rollouts can be used for training, removing the necessity to interact with the environment. These properties yield sample efficient algorithm that can scale gracefully with the number of agents. We empirically confirm that MAMBA achieves good performance while reducing the number of interactions with the environment up to an orders of magnitude compared to Model-Free state-of-the-art approaches in challenging domains of SMAC and Flatland.
Self-Imitation Learning from Demonstrations
Mar 21, 2022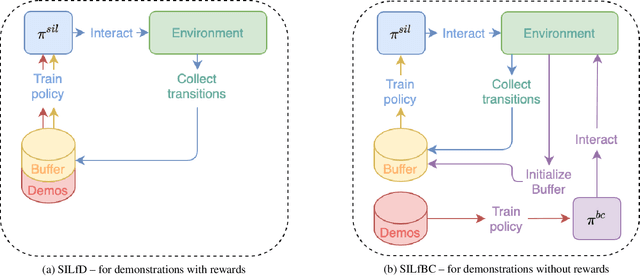
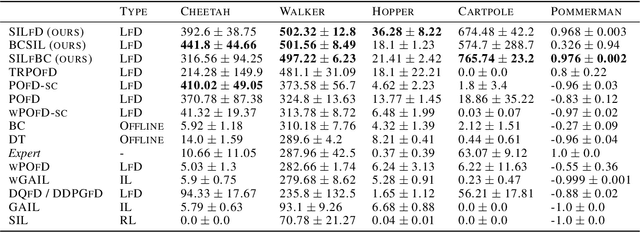
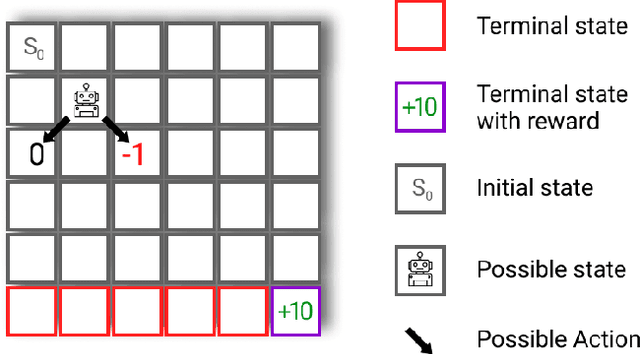
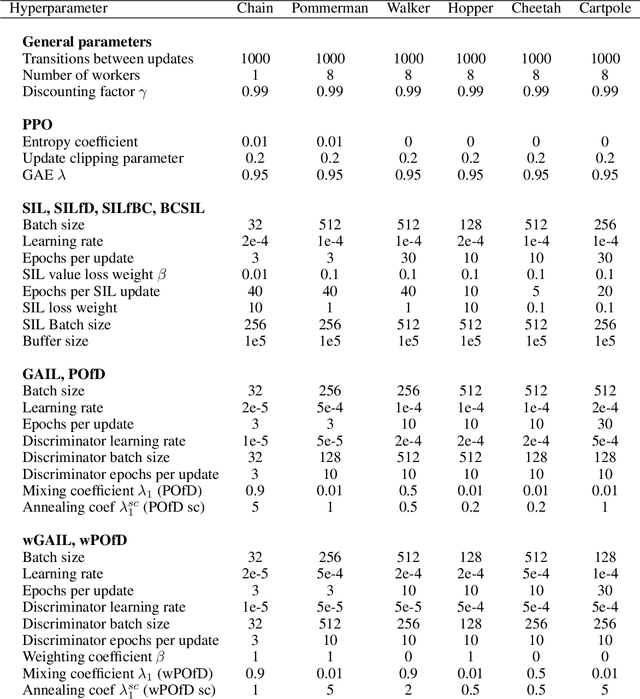
Despite the numerous breakthroughs achieved with Reinforcement Learning (RL), solving environments with sparse rewards remains a challenging task that requires sophisticated exploration. Learning from Demonstrations (LfD) remedies this issue by guiding the agent's exploration towards states experienced by an expert. Naturally, the benefits of this approach hinge on the quality of demonstrations, which are rarely optimal in realistic scenarios. Modern LfD algorithms require meticulous tuning of hyperparameters that control the influence of demonstrations and, as we show in the paper, struggle with learning from suboptimal demonstrations. To address these issues, we extend Self-Imitation Learning (SIL), a recent RL algorithm that exploits the agent's past good experience, to the LfD setup by initializing its replay buffer with demonstrations. We denote our algorithm as SIL from Demonstrations (SILfD). We empirically show that SILfD can learn from demonstrations that are noisy or far from optimal and can automatically adjust the influence of demonstrations throughout the training without additional hyperparameters or handcrafted schedules. We also find SILfD superior to the existing state-of-the-art LfD algorithms in sparse environments, especially when demonstrations are highly suboptimal.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021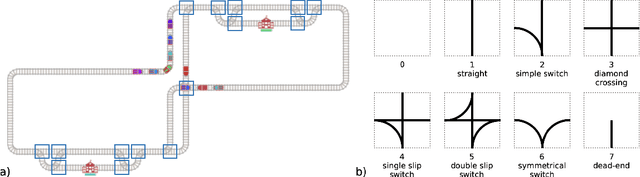
