 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023



We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
2nd Swiss German Speech to Standard German Text Shared Task at SwissText 2022
Jan 17, 2023
We present the results and findings of the 2nd Swiss German speech to Standard German text shared task at SwissText 2022. Participants were asked to build a sentence-level Swiss German speech to Standard German text system specialized on the Grisons dialect. The objective was to maximize the BLEU score on a test set of Grisons speech. 3 teams participated, with the best-performing system achieving a BLEU score of 70.1.
Swiss German Speech to Text system evaluation
Jul 01, 2022We present an in-depth evaluation of four commercially available Speech-to-Text (STT) systems for Swiss German. The systems are anonymized and referred to as system a-d in this report. We compare the four systems to our STT model, referred to as FHNW from hereon after, and provide details on how we trained our model. To evaluate the models, we use two STT datasets from different domains. The Swiss Parliament Corpus (SPC) test set and a private dataset in the news domain with an even distribution across seven dialect regions. We provide a detailed error analysis to detect the three systems' strengths and weaknesses. This analysis is limited by the characteristics of the two test sets. Our model scored the highest bilingual evaluation understudy (BLEU) on both datasets. On the SPC test set, we obtain a BLEU score of 0.607, whereas the best commercial system reaches a BLEU score of 0.509. On our private test set, we obtain a BLEU score of 0.722 and the best commercial system a BLEU score of 0.568.
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022
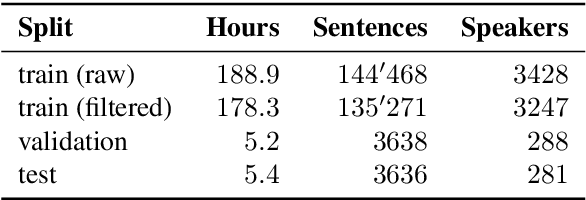
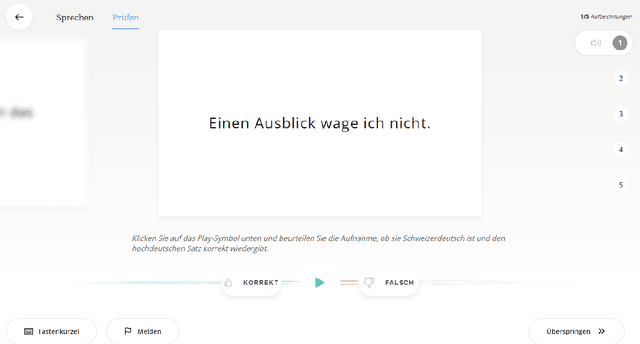
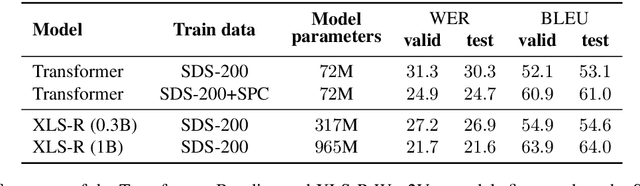
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
Distilling Reinforcement Learning Tricks for Video Games
Jul 01, 2021



Reinforcement learning (RL) research focuses on general solutions that can be applied across different domains. This results in methods that RL practitioners can use in almost any domain. However, recent studies often lack the engineering steps ("tricks") which may be needed to effectively use RL, such as reward shaping, curriculum learning, and splitting a large task into smaller chunks. Such tricks are common, if not necessary, to achieve state-of-the-art results and win RL competitions. To ease the engineering efforts, we distill descriptions of tricks from state-of-the-art results and study how well these tricks can improve a standard deep Q-learning agent. The long-term goal of this work is to enable combining proven RL methods with domain-specific tricks by providing a unified software framework and accompanying insights in multiple domains.
