 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTT4SG-350: A Speech Corpus for All Swiss German Dialect Regions
May 30, 2023



We present STT4SG-350 (Speech-to-Text for Swiss German), a corpus of Swiss German speech, annotated with Standard German text at the sentence level. The data is collected using a web app in which the speakers are shown Standard German sentences, which they translate to Swiss German and record. We make the corpus publicly available. It contains 343 hours of speech from all dialect regions and is the largest public speech corpus for Swiss German to date. Application areas include automatic speech recognition (ASR), text-to-speech, dialect identification, and speaker recognition. Dialect information, age group, and gender of the 316 speakers are provided. Genders are equally represented and the corpus includes speakers of all ages. Roughly the same amount of speech is provided per dialect region, which makes the corpus ideally suited for experiments with speech technology for different dialects. We provide training, validation, and test splits of the data. The test set consists of the same spoken sentences for each dialect region and allows a fair evaluation of the quality of speech technologies in different dialects. We train an ASR model on the training set and achieve an average BLEU score of 74.7 on the test set. The model beats the best published BLEU scores on 2 other Swiss German ASR test sets, demonstrating the quality of the corpus.
A Swiss German Dictionary: Variation in Speech and Writing
Mar 31, 2020
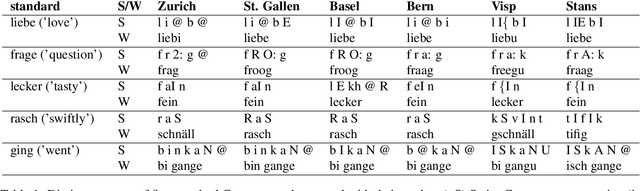

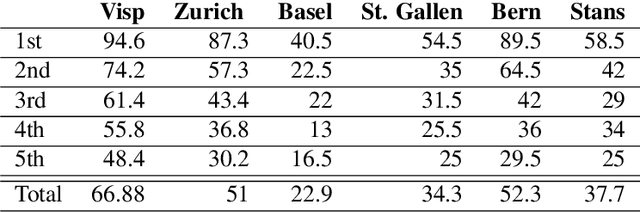
We introduce a dictionary containing forms of common words in various Swiss German dialects normalized into High German. As Swiss German is, for now, a predominantly spoken language, there is a significant variation in the written forms, even between speakers of the same dialect. To alleviate the uncertainty associated with this diversity, we complement the pairs of Swiss German - High German words with the Swiss German phonetic transcriptions (SAMPA). This dictionary becomes thus the first resource to combine large-scale spontaneous translation with phonetic transcriptions. Moreover, we control for the regional distribution and insure the equal representation of the major Swiss dialects. The coupling of the phonetic and written Swiss German forms is powerful. We show that they are sufficient to train a Transformer-based phoneme to grapheme model that generates credible novel Swiss German writings. In addition, we show that the inverse mapping - from graphemes to phonemes - can be modeled with a transformer trained with the novel dictionary. This generation of pronunciations for previously unknown words is key in training extensible automated speech recognition (ASR) systems, which are key beneficiaries of this dictionary.
Multilevel Text Normalization with Sequence-to-Sequence Networks and Multisource Learning
Mar 29, 2019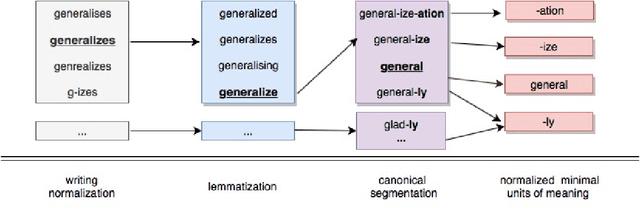
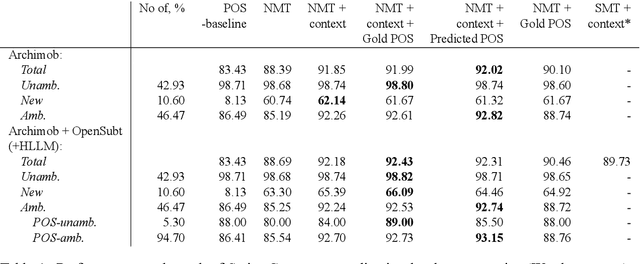
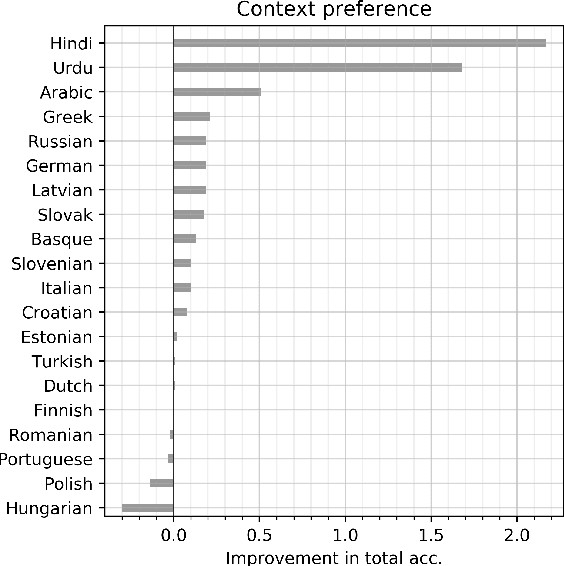
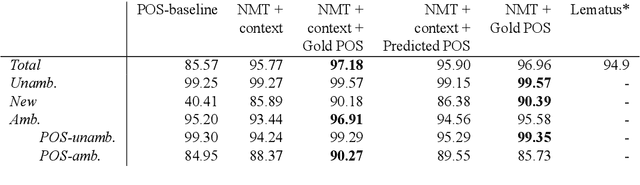
We define multilevel text normalization as sequence-to-sequence processing that transforms naturally noisy text into a sequence of normalized units of meaning (morphemes) in three steps: 1) writing normalization, 2) lemmatization, 3) canonical segmentation. These steps are traditionally considered separate NLP tasks, with diverse solutions, evaluation schemes and data sources. We exploit the fact that all these tasks involve sub-word sequence-to-sequence transformation to propose a systematic solution for all of them using neural encoder-decoder technology. The specific challenge that we tackle in this paper is integrating the traditional know-how on separate tasks into the neural sequence-to-sequence framework to improve the state of the art. We address this challenge by enriching the general framework with mechanisms that allow processing the information on multiple levels of text organization (characters, morphemes, words, sentences) in combination with structural information (multilevel language model, part-of-speech) and heterogeneous sources (text, dictionaries). We show that our solution consistently improves on the current methods in all three steps. In addition, we analyze the performance of our system to show the specific contribution of the integrating components to the overall improvement.