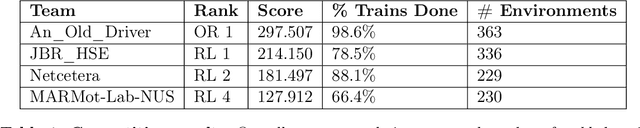
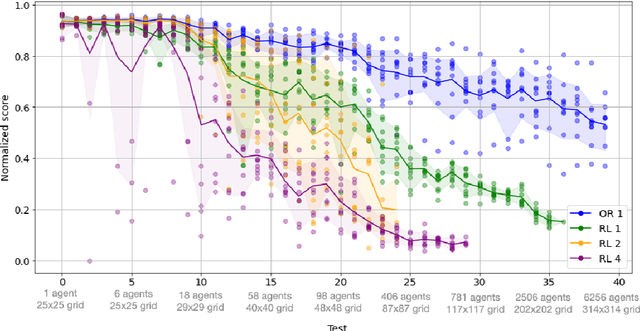
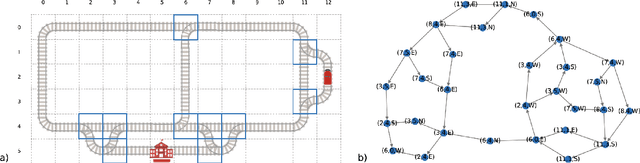
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Balancing Rational and Other-Regarding Preferences in Cooperative-Competitive Environments
Feb 24, 2021

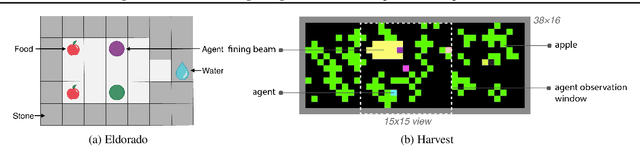

Recent reinforcement learning studies extensively explore the interplay between cooperative and competitive behaviour in mixed environments. Unlike cooperative environments where agents strive towards a common goal, mixed environments are notorious for the conflicts of selfish and social interests. As a consequence, purely rational agents often struggle to achieve and maintain cooperation. A prevalent approach to induce cooperative behaviour is to assign additional rewards based on other agents' well-being. However, this approach suffers from the issue of multi-agent credit assignment, which can hinder performance. This issue is efficiently alleviated in cooperative setting with such state-of-the-art algorithms as QMIX and COMA. Still, when applied to mixed environments, these algorithms may result in unfair allocation of rewards. We propose BAROCCO, an extension of these algorithms capable to balance individual and social incentives. The mechanism behind BAROCCO is to train two distinct but interwoven components that jointly affect each agent's decisions. Our meta-algorithm is compatible with both Q-learning and Actor-Critic frameworks. We experimentally confirm the advantages over the existing methods and explore the behavioural aspects of BAROCCO in two mixed multi-agent setups.