Towards robust and domain agnostic reinforcement learning competitions
Jun 07, 2021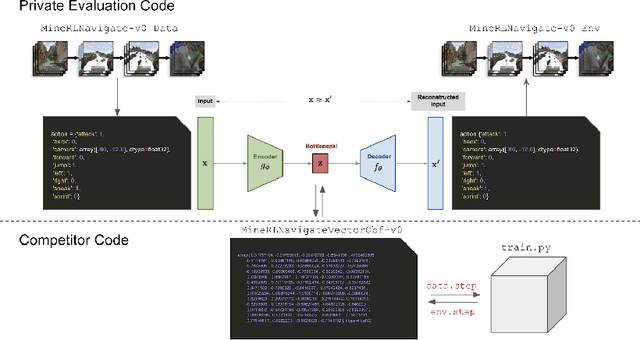

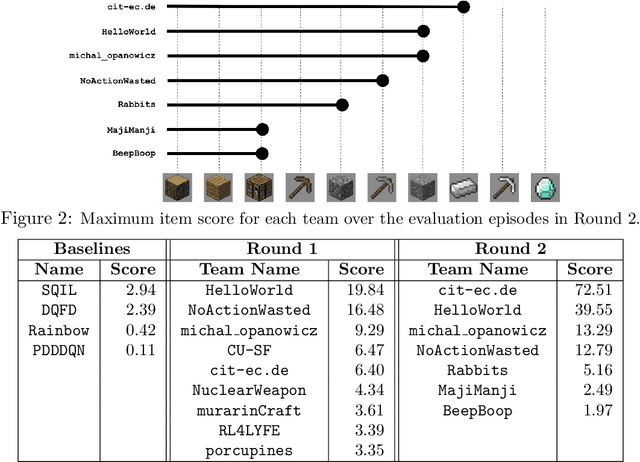
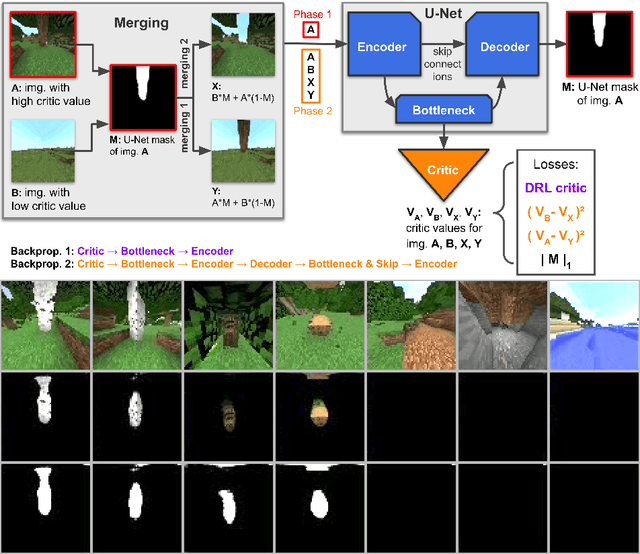
Reinforcement learning competitions have formed the basis for standard research benchmarks, galvanized advances in the state-of-the-art, and shaped the direction of the field. Despite this, a majority of challenges suffer from the same fundamental problems: participant solutions to the posed challenge are usually domain-specific, biased to maximally exploit compute resources, and not guaranteed to be reproducible. In this paper, we present a new framework of competition design that promotes the development of algorithms that overcome these barriers. We propose four central mechanisms for achieving this end: submission retraining, domain randomization, desemantization through domain obfuscation, and the limitation of competition compute and environment-sample budget. To demonstrate the efficacy of this design, we proposed, organized, and ran the MineRL 2020 Competition on Sample-Efficient Reinforcement Learning. In this work, we describe the organizational outcomes of the competition and show that the resulting participant submissions are reproducible, non-specific to the competition environment, and sample/resource efficient, despite the difficult competition task.
Flatland Competition 2020: MAPF and MARL for Efficient Train Coordination on a Grid World
Mar 30, 2021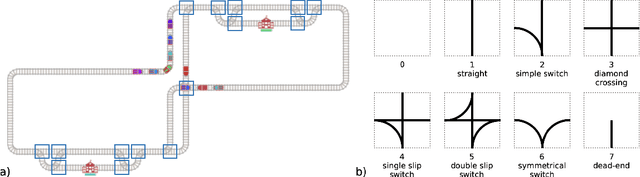
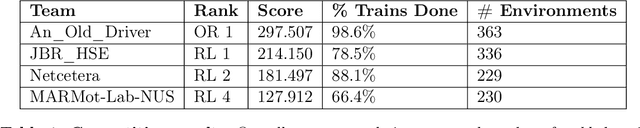
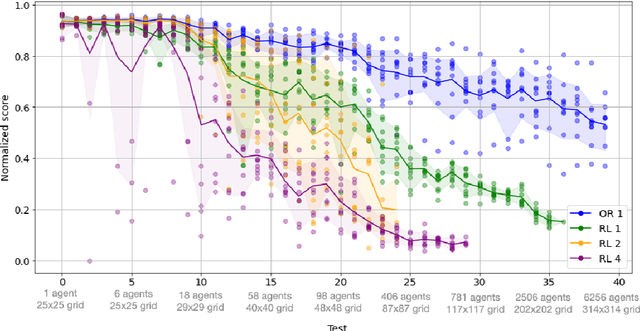
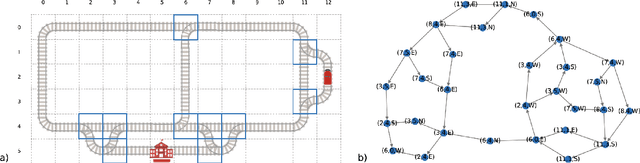
The Flatland competition aimed at finding novel approaches to solve the vehicle re-scheduling problem (VRSP). The VRSP is concerned with scheduling trips in traffic networks and the re-scheduling of vehicles when disruptions occur, for example the breakdown of a vehicle. While solving the VRSP in various settings has been an active area in operations research (OR) for decades, the ever-growing complexity of modern railway networks makes dynamic real-time scheduling of traffic virtually impossible. Recently, multi-agent reinforcement learning (MARL) has successfully tackled challenging tasks where many agents need to be coordinated, such as multiplayer video games. However, the coordination of hundreds of agents in a real-life setting like a railway network remains challenging and the Flatland environment used for the competition models these real-world properties in a simplified manner. Submissions had to bring as many trains (agents) to their target stations in as little time as possible. While the best submissions were in the OR category, participants found many promising MARL approaches. Using both centralized and decentralized learning based approaches, top submissions used graph representations of the environment to construct tree-based observations. Further, different coordination mechanisms were implemented, such as communication and prioritization between agents. This paper presents the competition setup, four outstanding solutions to the competition, and a cross-comparison between them.
Flatland-RL : Multi-Agent Reinforcement Learning on Trains
Dec 11, 2020

Efficient automated scheduling of trains remains a major challenge for modern railway systems. The underlying vehicle rescheduling problem (VRSP) has been a major focus of Operations Research (OR) since decades. Traditional approaches use complex simulators to study VRSP, where experimenting with a broad range of novel ideas is time consuming and has a huge computational overhead. In this paper, we introduce a two-dimensional simplified grid environment called "Flatland" that allows for faster experimentation. Flatland does not only reduce the complexity of the full physical simulation, but also provides an easy-to-use interface to test novel approaches for the VRSP, such as Reinforcement Learning (RL) and Imitation Learning (IL). In order to probe the potential of Machine Learning (ML) research on Flatland, we (1) ran a first series of RL and IL experiments and (2) design and executed a public Benchmark at NeurIPS 2020 to engage a large community of researchers to work on this problem. Our own experimental results, on the one hand, demonstrate that ML has potential in solving the VRSP on Flatland. On the other hand, we identify key topics that need further research. Overall, the Flatland environment has proven to be a robust and valuable framework to investigate the VRSP for railway networks. Our experiments provide a good starting point for further research and for the participants of the NeurIPS 2020 Flatland Benchmark. All of these efforts together have the potential to have a substantial impact on shaping the mobility of the future.
Action Space Shaping in Deep Reinforcement Learning
Apr 02, 2020

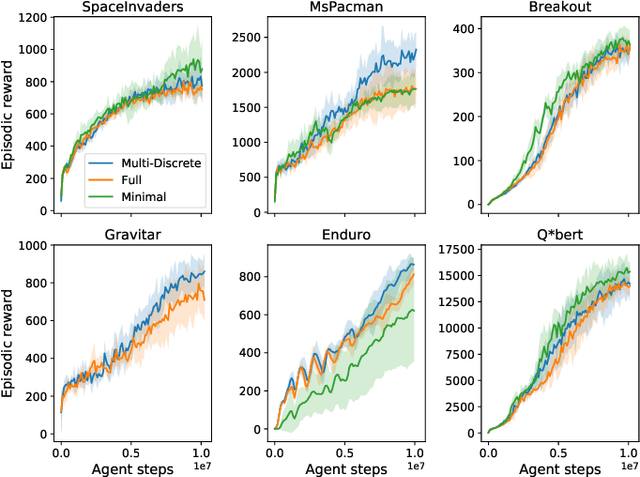
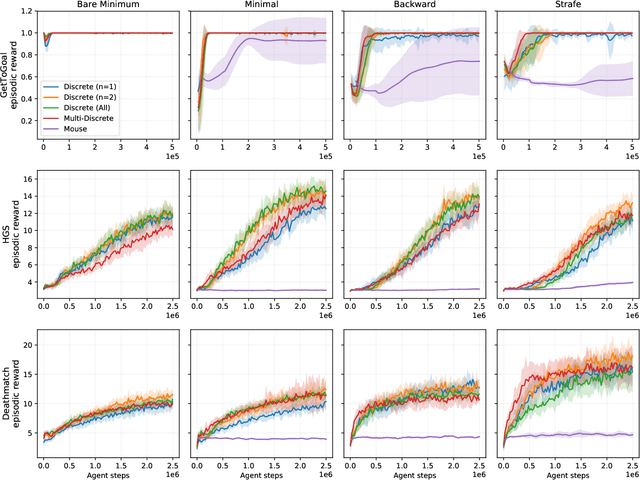
Reinforcement learning (RL) has been successful in training agents in various learning environments, including video-games. However, such work modifies and shrinks the action space from the game's original. This is to avoid trying "pointless" actions and to ease the implementation. Currently, this is mostly done based on intuition, with little systematic research supporting the design decisions. In this work, we aim to gain insight on these action space modifications by conducting extensive experiments in video-game environments. Our results show how domain-specific removal of actions and discretization of continuous actions can be crucial for successful learning. With these insights, we hope to ease the use of RL in new environments, by clarifying what action-spaces are easy to learn.
Sample Efficient Reinforcement Learning through Learning from Demonstrations in Minecraft
Mar 12, 2020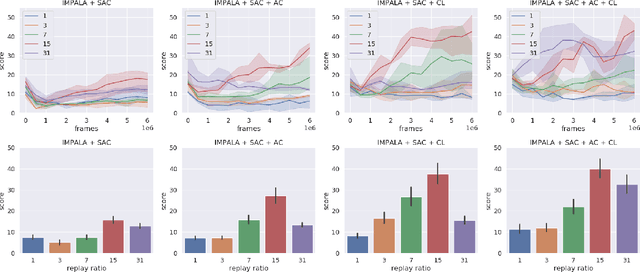

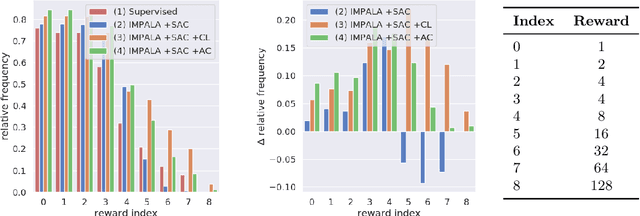
Sample inefficiency of deep reinforcement learning methods is a major obstacle for their use in real-world applications. In this work, we show how human demonstrations can improve final performance of agents on the Minecraft minigame ObtainDiamond with only 8M frames of environment interaction. We propose a training procedure where policy networks are first trained on human data and later fine-tuned by reinforcement learning. Using a policy exploitation mechanism, experience replay and an additional loss against catastrophic forgetting, our best agent was able to achieve a mean score of 48. Our proposed solution placed 3rd in the NeurIPS MineRL Competition for Sample-Efficient Reinforcement Learning.